Semantic Soft Bootstrapping: Long Context Reasoning in LLMs without Reinforcement Learning
作者: Purbesh Mitra, Sennur Ulukus
分类: cs.CL, cs.AI, cs.IT, cs.LG, eess.SP
发布日期: 2025-12-04
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出语义软引导(SSB)方法,无需强化学习即可提升LLM长文本推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本推理 自蒸馏 语义软引导 大型语言模型 数学问题求解
📋 核心要点
- 现有LLM推理训练依赖强化学习,存在奖励稀疏、样本效率低等问题,导致计算资源消耗大。
- 提出语义软引导(SSB)自蒸馏方法,利用模型自身生成数据,构建师生训练集,无需人工干预。
- 实验表明,SSB在MATH500和AIME2024基准测试中,相比GRPO算法,准确率分别提升了10.6%和10%。
📝 摘要(中文)
大型语言模型(LLM)中的长文本推理能力已通过思维链(CoT)推理得到增强,从而提升了其认知能力。通常,此类模型的训练通过强化学习与可验证奖励(RLVR)完成,尤其是在数学和编程等基于推理的问题中。然而,RLVR受到多个瓶颈的限制,例如缺乏密集奖励和样本效率不足。因此,它需要在后训练阶段消耗大量的计算资源。为了克服这些限制,本文提出了一种名为 extbf{语义软引导(SSB)}的自蒸馏技术,其中同一个基础语言模型扮演教师和学生的角色,但在训练时接收关于其结果正确性的不同语义上下文。该模型首先被提示一个数学问题,并生成多个rollout。从中筛选出正确和最常见的错误答案,然后在上下文中提供给模型,以产生更稳健的、带有验证最终答案的逐步解释。该流程自动从原始问题-答案数据中生成配对的师生训练集,无需任何人工干预。此生成过程还会产生一系列logits,学生模型在训练阶段尝试仅从裸问题匹配这些logits。在我们的实验中,我们使用Qwen2.5-3B-Instruct在GSM8K数据集上通过参数高效微调进行了实验。然后,我们在MATH500和AIME2024基准测试中测试了其准确性。我们的实验表明,与常用的RLVR算法group relative policy optimization(GRPO)相比,准确率分别提高了10.6%和10%。我们的代码可在https://github.com/purbeshmitra/semantic-soft-bootstrapping 获得,模型和整理的数据集可在https://huggingface.co/purbeshmitra/semantic-soft-bootstrapping 获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本推理任务中,依赖强化学习进行训练时所面临的挑战,包括奖励信号稀疏、样本效率低下以及计算资源消耗过大的问题。现有方法,如基于强化学习的训练方式,难以有效地引导模型学习复杂的推理过程,尤其是在缺乏密集奖励的情况下,模型难以收敛到最优解。
核心思路:论文的核心思路是利用自蒸馏技术,通过让同一个模型扮演教师和学生的角色,构建一个无需人工干预的训练流程。教师模型通过生成多个答案,并筛选出正确和常见的错误答案,为学生模型提供带有语义信息的上下文。学生模型则尝试模仿教师模型的输出logits,从而学习到更鲁棒的推理能力。这种方法避免了对外部奖励信号的依赖,提高了样本利用率。
技术框架:SSB的技术框架主要包含以下几个阶段:1) 问题生成阶段:给定一个数学问题,模型生成多个可能的答案(rollouts)。2) 答案筛选阶段:从生成的答案中筛选出正确答案和最常见的错误答案。3) 上下文构建阶段:将筛选出的答案作为上下文,提供给模型,要求其生成逐步的解释和验证的最终答案。4) 训练阶段:学生模型尝试匹配教师模型在上下文构建阶段生成的logits序列。整个流程无需人工干预,自动生成师生训练数据。
关键创新:SSB最重要的技术创新在于其自蒸馏的训练方式,它避免了对强化学习的依赖,从而克服了奖励稀疏和样本效率低下的问题。与传统的蒸馏方法不同,SSB利用模型自身生成的数据,并根据答案的正确性构建不同的语义上下文,从而更有效地引导学生模型学习推理能力。此外,该方法完全自动化,无需人工标注数据。
关键设计:在实验中,作者使用了Qwen2.5-3B-Instruct模型作为基础模型,并在GSM8K数据集上进行了参数高效微调。损失函数采用标准的交叉熵损失,用于衡量学生模型输出logits与教师模型logits之间的差异。在答案筛选阶段,作者采用了简单的频率统计方法,选择出现频率最高的答案作为最常见的错误答案。具体的超参数设置,如rollout的数量、训练轮数等,需要在实际应用中进行调整。
🖼️ 关键图片

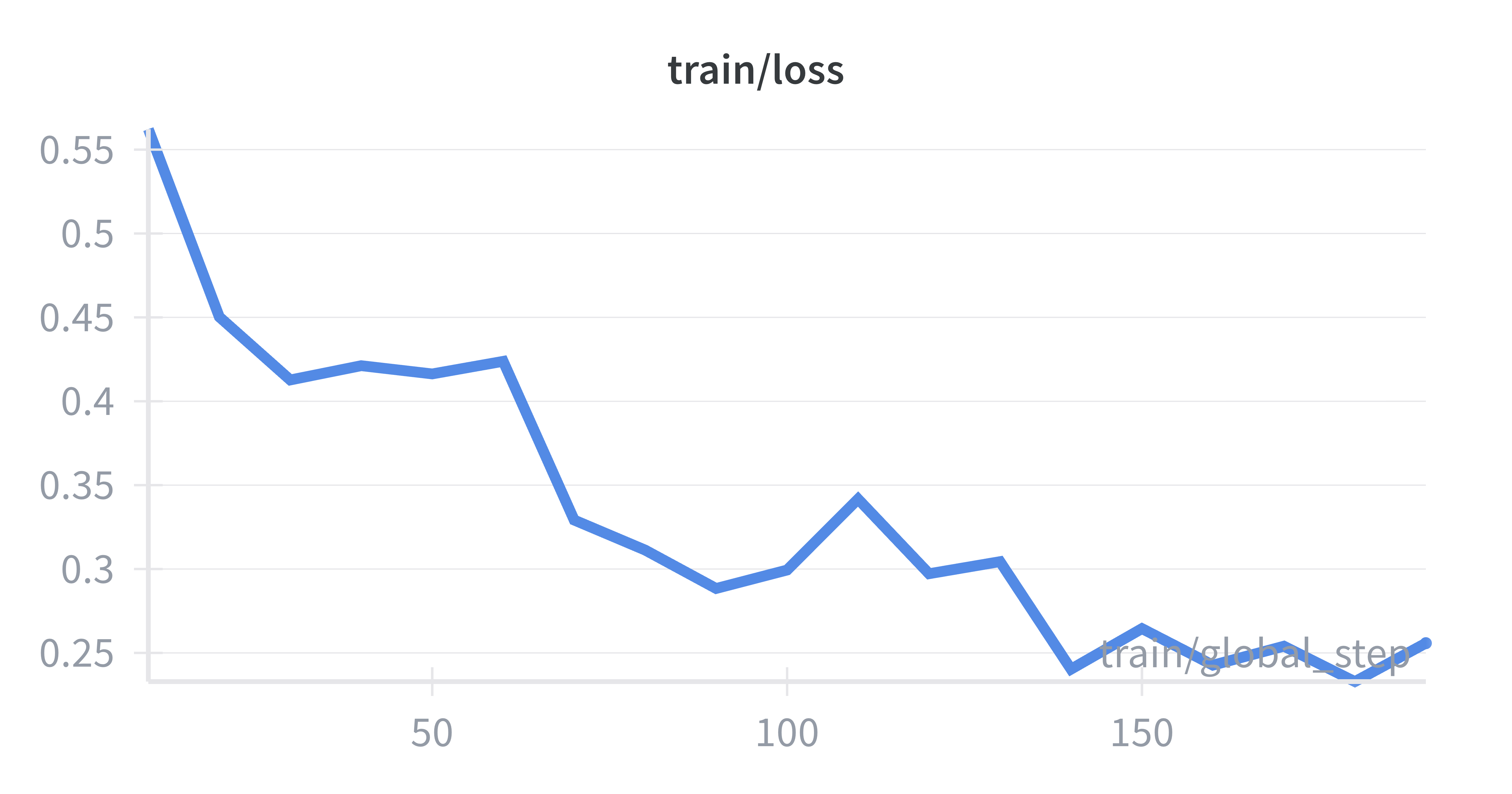
