Structured Document Translation via Format Reinforcement Learning
作者: Haiyue Song, Johannes Eschbach-Dymanus, Hour Kaing, Sumire Honda, Hideki Tanaka, Bianka Buschbeck, Masao Utiyama
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-04
备注: IJCNLP-AACL 2025 Main (Oral)
💡 一句话要点
提出FormatRL,通过强化学习优化结构化文档翻译中的格式和语义。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 结构化文档翻译 强化学习 XML树 机器翻译 奖励函数
📋 核心要点
- 现有结构化文本翻译方法难以有效处理复杂的文档级XML/HTML结构。
- FormatRL通过强化学习直接优化结构感知奖励,提升翻译的结构和语义质量。
- 在SAP软件文档基准测试中,FormatRL在多个指标上均取得了显著的性能提升。
📝 摘要(中文)
现有的结构化文本翻译工作主要集中在句子层面,难以有效处理文档级别的复杂XML或HTML结构。为了解决这个问题,我们提出了格式强化学习(FormatRL),它在监督微调模型的基础上,采用Group Relative Policy Optimization,直接优化结构感知的奖励函数:1) TreeSim,用于衡量预测的XML树和参考XML树之间的结构相似性;2) Node-chrF,用于衡量XML节点级别的翻译质量。此外,我们应用StrucAUC,一种区分细微错误和重大结构性错误的细粒度指标。在SAP软件文档基准上的实验表明,该方法在六个指标上均有改进,分析进一步表明不同的奖励函数如何促进结构和翻译质量的提高。
🔬 方法详解
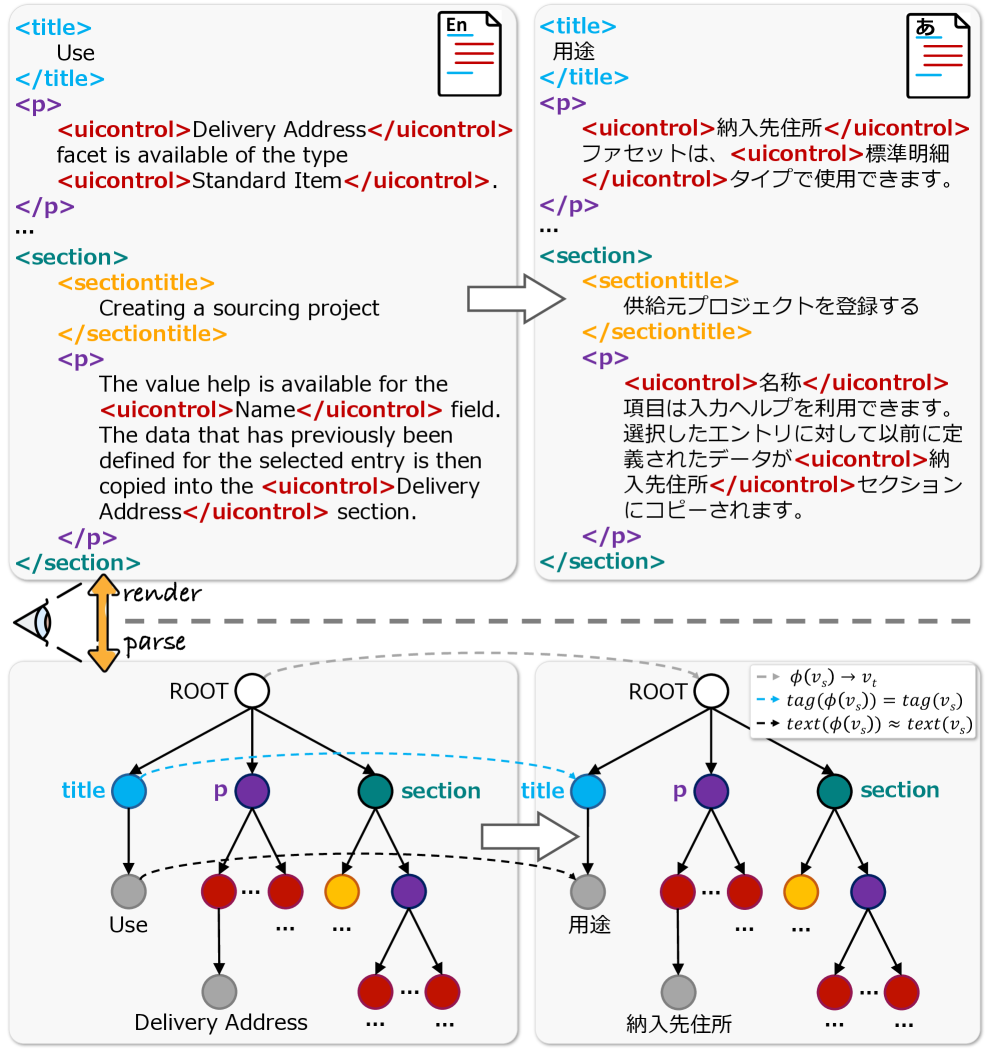
问题定义:论文旨在解决结构化文档翻译中,现有方法难以有效处理文档级别XML或HTML结构的问题。现有方法主要集中在句子层面,忽略了文档的整体结构信息,导致翻译后的文档结构与原文差异较大,影响可读性和可用性。
核心思路:论文的核心思路是利用强化学习直接优化翻译模型的结构感知能力。通过设计结构感知的奖励函数,引导模型学习生成结构更接近原文的翻译结果。这种方法避免了传统方法中结构信息处理的不足,能够更好地保留文档的整体结构。
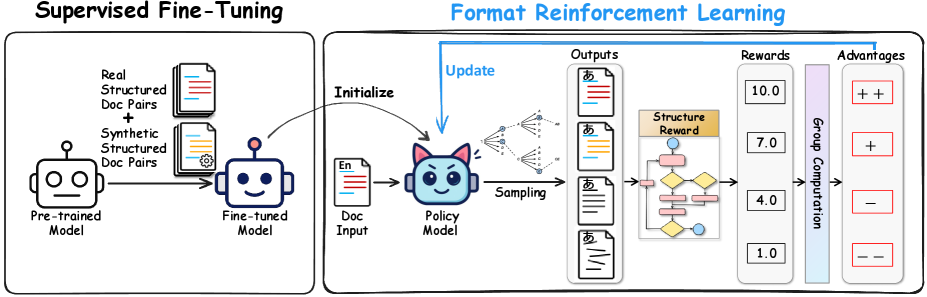
技术框架:FormatRL的技术框架主要包括以下几个部分:1) 监督微调模型:使用预训练的翻译模型在结构化文档翻译数据集上进行微调,作为强化学习的初始策略。2) Group Relative Policy Optimization:采用该方法进行策略优化,鼓励模型生成更优的翻译结果。3) 结构感知奖励函数:包括TreeSim和Node-chrF,分别衡量翻译结果的结构相似性和节点级别的翻译质量。4) StrucAUC指标:用于评估翻译结果的结构错误严重程度。整个流程是先通过监督学习得到一个初步的模型,然后通过强化学习,利用结构化的奖励信号,进一步提升模型的性能。
