DaLA: Danish Linguistic Acceptability Evaluation Guided by Real World Errors
作者: Gianluca Barmina, Nathalie Carmen Hau Norman, Peter Schneider-Kamp, Lukas Galke Poech
分类: cs.CL
发布日期: 2025-12-04 (更新: 2025-12-08)
💡 一句话要点
提出DaLA,一个基于真实世界丹麦语错误的语言可接受性评估基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 丹麦语 语言可接受性 评估基准 错误生成 大型语言模型
📋 核心要点
- 现有丹麦语语言可接受性评估基准覆盖范围有限,难以充分评估语言模型。
- 通过分析真实世界错误,设计多种错误生成函数,系统性地引入错误。
- 实验表明,新基准更具挑战性,能更好地区分不同语言模型的性能。
📝 摘要(中文)
本文提出了一个增强的丹麦语语言可接受性评估基准。首先,分析了书面丹麦语中最常见的错误。基于此分析,引入了十四种错误生成函数,通过系统地将错误引入现有的正确丹麦语句子来生成不正确的句子。为了确保这些错误生成的准确性,使用手动和自动方法评估了它们的有效性。然后,将结果用作评估大型语言模型在语言可接受性判断任务上的基准。研究结果表明,这种扩展比当前的技术水平更广泛、更全面。通过结合更多种类的错误类型,该基准对语言可接受性提供了更严格的评估,增加了任务难度,这可以从LLM在该基准上相比现有基准的较低性能中看出。结果还表明,该基准具有更高的区分能力,可以更好地区分表现良好的模型和表现不佳的模型。
🔬 方法详解
问题定义:论文旨在解决丹麦语语言可接受性评估基准不足的问题。现有的基准覆盖的错误类型有限,无法充分评估大型语言模型在处理真实世界丹麦语错误方面的能力。这使得评估结果可能过于乐观,无法准确反映模型在实际应用中的表现。
核心思路:论文的核心思路是基于对真实世界丹麦语错误的分析,系统性地生成包含各种错误的句子,从而构建一个更具挑战性和代表性的评估基准。通过引入多种类型的错误,可以更全面地评估语言模型对丹麦语语言规则的理解和应用能力。
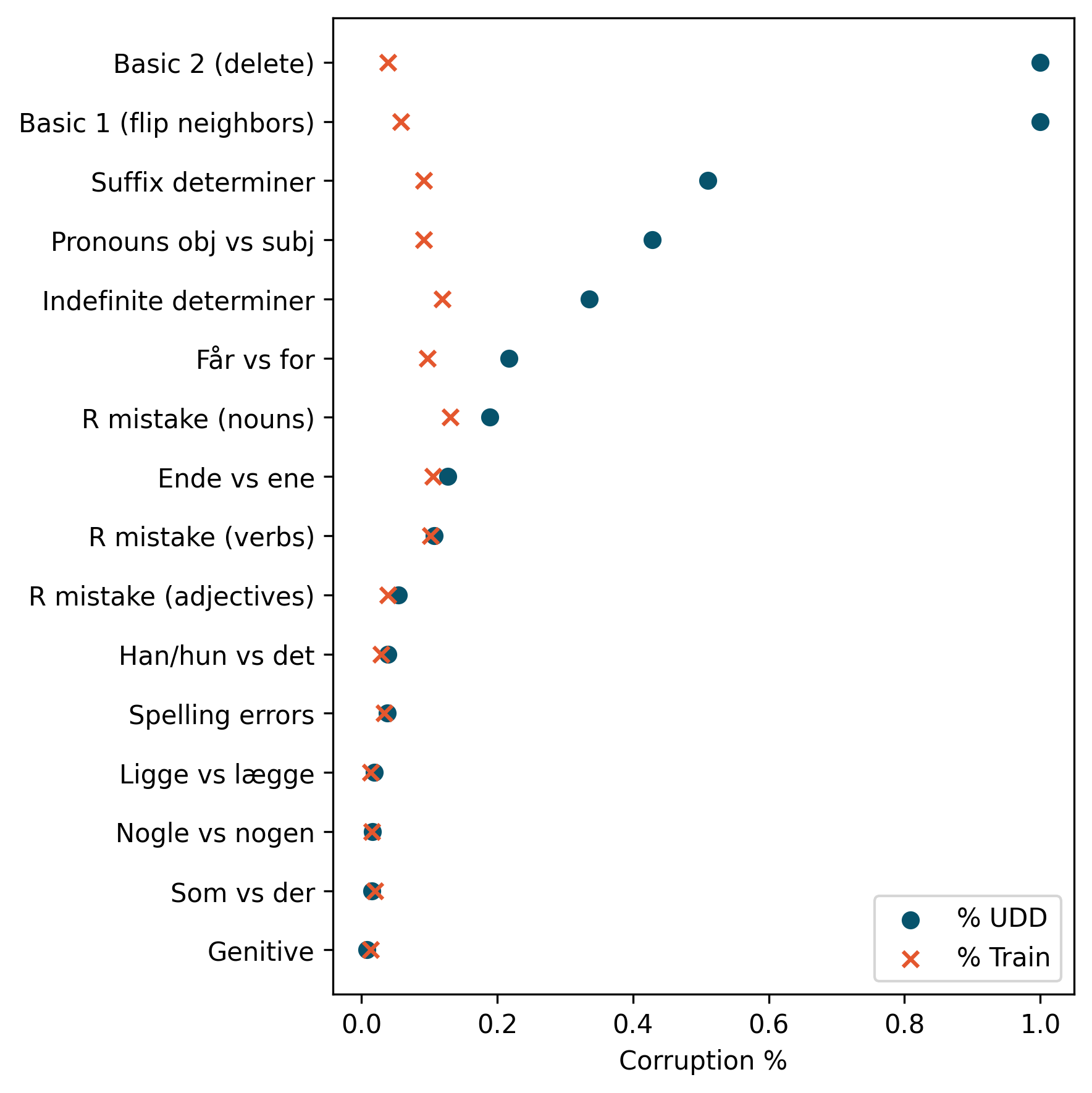
技术框架:该方法主要包含以下几个阶段:1) 分析真实世界丹麦语错误,确定常见的错误类型。2) 设计与实现14种错误生成函数,每种函数对应一种特定的错误类型。3) 使用这些函数对正确的丹麦语句子进行修改,生成包含错误的句子。4) 通过人工和自动方法验证生成的错误句子的有效性。5) 将生成的错误句子作为评估基准,评估大型语言模型在语言可接受性判断任务上的表现。
关键创新:该论文的关键创新在于其错误生成函数的构建方式。这些函数并非随机地引入错误,而是基于对真实世界丹麦语错误的深入分析,有针对性地模拟常见的错误类型。这种方法使得生成的错误句子更具代表性,更能反映实际应用中可能遇到的情况。此外,结合人工和自动验证方法,确保了生成的错误句子的质量。