📊 实验亮点
实验结果表明,SSB方法在MATH500和AIME2024基准测试中,相比常用的强化学习算法GRPO,准确率分别提高了10.6%和10%。这表明SSB能够有效地提升LLM的长文本推理能力,并且在计算资源有限的情况下,也能取得显著的性能提升。
🎯 应用场景
该研究成果可应用于提升LLM在数学、编程等需要复杂推理能力的领域的性能。通过自蒸馏的方式,降低了模型训练对人工标注数据的依赖,并减少了对计算资源的需求。未来可扩展到其他需要长文本推理的任务,例如代码生成、文本摘要等。
📄 摘要(原文)
Long context reasoning in large language models (LLMs) has demonstrated enhancement of their cognitive capabilities via chain-of-thought (CoT) inference. Training such models is usually done via reinforcement learning with verifiable rewards (RLVR) in reasoning based problems, like math and programming. However, RLVR is limited by several bottlenecks, such as, lack of dense reward, and inadequate sample efficiency. As a result, it requires significant compute resources in post-training phase. To overcome these limitations, in this work, we propose \textbf{Semantic Soft Bootstrapping (SSB)}, a self-distillation technique, in which the same base language model plays the role of both teacher and student, but receives different semantic contexts about the correctness of its outcome at training time. The model is first prompted with a math problem and several rollouts are generated. From them, the correct and most common incorrect response are filtered, and then provided to the model in context to produce a more robust, step-by-step explanation with a verified final answer. This pipeline automatically curates a paired teacher-student training set from raw problem-answer data, without any human intervention. This generation process also produces a sequence of logits, which is what the student model tries to match in the training phase just from the bare question alone. In our experiment, Qwen2.5-3B-Instruct on GSM8K dataset via parameter-efficient fine-tuning. We then tested its accuracy on MATH500, and AIME2024 benchmarks. Our experiments show a jump of 10.6%, and 10% improvements in accuracy, respectively, over group relative policy optimization (GRPO), which is a commonly used RLVR algorithm. Our code is available at https://github.com/purbeshmitra/semantic-soft-bootstrapping, and the model, curated dataset is available at https://huggingface.co/purbeshmitra/semantic-soft-bootstrapping.