Challenging the Abilities of Large Language Models in Italian: a Community Initiative
作者: Malvina Nissim, Danilo Croce, Viviana Patti, Pierpaolo Basile, Giuseppe Attanasio, Elio Musacchio, Matteo Rinaldi, Federico Borazio, Maria Francis, Jacopo Gili, Daniel Scalena, Begoña Altuna, Ekhi Azurmendi, Valerio Basile, Luisa Bentivogli, Arianna Bisazza, Marianna Bolognesi, Dominique Brunato, Tommaso Caselli, Silvia Casola, Maria Cassese, Mauro Cettolo, Claudia Collacciani, Leonardo De Cosmo, Maria Pia Di Buono, Andrea Esuli, Julen Etxaniz, Chiara Ferrando, Alessia Fidelangeli, Simona Frenda, Achille Fusco, Marco Gaido, Andrea Galassi, Federico Galli, Luca Giordano, Mattia Goffetti, Itziar Gonzalez-Dios, Lorenzo Gregori, Giulia Grundler, Sandro Iannaccone, Chunyang Jiang, Moreno La Quatra, Francesca Lagioia, Soda Marem Lo, Marco Madeddu, Bernardo Magnini, Raffaele Manna, Fabio Mercorio, Paola Merlo, Arianna Muti, Vivi Nastase, Matteo Negri, Dario Onorati, Elena Palmieri, Sara Papi, Lucia Passaro, Giulia Pensa, Andrea Piergentili, Daniele Potertì, Giovanni Puccetti, Federico Ranaldi, Leonardo Ranaldi, Andrea Amelio Ravelli, Martina Rosola, Elena Sofia Ruzzetti, Giuseppe Samo, Andrea Santilli, Piera Santin, Gabriele Sarti, Giovanni Sartor, Beatrice Savoldi, Antonio Serino, Andrea Seveso, Lucia Siciliani, Paolo Torroni, Rossella Varvara, Andrea Zaninello, Asya Zanollo, Fabio Massimo Zanzotto, Kamyar Zeinalipour, Andrea Zugarini
分类: cs.CL
发布日期: 2025-12-04
💡 一句话要点
CALAMITA:意大利语大型语言模型能力评测的社区驱动基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 意大利语 基准测试 社区驱动 自然语言处理
📋 核心要点
- 现有大型语言模型在非英语语种,特别是意大利语上的系统评估不足。
- CALAMITA项目通过社区协作,构建包含多种任务的意大利语基准测试集。
- 该项目不仅提供基准数据集,还建立了统一的评估流程,并分析了现有模型的优缺点。
📝 摘要(中文)
