AugServe: Adaptive Request Scheduling for Augmented Large Language Model Inference Serving
作者: Ying Wang, Zhen Jin, Jiexiong Xu, Wenhai Lin, Yiquan Chen, Wenzhi Chen
分类: cs.CL
发布日期: 2025-12-03 (更新: 2025-12-16)
💡 一句话要点
AugServe:为增强型大语言模型推理服务设计自适应请求调度框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 增强型大语言模型 推理服务 请求调度 自适应调度 动态批处理 有效吞吐量 服务质量
📋 核心要点
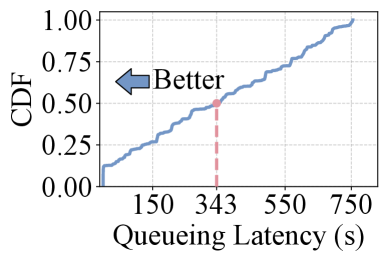
- 现有增强型LLM推理服务依赖FCFS调度,易产生队头阻塞,导致排队延迟超标,影响用户体验。
- AugServe提出两阶段自适应请求调度策略,结合推理特征和运行时信息,优化调度顺序,动态调整token批处理。
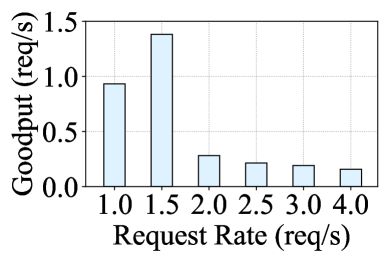
- 实验表明,AugServe有效吞吐量显著高于vLLM和InferCept,并大幅降低了首个token生成时间。
📝 摘要(中文)
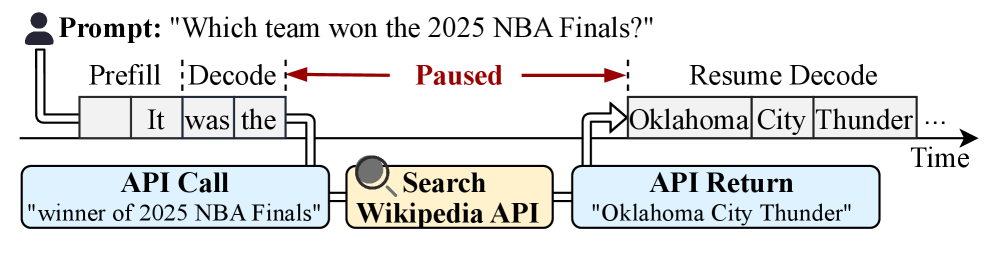
随着集成外部工具的增强型大语言模型(LLM)在Web应用中日益普及,提升增强型LLM推理服务效率和优化服务等级目标(SLO)对于改善用户体验至关重要。为了实现这一目标,推理系统必须在延迟约束内最大化请求处理量,即提高有效吞吐量。然而,现有系统面临两个主要挑战:(i)依赖先来先服务(FCFS)调度导致严重的队头阻塞,使得许多请求的排队延迟超过SLO;(ii)静态批处理token限制无法适应波动的负载和硬件条件。这两个因素都会降低有效吞吐量和服务质量。本文提出了AugServe,一个旨在减少排队延迟并提高增强型LLM推理服务有效吞吐量的高效推理框架。AugServe的核心思想是两阶段自适应请求调度策略。具体而言,AugServe结合增强型LLM请求的推理特征来优化调度决策的顺序(阶段I)。这些决策通过运行时信息不断完善(阶段II),从而适应请求特征和系统能力。此外,AugServe根据硬件状态和实时负载动态调整token批处理机制,进一步提高吞吐量性能。实验结果表明,AugServe的有效吞吐量比vLLM和InferCept分别高4.7倍和3.3倍,同时将首个token生成时间(TTFT)分别降低高达96.3%和95.0%。
🔬 方法详解
问题定义:论文旨在解决增强型大语言模型推理服务中,由于传统的先来先服务(FCFS)调度策略和静态的token批处理机制导致的排队延迟过高和有效吞吐量不足的问题。现有方法无法有效适应请求特征和系统负载的变化,导致服务质量下降。
核心思路:AugServe的核心思路是采用两阶段自适应请求调度策略,并结合动态token批处理机制,以优化请求处理顺序,减少排队延迟,并充分利用硬件资源。通过考虑请求的推理特征和系统运行时信息,实现更智能的调度决策。
技术框架:AugServe框架包含两个主要阶段:阶段I的推理特征驱动的请求排序和阶段II的运行时信息指导的调度优化。此外,框架还包含一个动态token批处理模块,根据硬件状态和实时负载调整批处理大小。整体流程为:接收请求 -> 提取推理特征 -> 阶段I排序 -> 阶段II优化 -> 动态批处理 -> 模型推理 -> 返回结果。
关键创新:AugServe的关键创新在于其两阶段自适应请求调度策略。与传统的静态调度策略不同,AugServe能够根据请求的推理特征(例如,请求所需的外部工具数量、请求的复杂度等)和系统的运行时状态(例如,GPU利用率、内存占用等)动态调整调度决策。这种自适应性使得AugServe能够更好地应对不同的请求负载和硬件条件。
关键设计:AugServe在阶段I中,可能使用机器学习模型(例如,排序学习模型)来预测请求的优先级,并根据优先级进行排序。在阶段II中,可能使用强化学习或PID控制器等方法,根据系统状态动态调整调度参数。动态token批处理模块可能采用基于规则或基于模型的策略,根据硬件资源和请求负载调整批处理大小。具体的损失函数和网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AugServe在有效吞吐量方面显著优于现有方法。与vLLM相比,AugServe的有效吞吐量提高了4.7倍;与InferCept相比,提高了3.3倍。同时,AugServe还大幅降低了首个token生成时间(TTFT),与vLLM和InferCept相比,分别降低了高达96.3%和95.0%。这些数据表明AugServe在提升增强型LLM推理服务性能方面具有显著优势。
🎯 应用场景
AugServe可应用于各种需要高性能和低延迟的增强型大语言模型推理服务场景,例如智能客服、AI助手、自动化报告生成等。通过提高推理效率和优化服务质量,AugServe能够提升用户体验,降低运营成本,并促进增强型LLM在实际应用中的广泛部署。
📄 摘要(原文)
As augmented large language models (LLMs) with external tools become increasingly popular in web applications, improving augmented LLM inference serving efficiency and optimizing service-level objectives (SLOs) are critical for enhancing user experience. To achieve this, inference systems must maximize request handling within latency constraints, referred to as increasing effective throughput. However, existing systems face two major challenges: (i) reliance on first-come-first-served (FCFS) scheduling causes severe head-of-line blocking, leading to queuing delays exceeding the SLOs for many requests; and (ii) static batch token limit, which fails to adapt to fluctuating loads and hardware conditions. Both of these factors degrade effective throughput and service quality. This paper presents AugServe, an efficient inference framework designed to reduce queueing latency and enhance effective throughput for augmented LLM inference services. The core idea of AugServe is a two-stage adaptive request scheduling strategy. Specifically, AugServe combines the inference features of augmented LLM requests to optimize the order of scheduling decisions (stage I). These decisions are continuously refined with runtime information (stage II), adapting to both request characteristics and system capabilities. In addition, AugServe dynamically adjusts the token batching mechanism based on hardware status and real-time load, further enhancing throughput performance. Experimental results show that AugServe achieves 4.7x and 3.3x higher effective throughput than vLLM and InferCept, while reducing time-to-first-token (TTFT) by up to 96.3% and 95.0%, respectively.