关键创新:论文的关键创新在于提出了FormatRL框架,将强化学习应用于结构化文档翻译,并设计了结构感知的奖励函数。与现有方法相比,FormatRL能够直接优化翻译结果的结构,从而更好地保留文档的整体结构信息。此外,StrucAUC指标的引入,使得对结构错误的评估更加细致。
关键设计:TreeSim奖励函数通过计算预测XML树和参考XML树之间的结构相似度来衡量翻译结果的结构质量。Node-chrF奖励函数则在XML节点级别衡量翻译的准确性。Group Relative Policy Optimization用于优化策略,鼓励模型生成更高奖励的翻译结果。StrucAUC指标用于区分细微的结构错误和严重的结构错误,从而更全面地评估翻译质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FormatRL在SAP软件文档翻译基准测试中,在六个指标上均取得了显著的改进。具体而言,该方法在结构相似性(TreeSim)和节点翻译质量(Node-chrF)等方面均优于现有方法,证明了其在结构化文档翻译方面的有效性。
🎯 应用场景
该研究成果可应用于软件文档翻译、技术手册翻译、网页内容翻译等领域,尤其适用于对结构化信息要求较高的场景。通过提升翻译的结构准确性,可以提高翻译文档的可读性和可用性,降低人工校对成本,并促进跨语言信息交流。
📄 摘要(原文)
Recent works on structured text translation remain limited to the sentence level, as they struggle to effectively handle the complex document-level XML or HTML structures. To address this, we propose \textbf{Format Reinforcement Learning (FormatRL)}, which employs Group Relative Policy Optimization on top of a supervised fine-tuning model to directly optimize novel structure-aware rewards: 1) TreeSim, which measures structural similarity between predicted and reference XML trees and 2) Node-chrF, which measures translation quality at the level of XML nodes. Additionally, we apply StrucAUC, a fine-grained metric distinguishing between minor errors and major structural failures. Experiments on the SAP software-documentation benchmark demonstrate improvements across six metrics and an analysis further shows how different reward functions contribute to improvements in both structural and translation quality.