EtCon: Edit-then-Consolidate for Reliable Knowledge Editing
作者: Ruilin Li, Yibin Wang, Wenhong Zhu, Chenglin Li, Jinghao Zhang, Chenliang Li, Junchi Yan, Jiaqi Wang
分类: cs.CL
发布日期: 2025-12-04 (更新: 2026-01-30)
💡 一句话要点
EtCon:编辑-整合范式,提升大语言模型知识编辑的可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识编辑 大语言模型 策略优化 自回归生成 近端策略优化
📋 核心要点
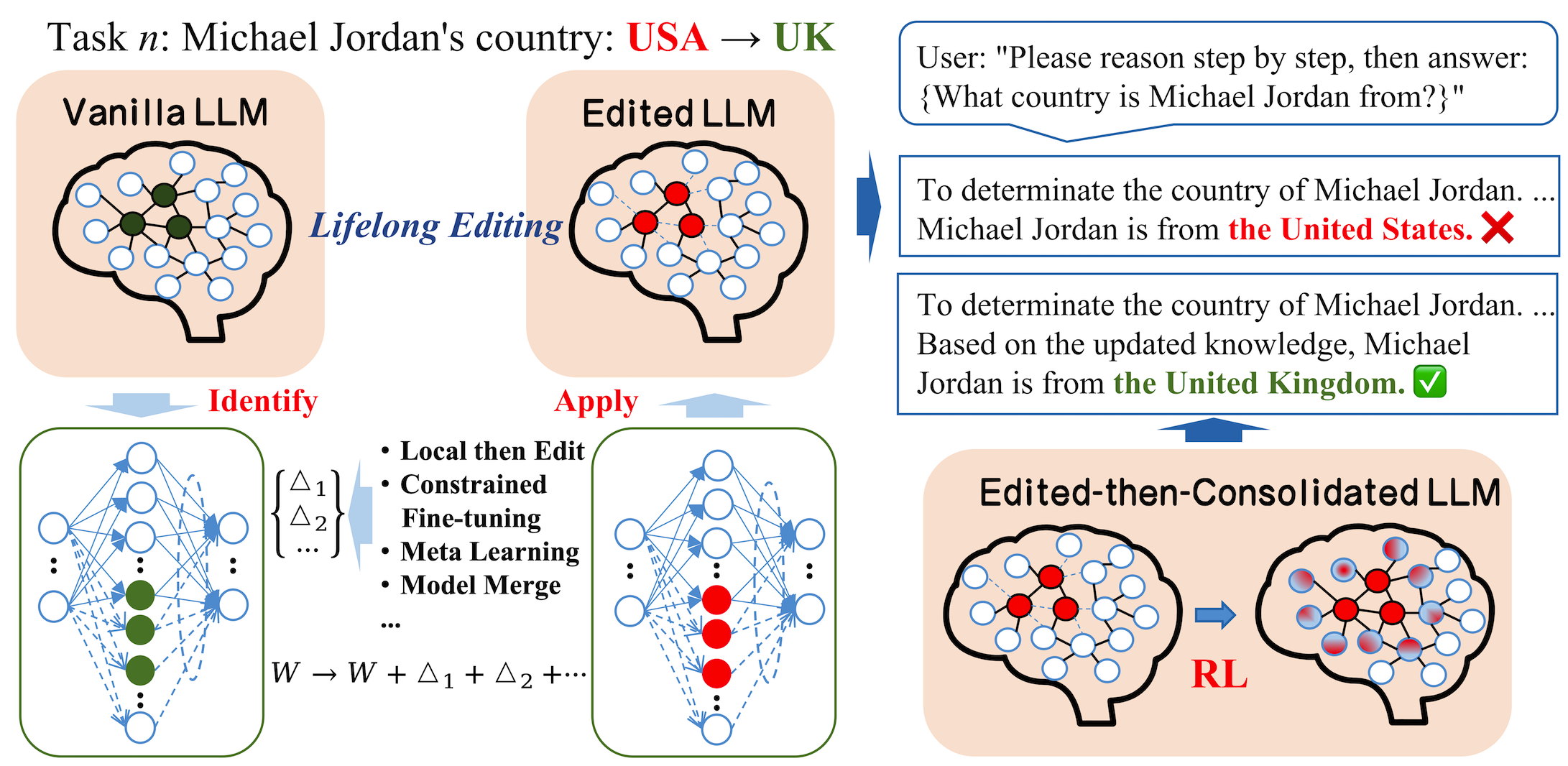
- 现有知识编辑方法在注入新知识后容易降低LLM的预训练能力,并且参数知识与自回归生成行为存在差异。
- EtCon采用编辑-整合范式,通过有针对性的编辑和编辑后的整合,来提升知识编辑的可靠性。
- 实验表明,EtCon提高了编辑的可靠性和泛化能力,同时更好地保留了LLM的预训练能力。
📝 摘要(中文)
知识编辑旨在无需完全重新训练的情况下更新大型语言模型(LLMs)中的特定事实。现有方法主要调整LLMs的知识层,在受控的、教师强制的评估中取得了改进。然而,它们在实际的自回归生成场景中仍然面临挑战,这极大地限制了它们的实际应用。我们的实证分析揭示了两个问题:(1)大多数方法在注入新知识后会降低预训练能力;(2)它们可能表现出存储的参数化知识与推理时的自回归生成行为之间的差异。为此,我们提出了一种编辑-整合范式EtCon,它将有针对性的编辑与编辑后的整合相结合。具体来说,我们的框架包括两个阶段:(1)有针对性的近端监督微调(TPSFT)执行受约束的有针对性的编辑,以更新参数化知识,同时控制策略漂移。(2)组相对策略优化(GRPO)通过将自回归轨迹与预期事实对齐来巩固编辑。大量的实验表明,我们的EtCon提高了编辑的可靠性和真实世界的泛化能力,同时更好地保留了预训练能力。
🔬 方法详解
问题定义:知识编辑旨在更新LLM中特定事实,现有方法在实际自回归生成场景中表现不佳,存在预训练能力退化和参数知识与生成行为不一致的问题。现有方法主要依赖于教师强制训练,忽略了模型自身的生成特性,导致在实际应用中效果不佳。
