Mitigating Catastrophic Forgetting in Target Language Adaptation of LLMs via Source-Shielded Updates
作者: Atsuki Yamaguchi, Terufumi Morishita, Aline Villavicencio, Nikolaos Aletras
分类: cs.CL, cs.AI
发布日期: 2025-12-04
💡 一句话要点
提出源屏蔽更新方法,缓解LLM目标语言适应中的灾难性遗忘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灾难性遗忘 多语言模型 低资源学习 参数选择性更新 源屏蔽更新
📋 核心要点
- 现有方法依赖大量目标语言标注数据,且在适应过程中易发生灾难性遗忘,影响源语言性能。
- 提出源屏蔽更新(SSU)策略,通过选择性参数更新,主动保护模型在源语言上的知识。
- 实验表明,SSU有效缓解了灾难性遗忘,并在目标语言任务上取得了与全量微调相当甚至更好的性能。
📝 摘要(中文)
扩展指令大型语言模型(LLM)的语言多样性对于全球可访问性至关重要,但通常受到对昂贵的目标语言标注数据的依赖以及适应过程中的灾难性遗忘的阻碍。本文在现实的低资源约束下解决这一挑战:仅使用未标注的目标语言数据来调整指令LLM。我们引入了源屏蔽更新(SSU),这是一种选择性的参数更新策略,可主动保留源知识。SSU使用少量源数据和参数重要性评分方法,识别对于维持源能力至关重要的参数。然后在适应之前应用列式冻结策略来保护这些参数。在五种类型多样的语言以及7B和13B模型上的实验表明,SSU成功地缓解了灾难性遗忘。它将单语源任务的性能下降降低到平均仅3.4%(7B)和2.8%(13B),与完全微调的20.3%和22.3%形成鲜明对比。SSU还实现了与完全微调高度竞争的目标语言性能,在7B模型的所有基准测试中以及13B模型的大多数基准测试中均优于完全微调。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在适应目标语言时出现的灾难性遗忘问题。现有方法通常需要大量的目标语言标注数据进行微调,这在低资源场景下不可行。此外,全量微调容易导致模型忘记在源语言上学习到的知识,严重影响其通用能力。
核心思路:核心思路是通过识别并保护对源语言能力至关重要的参数,从而在适应目标语言时避免灾难性遗忘。具体来说,就是先评估模型参数的重要性,然后冻结重要的参数,只更新不重要的参数。这样既能让模型学习新的目标语言知识,又能保留原有的源语言知识。
技术框架:SSU方法主要包含以下几个阶段:1) 参数重要性评分:使用少量源语言数据,通过某种方法(论文中未明确说明具体方法,但提到是parameter importance scoring method)评估模型中每个参数对于源语言任务的重要性。2) 参数冻结:根据参数重要性评分,选择一部分重要的参数进行冻结,即在后续的训练过程中不更新这些参数。论文采用列式冻结策略(column-wise freezing strategy)。3) 目标语言适应:使用未标注的目标语言数据对模型进行微调,只更新未被冻结的参数。
关键创新:关键创新在于提出了一种选择性的参数更新策略,能够在适应目标语言的同时,有效地保护模型在源语言上的知识。与传统的全量微调相比,SSU避免了灾难性遗忘的问题,提高了模型的通用能力。与直接冻结所有参数相比,SSU允许模型学习新的目标语言知识,提高了模型在目标语言上的性能。
关键设计:论文的关键设计包括:1) 参数重要性评分方法:如何准确地评估参数的重要性是SSU的关键。论文中提到使用了parameter importance scoring method,但没有详细说明具体方法,这部分是未知信息。2) 参数冻结比例:冻结多少比例的参数需要在实验中进行调整,以达到最佳的平衡。3) 列式冻结策略:选择列式冻结,可能是考虑到transformer的结构特点,对特定列的参数进行冻结,可以保留特定head或layer的信息。
🖼️ 关键图片

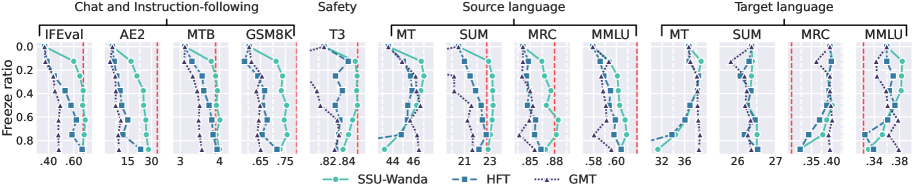

📊 实验亮点
实验结果表明,SSU方法在7B和13B模型上,将单语源任务的性能下降分别降低到平均3.4%和2.8%,远低于全量微调的20.3%和22.3%。同时,SSU在目标语言任务上取得了与全量微调相当甚至更好的性能,在7B模型的所有基准测试中以及13B模型的大多数基准测试中均优于全量微调。
🎯 应用场景
该研究成果可应用于多语言LLM的开发,尤其是在低资源语言场景下。通过SSU方法,可以利用少量目标语言数据,快速构建高性能的多语言模型,降低开发成本,并提升模型的全球可用性。此外,该方法也可以应用于其他领域的模型迁移学习,例如从图像领域迁移到文本领域。
📄 摘要(原文)
Expanding the linguistic diversity of instruct large language models (LLMs) is crucial for global accessibility but is often hindered by the reliance on costly specialized target language labeled data and catastrophic forgetting during adaptation. We tackle this challenge under a realistic, low-resource constraint: adapting instruct LLMs using only unlabeled target language data. We introduce Source-Shielded Updates (SSU), a selective parameter update strategy that proactively preserves source knowledge. Using a small set of source data and a parameter importance scoring method, SSU identifies parameters critical to maintaining source abilities. It then applies a column-wise freezing strategy to protect these parameters before adaptation. Experiments across five typologically diverse languages and 7B and 13B models demonstrate that SSU successfully mitigates catastrophic forgetting. It reduces performance degradation on monolingual source tasks to just 3.4% (7B) and 2.8% (13B) on average, a stark contrast to the 20.3% and 22.3% from full fine-tuning. SSU also achieves target-language performance highly competitive with full fine-tuning, outperforming it on all benchmarks for 7B models and the majority for 13B models.