Model Whisper: Steering Vectors Unlock Large Language Models' Potential in Test-time
作者: Xinyue Kang, Diwei Shi, Li Chen
分类: cs.CL
发布日期: 2025-12-04
备注: accepted to aaai2026
💡 一句话要点
提出测试时引导向量,无需微调即可提升大语言模型在特定任务上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 测试时自适应 引导向量 零样本学习 低资源优化
📋 核心要点
- 现有测试时自适应方法计算成本高,且可能损害LLM的预训练能力。
- 通过优化附加到输入的测试时引导向量(TTSV),引导模型进入高置信度状态。
- 在MATH500任务上,TTSV在多个模型上取得了显著的性能提升,并具有良好的泛化性。
📝 摘要(中文)
本文提出了一种轻量级的测试时自适应方法,旨在高效地激发大语言模型(LLM)在特定任务或新分布上的推理潜力。现有方法通常需要调整模型参数,这不仅计算成本高昂,还可能降低模型原有的能力。为了解决这个问题,我们引入了测试时引导向量(TTSV),它被添加到输入中,同时完全冻结LLM的参数。通过在测试数据上优化TTSV以最小化模型的输出熵,我们引导模型进入一种置信度更高的内部状态,从而激活其与当前任务最相关的内在能力。TTSV既轻量级又易于优化,使其成为一种真正的即插即用增强方法。大量实验验证了我们的方法在基础模型和推理增强模型上的有效性。例如,在MATH500任务上,TTSV在Qwen2.5-Math-7B模型上实现了45.88%的相对性能提升,在Qwen3-4B模型上实现了16.22%的相对性能提升。此外,我们的方法表现出强大的泛化能力,其引导向量在不同的任务中具有高度的可迁移性。
🔬 方法详解
问题定义:现有的大语言模型测试时自适应方法通常需要微调模型参数,这带来了两个主要问题:一是计算资源消耗大,二是可能导致模型遗忘已学习的知识,降低其泛化能力。因此,如何在不修改模型参数的情况下,高效地提升LLM在特定任务上的性能是一个关键挑战。
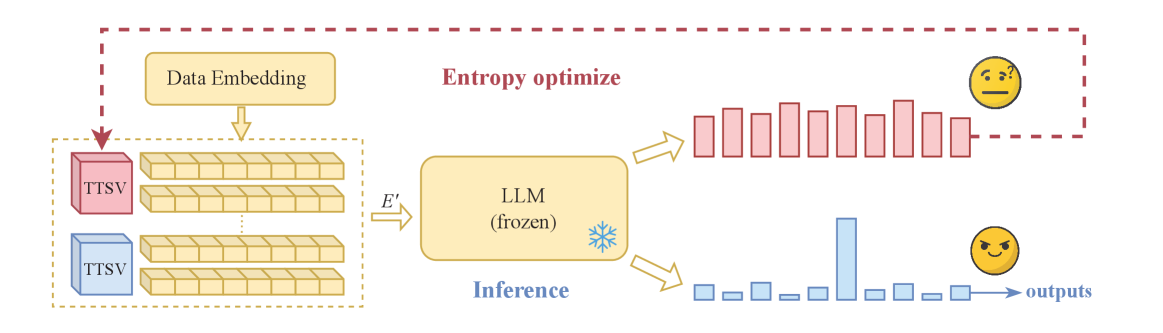
核心思路:本文的核心思路是通过引入一个轻量级的可学习向量,即测试时引导向量(TTSV),来影响LLM的内部状态,使其更加适应当前的任务。通过优化这个引导向量,可以使模型的输出熵最小化,从而提高模型对当前任务的置信度。这种方法避免了直接修改模型参数,从而保留了模型的通用能力。
技术框架:该方法的核心框架是在LLM的输入端添加一个可学习的TTSV。具体流程如下:1) 将TTSV与输入文本进行拼接;2) 将拼接后的输入送入冻结参数的LLM;3) 计算LLM输出的熵;4) 使用优化算法(如梯度下降)更新TTSV,以最小化输出熵。重复步骤2-4,直到TTSV收敛。最终,使用优化后的TTSV进行推理。
关键创新:该方法最重要的创新点在于引入了测试时引导向量(TTSV)的概念,它是一种轻量级的、可学习的向量,可以在不修改LLM参数的情况下,有效地引导模型适应特定任务。与传统的微调方法相比,TTSV的计算成本更低,且不会损害模型的通用能力。此外,该方法还利用了输出熵作为优化目标,这可以有效地提高模型对当前任务的置信度。
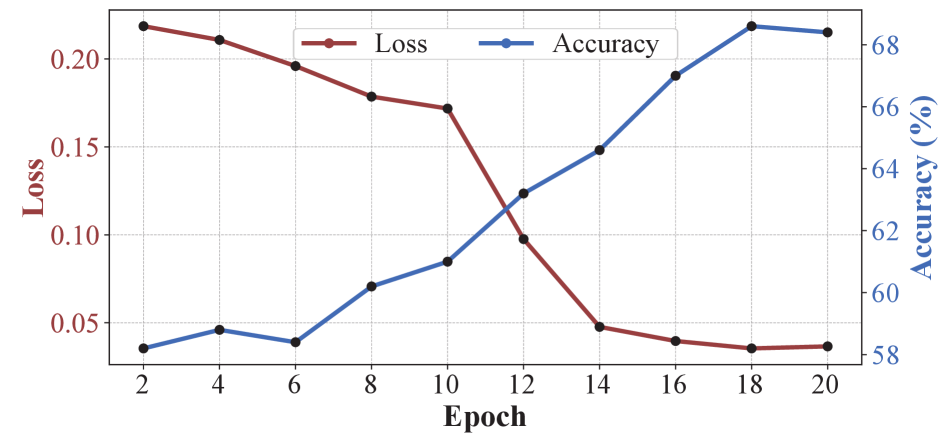
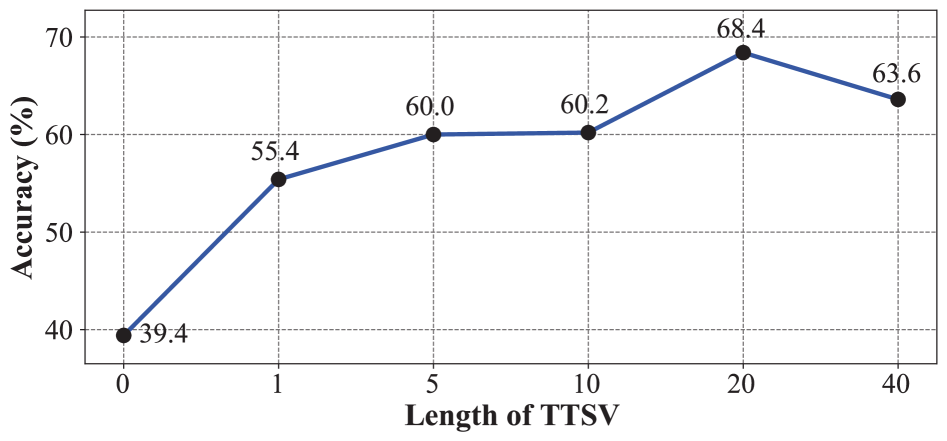
关键设计:TTSV的维度是一个关键参数,需要根据具体任务进行调整。损失函数采用交叉熵损失,优化算法可以选择Adam等常用的优化器。在实验中,作者发现较小的学习率和适当的迭代次数可以获得更好的性能。此外,TTSV的初始化也很重要,作者尝试了不同的初始化方法,并发现使用随机初始化可以获得较好的结果。