核心思路:EtCon的核心思路是将知识编辑分解为两个阶段:首先进行有针对性的编辑,然后进行整合,以确保编辑后的模型既能记住新知识,又能保持原有的能力,并使参数知识与生成行为对齐。通过编辑和整合两个阶段,解决现有方法存在的问题。
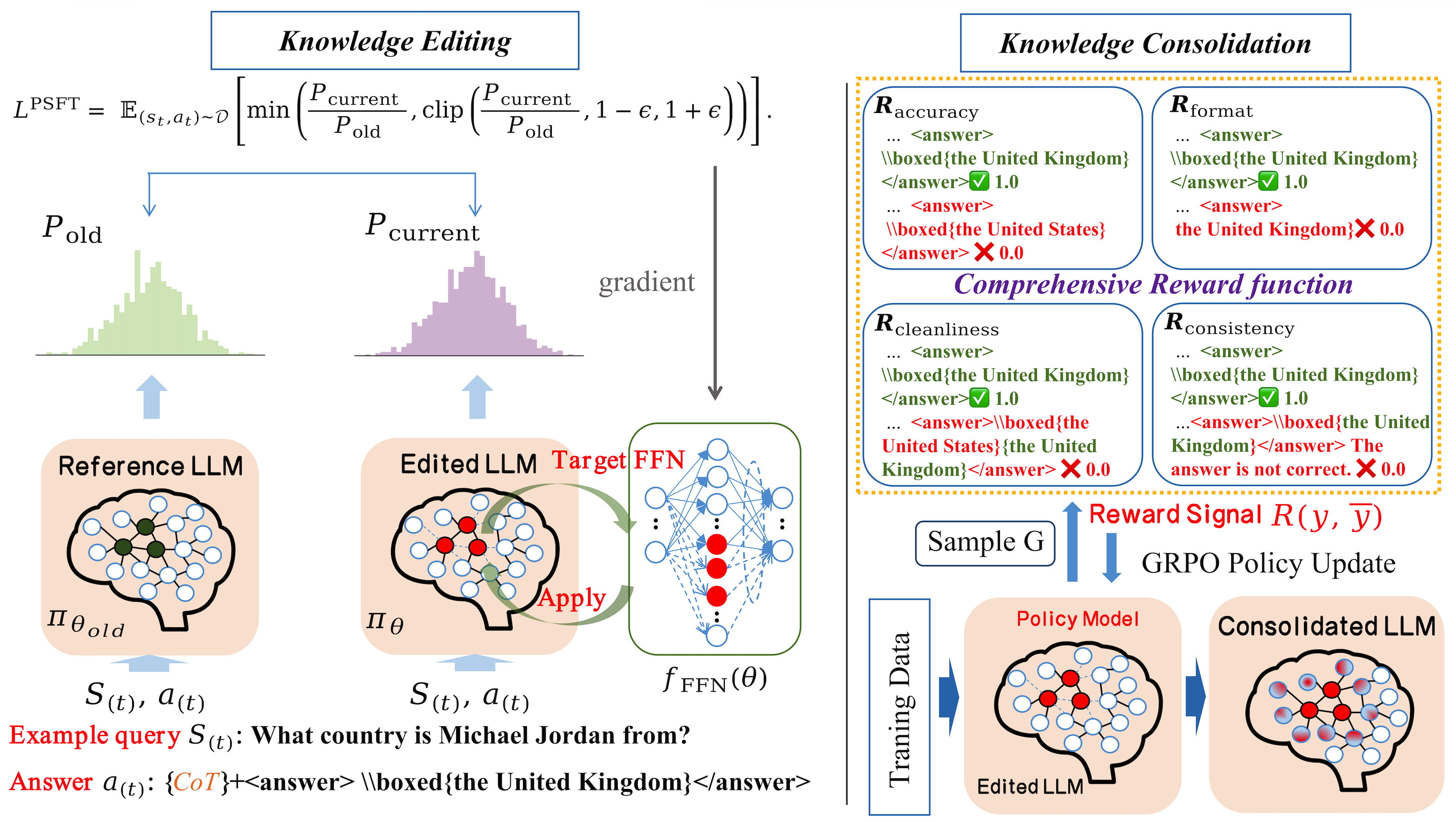
技术框架:EtCon框架包含两个主要阶段:(1) 目标近端监督微调(TPSFT):通过约束性的微调来更新参数化知识,并控制策略漂移。(2) 组相对策略优化(GRPO):通过对齐自回归轨迹与目标事实来巩固编辑结果。TPSFT负责知识的注入,GRPO负责知识的对齐和巩固。
关键创新:EtCon的关键创新在于其编辑-整合范式,它将知识编辑分解为两个明确的阶段,并分别使用不同的技术来解决每个阶段的问题。与现有方法相比,EtCon更加关注模型自身的生成特性,并尝试通过策略优化来对齐参数知识与生成行为。
关键设计:TPSFT使用近端策略优化来约束微调过程,防止策略漂移。GRPO使用相对策略优化来对齐自回归轨迹与目标事实,并使用分组策略来提高训练效率。具体的损失函数设计和参数设置在论文中有详细描述,例如,TPSFT中使用了KL散度来约束策略漂移,GRPO中使用了reward shaping来引导策略优化。
🖼️ 关键图片

📊 实验亮点
实验结果表明,EtCon在知识编辑的可靠性和泛化能力方面优于现有方法。具体来说,EtCon在多个基准数据集上取得了显著的性能提升,同时更好地保留了LLM的预训练能力。例如,在某些数据集上,EtCon的编辑成功率比现有方法提高了10%以上,并且在保留预训练知识方面也表现出更好的性能。
🎯 应用场景
EtCon可应用于各种需要知识更新的场景,例如问答系统、对话系统和信息检索系统。它可以帮助这些系统快速适应新的信息,提高其准确性和可靠性。此外,EtCon还可以用于修复LLM中的错误知识,提高其知识的完整性和一致性,从而提升LLM在实际应用中的表现。
📄 摘要(原文)
Knowledge editing aims to update specific facts in large language models (LLMs) without full retraining. Prior efforts sought to tune the knowledge layers of LLMs, achieving improved performance in controlled, teacher-forced evaluations. However, they still encounter challenges in real-world autoregressive generation scenarios, which greatly limit their practical applicability. Our empirical analysis reveals two issues: (1) Most methods degrade pre-trained capabilities after injecting new knowledge; (2) They may exhibit a discrepancy between stored parametric knowledge and inference-time autoregressive generation behavior. To this end, we propose EtCon, an edit-then-consolidate paradigm that couples targeted edits with post-edit consolidation. Specifically, our framework comprises two stages: (1) Targeted Proximal Supervised Fine-Tuning (TPSFT) performs a constrained targeted edit to update parametric knowledge while controlling policy drift. (2) Group Relative Policy Optimization (GRPO) consolidates the edit by aligning autoregressive trajectories with the intended fact. Extensive experiments demonstrate that our EtCon improves editing reliability and real-world generalization, while better preserving pre-trained capabilities.