AdmTree: Compressing Lengthy Context with Adaptive Semantic Trees
作者: Yangning Li, Shaoshen Chen, Yinghui Li, Yankai Chen, Hai-Tao Zheng, Hui Wang, Wenhao Jiang, Philip S. Yu
分类: cs.CL, cs.AI
发布日期: 2025-12-04
备注: NeurIPS 2025
💡 一句话要点
AdmTree:提出自适应语义树压缩长文本上下文,提升LLM处理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本处理 上下文压缩 大型语言模型 自适应语义树 信息密度
📋 核心要点
- 现有长文本处理方法在压缩上下文时,容易丢失局部细节或引入位置偏差,影响语义信息的完整性。
- AdmTree通过构建自适应语义树,动态分割和压缩上下文,旨在高效地保留长文本的语义信息。
- AdmTree采用轻量级聚合机制和冻结的LLM主干,减少了训练参数,同时保持了良好的性能。
📝 摘要(中文)
大型语言模型(LLM)中自注意力机制的二次复杂度限制了其处理长上下文的能力,而长上下文对于许多高级应用至关重要。上下文压缩旨在缓解这种计算瓶颈,同时保留关键的语义信息。然而,现有的方法往往存在不足:显式方法可能损害局部细节,而隐式方法可能遭受位置偏差、信息退化或无法捕获长程语义依赖关系。我们提出了AdmTree,这是一个新颖的自适应、分层上下文压缩框架,其核心在于保持高语义保真度,同时保持效率。AdmTree基于信息密度动态分割输入,利用概要token来总结可变长度的片段,作为语义二叉树的叶子节点。这种结构,结合轻量级的聚合机制和冻结的主干LLM(从而最小化新的可训练参数),实现了上下文的有效分层抽象。通过保留细粒度的细节以及全局语义连贯性,缓解位置偏差,并动态适应内容,AdmTree能够稳健地保留长上下文的语义信息。
🔬 方法详解
问题定义:大型语言模型在处理长文本时,自注意力机制的计算复杂度呈二次方增长,导致计算瓶颈。现有的上下文压缩方法,如显式方法(截断、池化)可能丢失关键细节,隐式方法(RNN、Transformer变体)则可能存在位置偏差或信息退化,难以有效捕获长程语义依赖关系。
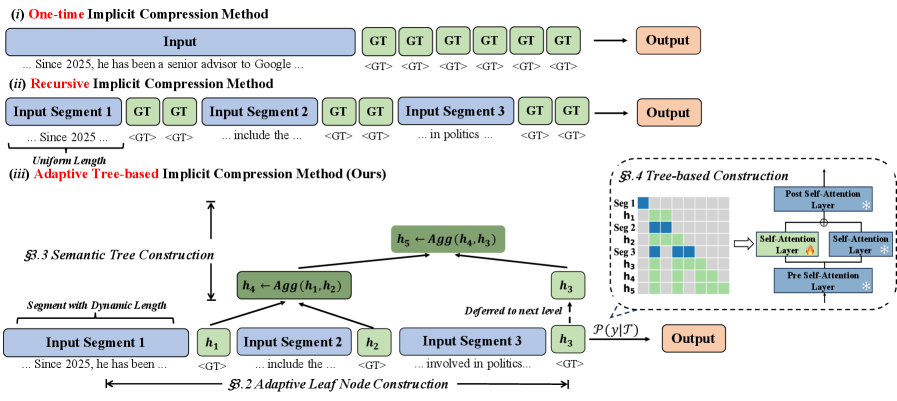
核心思路:AdmTree的核心在于构建一个自适应的语义树,通过分层的方式对长文本上下文进行压缩。它根据信息密度动态分割输入,并使用概要token来表示每个片段的语义信息,从而在压缩的同时保留关键细节和全局语义连贯性。
技术框架:AdmTree的整体框架包括以下几个主要步骤:1) 动态分割:根据输入文本的信息密度,将长文本分割成不同长度的片段。2) 概要生成:为每个片段生成概要token,作为语义树的叶子节点。3) 语义树构建:基于概要token构建二叉树,并通过轻量级的聚合机制逐层向上抽象,最终得到根节点,代表整个上下文的概要信息。4) 信息检索:利用构建好的语义树,可以高效地检索和利用上下文信息。
关键创新:AdmTree的关键创新在于其自适应的语义树结构。与传统的固定长度分割或全局压缩方法不同,AdmTree能够根据文本内容动态调整分割策略,从而更好地保留关键信息。此外,轻量级的聚合机制和冻结的LLM主干也降低了计算成本和训练难度。
关键设计:AdmTree的关键设计包括:1) 信息密度评估:采用某种指标(例如token的注意力权重)来衡量文本片段的信息密度,用于动态分割。2) 概要token生成:使用预训练的LLM生成每个片段的概要token,并进行微调。3) 聚合机制:设计轻量级的聚合函数,将子节点的概要信息合并成父节点的概要信息。4) 损失函数:设计合适的损失函数,例如对比学习损失或重构损失,以保证语义树的语义保真度。