🖼️ 关键图片
📊 实验亮点
该研究在MATH500数据集上取得了显著的性能提升。例如,在Qwen2.5-Math-7B模型上,TTSV实现了45.88%的相对性能提升,在Qwen3-4B模型上实现了16.22%的相对性能提升。此外,实验结果表明,TTSV具有良好的泛化能力,可以在不同的任务之间进行迁移,进一步验证了该方法的有效性和实用性。
🎯 应用场景
该研究成果可广泛应用于各种需要快速适应特定任务的大语言模型应用场景,例如:问答系统、文本摘要、机器翻译等。它尤其适用于资源受限的环境,例如边缘计算设备,在这些设备上微调大型模型是不切实际的。该方法还可用于提高模型的鲁棒性,使其能够更好地应对噪声数据或对抗性攻击。
📄 摘要(原文)
It is a critical challenge to efficiently unlock the powerful reasoning potential of Large Language Models (LLMs) for specific tasks or new distributions. Existing test-time adaptation methods often require tuning model parameters, which is not only computationally expensive but also risks degrading the model's pre-existing abilities.To address this, we introduce a lightweight component, Test-Time Steering Vectors (TTSV), which is prepended to the input while keeping the LLM's parameters entirely frozen. By optimizing the TTSV on test data to minimize the model's output entropy, we steer the model towards an internal state of higher confidence, activating its inherent abilities most relevant to the current task. TTSV is both lightweight and highly efficient to optimize, making it a true plug-and-play enhancement. Extensive experiments validate our approach's effectiveness on both base models and reasoning-enhanced models. For instance, on the MATH500 task, TTSV achieves a 45.88% relative performance gain on the Qwen2.5-Math-7B model and a 16.22% relative gain on the Qwen3-4B model. Furthermore, our approach exhibits robust generalization, with its steering vectors proving highly transferable across diverse tasks.