大型语言模型(LLM)的快速发展改变了自然语言处理,并扩大了其在研究和社会中的影响。然而,对这些模型的系统评估,特别是对于英语以外的语言,仍然有限。“挑战意大利语语言模型能力”(CALAMITA)是一项针对意大利语的大规模协作基准测试计划,由意大利计算语言学协会协调。与侧重于排行榜的现有工作不同,CALAMITA强调方法论:它联合了来自学术界、工业界和公共部门的80多位贡献者,设计、记录和评估各种任务,涵盖语言能力、常识推理、事实一致性、公平性、摘要、翻译和代码生成。通过这个过程,我们不仅组装了一个包含20多个任务和近100个子任务的基准,还建立了一个支持异构数据集和指标的集中评估管道。我们报告了四个开放权重LLM的结果,突出了跨能力的系统优势和劣势,以及特定任务评估中的挑战。除了定量结果之外,CALAMITA还揭示了方法论的教训:细粒度、任务代表性指标的必要性,统一管道的重要性,以及广泛社区参与的益处和局限性。CALAMITA被设想为一个滚动基准,能够持续集成新的任务和模型。这使其既成为一种资源(迄今为止最全面和多样化的意大利语基准),又成为一个可持续的、社区驱动的评估框架。我们认为,这种组合为其他寻求包容和严格的LLM评估实践的语言和社区提供了一个蓝图。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)主要针对英语进行了优化,在其他语言,如意大利语上的表现缺乏充分的评估。现有的评估方法往往侧重于排行榜,缺乏对模型能力细粒度的分析,并且评估流程不统一,难以进行公平比较。此外,缺乏社区参与,导致评估任务和指标可能不够全面,无法充分反映意大利语的语言特点和文化背景。
核心思路:CALAMITA项目的核心思路是通过社区协作,构建一个全面、多样化的意大利语基准测试集,并建立一个统一的评估流程,从而更准确地评估LLM在意大利语上的能力。该项目强调方法论的重要性,鼓励社区成员参与任务设计、数据收集和模型评估,以确保评估的公平性和代表性。
技术框架:CALAMITA项目的整体框架包括以下几个主要模块:1) 任务定义:由社区成员共同设计各种任务,涵盖语言能力、常识推理、事实一致性、公平性、摘要、翻译和代码生成等多个方面。2) 数据收集:收集或创建用于评估的意大利语数据集,并对数据进行清洗和标注。3) 评估流程:建立一个统一的评估流程,包括数据预处理、模型推理、指标计算和结果分析。4) 模型评估:使用该基准测试集评估各种LLM在意大利语上的表现,并分析其优缺点。5) 结果报告:将评估结果以清晰、易懂的方式呈现给社区,并提供详细的分析报告。
关键创新:CALAMITA项目最重要的技术创新点在于其社区驱动的评估模式。通过广泛的社区参与,该项目能够更全面地覆盖意大利语的语言特点和文化背景,并设计出更具代表性的评估任务。此外,该项目建立的统一评估流程,能够确保不同模型之间的公平比较,并促进LLM在意大利语上的发展。
关键设计:CALAMITA项目在任务设计方面,考虑了意大利语的特殊性,例如其复杂的语法结构和丰富的词汇。在评估指标方面,该项目采用了细粒度的指标,以便更准确地评估模型在不同方面的能力。此外,该项目还注重评估模型的公平性,避免模型在某些群体上表现出偏差。
🖼️ 关键图片
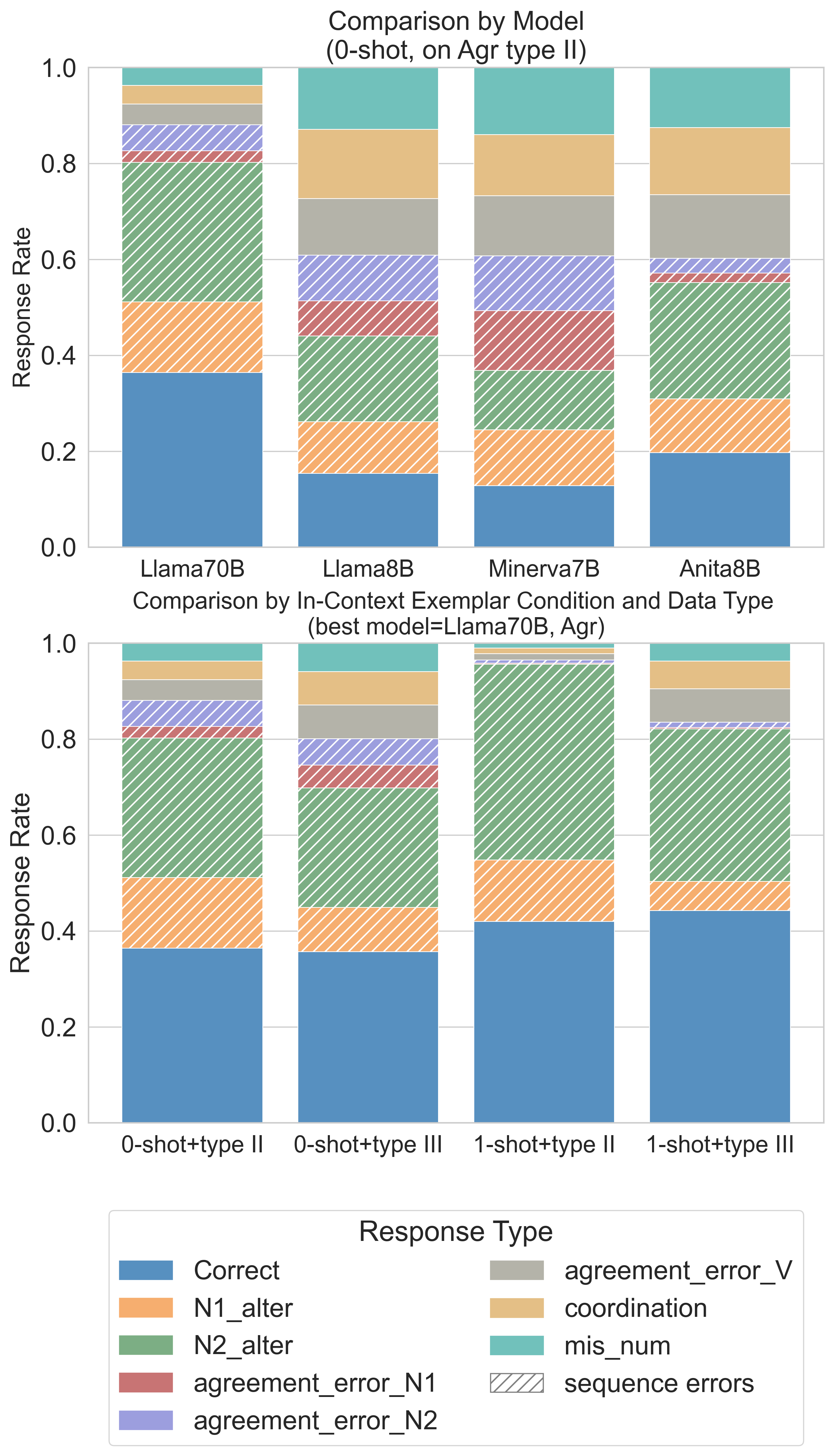

📊 实验亮点
CALAMITA项目评估了四个开放权重的LLM,揭示了它们在不同任务上的优势和劣势。例如,某些模型在语言理解方面表现出色,但在常识推理方面存在不足。该项目还强调了细粒度指标的重要性,并指出现有评估方法可能无法充分反映模型在特定任务上的表现。此外,该项目还强调了社区参与的价值,并鼓励更多人参与到LLM的评估和改进中来。
🎯 应用场景
该研究成果可应用于开发更强大的意大利语自然语言处理系统,例如智能客服、机器翻译、文本摘要等。通过持续的基准测试和社区参与,可以促进意大利语LLM的改进,并为其他语言的LLM评估提供参考。该项目还有助于提高公众对LLM能力的认识,并促进其在意大利语环境下的负责任使用。
📄 摘要(原文)
