ADAPT: Learning Task Mixtures for Budget-Constrained Instruction Tuning
作者: Pritam Kadasi, Abhishek Upperwal, Mayank SIngh
分类: cs.CL
发布日期: 2025-12-04
备注: Under Review
💡 一句话要点
ADAPT:学习任务混合比例,解决预算约束下的指令调优问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令调优 元学习 任务混合 自适应课程学习 预算约束 大语言模型 自然语言处理
📋 核心要点
- 现有指令调优方法通常手动设置任务权重,缺乏自适应性,难以在有限预算下优化性能。
- ADAPT通过元学习自动学习任务采样比例,根据任务的有用程度动态分配token预算,实现自适应课程学习。
- 实验表明,ADAPT在有限预算下,能够匹配或略微超过最佳静态混合的性能,并能将预算分配给更具挑战性的任务。
📝 摘要(中文)
本文提出了ADAPT,一种元学习算法,用于在多任务指令调优中,在显式的token预算约束下,学习任务采样的比例。ADAPT没有手动固定任务权重,而是维护一个关于任务的连续分布,并通过平滑的最坏情况验证目标的元梯度来更新它,从而诱导出一个自适应的课程,将更多的token分配给有用的任务,同时避免崩溃。我们在三个约10亿参数的开源LLM(Gemma-3-1B、LLaMA-3.2-1B、Qwen-0.6B)上实例化ADAPT,在可用监督token的1%、5%和10%的预算下,训练20种自然指令任务类型,并与具有均匀和大小比例混合的强监督微调基线进行比较。在涵盖推理、阅读理解、代码生成和指令遵循的11个领域外基准上进行评估,我们发现ADAPT在平均下游性能方面与最佳静态混合匹配或略有提高,同时使用更少的有效训练token,并将预算重新分配给更困难、与基准对齐的任务。
🔬 方法详解
问题定义:在指令调优中,如何有效地利用有限的计算资源(token预算)来训练模型,使其在下游任务上表现良好?现有方法通常采用固定的任务混合比例,无法根据任务的难度和对模型性能的贡献进行动态调整,导致资源利用率不高。
核心思路:ADAPT的核心思想是通过元学习来自动学习任务的采样比例。它维护一个关于任务的连续分布,并根据验证集上的性能反馈来更新这个分布。目标是找到一个任务混合比例,使得模型在最坏情况下的验证集性能最大化。这样可以促使模型更多地关注那些对性能提升最有帮助的任务。
技术框架:ADAPT的整体框架包括以下几个主要步骤:1) 初始化任务分布;2) 根据当前的任务分布采样一批任务;3) 在采样得到的任务上进行训练;4) 在验证集上评估模型的性能;5) 根据验证集上的性能,使用元梯度更新任务分布;6) 重复步骤2-5,直到收敛。其中,元梯度是通过对验证集损失关于任务分布的梯度进行估计得到的。
关键创新:ADAPT的关键创新在于它使用元学习来自动学习任务采样比例,从而实现自适应的课程学习。与传统的固定任务混合比例方法相比,ADAPT能够根据任务的难度和对模型性能的贡献进行动态调整,从而更有效地利用有限的计算资源。此外,ADAPT还使用了一种平滑的最坏情况验证目标,以避免任务分布的崩溃。
关键设计:ADAPT的关键设计包括:1) 使用连续分布来表示任务采样比例,允许更细粒度的控制;2) 使用元梯度来更新任务分布,使其能够根据验证集上的性能反馈进行调整;3) 使用平滑的最坏情况验证目标,以避免任务分布的崩溃;4) 在训练过程中,显式地考虑token预算的约束,确保模型在有限的计算资源下进行训练。
🖼️ 关键图片