关键设计:错误生成函数的设计是关键。每种函数都对应一种特定的错误类型,例如拼写错误、语法错误、词汇错误等。函数的具体实现方式取决于错误类型的特点。例如,对于拼写错误,可以使用键盘距离或语音相似度来模拟常见的拼写错误。对于语法错误,可以随机地删除或替换句子中的成分。此外,论文还考虑了错误之间的相互影响,例如,一个句子中可能同时存在多种类型的错误。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用DaLA基准评估时,大型语言模型的性能显著下降,表明该基准更具挑战性。同时,DaLA基准能够更好地区分不同模型的性能,具有更高的区分能力。例如,在现有基准上表现相近的模型,在DaLA基准上的表现差异更加明显。
🎯 应用场景
该研究成果可应用于丹麦语自然语言处理的多个领域,例如语法检查、机器翻译、文本校对等。通过使用该基准评估和改进语言模型,可以提高这些应用在处理真实世界丹麦语文本时的准确性和可靠性。此外,该研究方法也可以推广到其他语言的语言可接受性评估。
📄 摘要(原文)
We present an enhanced benchmark for evaluating linguistic acceptability in Danish. We first analyze the most common errors found in written Danish. Based on this analysis, we introduce a set of fourteen corruption functions that generate incorrect sentences by systematically introducing errors into existing correct Danish sentences. To ensure the accuracy of these corruptions, we assess their validity using both manual and automatic methods. The results are then used as a benchmark for evaluating Large Language Models on a linguistic acceptability judgement task. Our findings demonstrate that this extension is both broader and more comprehensive than the current state of the art. By incorporating a greater variety of corruption types, our benchmark provides a more rigorous assessment of linguistic acceptability, increasing task difficulty, as evidenced by the lower performance of LLMs on our benchmark compared to existing ones. Our results also suggest that our benchmark has a higher discriminatory power which allows to better distinguish well-performing models from low-performing ones.