The rapid progress of Large Language Models (LLMs) has transformed natural language processing and broadened its impact across research and society. Yet, systematic evaluation of these models, especially for languages beyond English, remains limited. "Challenging the Abilities of LAnguage Models in ITAlian" (CALAMITA) is a large-scale collaborative benchmarking initiative for Italian, coordinated under the Italian Association for Computational Linguistics. Unlike existing efforts that focus on leaderboards, CALAMITA foregrounds methodology: it federates more than 80 contributors from academia, industry, and the public sector to design, document, and evaluate a diverse collection of tasks, covering linguistic competence, commonsense reasoning, factual consistency, fairness, summarization, translation, and code generation. Through this process, we not only assembled a benchmark of over 20 tasks and almost 100 subtasks, but also established a centralized evaluation pipeline that supports heterogeneous datasets and metrics. We report results for four open-weight LLMs, highlighting systematic strengths and weaknesses across abilities, as well as challenges in task-specific evaluation. Beyond quantitative results, CALAMITA exposes methodological lessons: the necessity of fine-grained, task-representative metrics, the importance of harmonized pipelines, and the benefits and limitations of broad community engagement. CALAMITA is conceived as a rolling benchmark, enabling continuous integration of new tasks and models. This makes it both a resource -- the most comprehensive and diverse benchmark for Italian to date -- and a framework for sustainable, community-driven evaluation. We argue that this combination offers a blueprint for other languages and communities seeking inclusive and rigorous LLM evaluation practices.