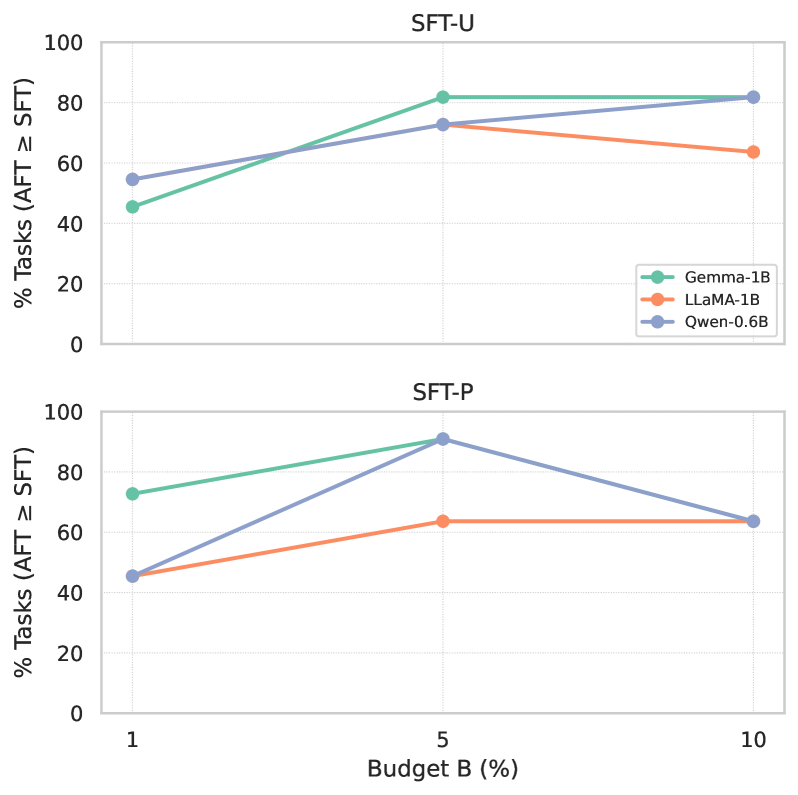
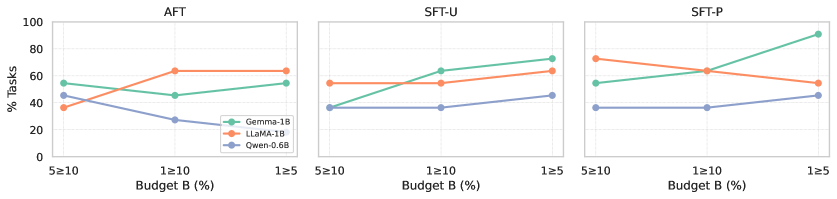
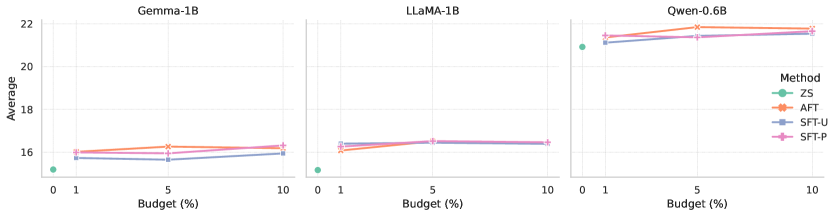
📊 实验亮点
实验结果表明,在三个约10亿参数的开源LLM(Gemma-3-1B、LLaMA-3.2-1B、Qwen-0.6B)上,ADAPT在1%、5%和10%的token预算下,与具有均匀和大小比例混合的强监督微调基线相比,在11个领域外基准测试中,ADAPT能够匹配或略微提高平均下游性能,同时使用更少的有效训练token,并将预算重新分配给更困难的任务。
🎯 应用场景
ADAPT可应用于各种自然语言处理任务的指令调优,尤其是在计算资源受限的场景下。例如,在移动设备或边缘设备上部署大型语言模型时,可以使用ADAPT来优化模型的训练过程,使其在有限的计算资源下达到最佳性能。此外,ADAPT还可以用于个性化学习,根据用户的学习情况动态调整任务的混合比例,提高学习效率。
📄 摘要(原文)
We propose ADAPT, a meta-learning algorithm that \emph{learns} task sampling proportions under an explicit token budget for multi-task instruction tuning. Instead of fixing task weights by hand, \adapt{} maintains a continuous distribution over tasks and updates it via meta-gradients of a smooth worst-case validation objective, inducing an adaptive curriculum that allocates more tokens to useful tasks while avoiding collapse. We instantiate ADAPT on three $\sim$1B-parameter open-weight LLMs (Gemma-3-1B, LLaMA-3.2-1B, Qwen-0.6B), training on 20 Natural Instructions task types under budgets of $1\%$, $5\%$, and $10\%$ of the available supervised tokens, and compare against strong supervised fine-tuning baselines with uniform and size-proportional mixing. We conduct evaluations on 11 out-of-domain benchmarks spanning reasoning, reading comprehension, code generation, and instruction following, we find that ADAPT matches or slightly improves average downstream performance relative to the best static mixture, while using fewer effective training tokens and reallocating budget toward harder, benchmark-aligned tasks.