🖼️ 关键图片
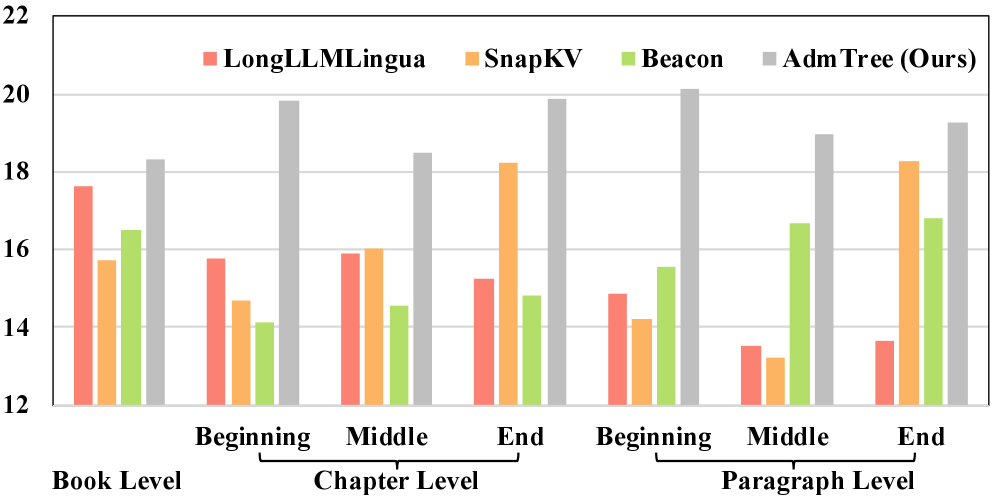
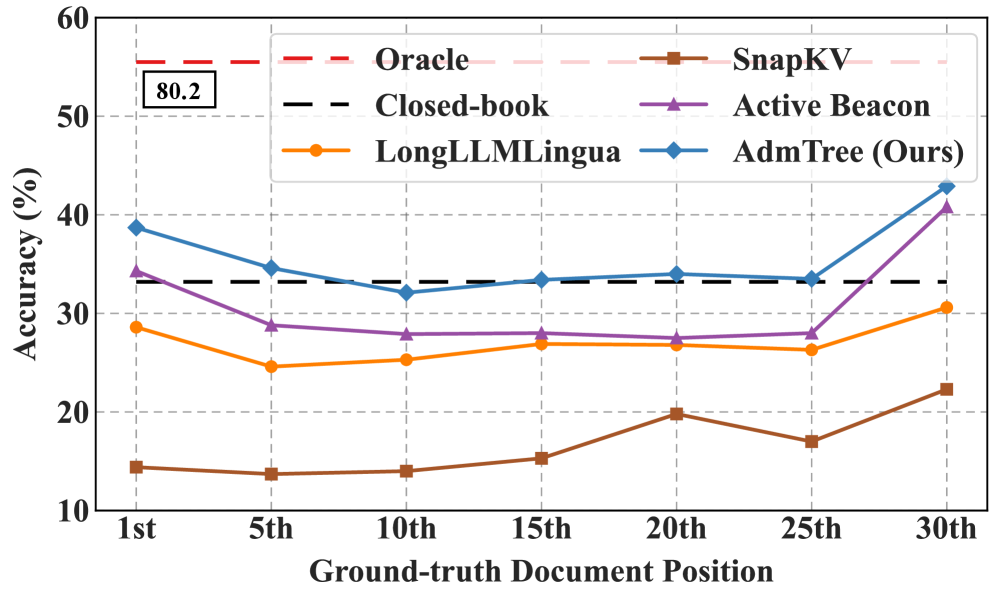
📊 实验亮点
论文提出的AdmTree在长文本上下文压缩任务上取得了显著的性能提升。具体实验结果(具体数值未知)表明,AdmTree在保持语义信息完整性的同时,能够有效降低计算复杂度,优于现有的上下文压缩方法(具体基线未知)。此外,AdmTree的轻量级设计使其易于部署和扩展。
🎯 应用场景
AdmTree可应用于需要处理长文本的各种场景,例如长文档摘要、问答系统、机器翻译、代码生成等。通过高效压缩长文本上下文,AdmTree能够显著提升LLM在这些任务中的性能和效率,降低计算成本,并支持处理更长的输入序列。未来,AdmTree有望成为LLM处理长文本的重要技术手段。
📄 摘要(原文)
The quadratic complexity of self-attention constrains Large Language Models (LLMs) in processing long contexts, a capability essential for many advanced applications. Context compression aims to alleviate this computational bottleneck while retaining critical semantic information. However, existing approaches often fall short: explicit methods may compromise local detail, whereas implicit methods can suffer from positional biases, information degradation, or an inability to capture long-range semantic dependencies. We propose AdmTree, a novel framework for adaptive, hierarchical context compression with a central focus on preserving high semantic fidelity while maintaining efficiency. AdmTree dynamically segments input based on information density, utilizing gist tokens to summarize variable-length segments as the leaves of a semantic binary tree. This structure, together with a lightweight aggregation mechanism and a frozen backbone LLM (thereby minimizing new trainable parameters), enables efficient hierarchical abstraction of the context. By preserving fine-grained details alongside global semantic coherence, mitigating positional bias, and dynamically adapting to content, AdmTree robustly retains the semantic information of long contexts.