Adapting Large Language Models to Low-Resource Tibetan: A Two-Stage Continual and Supervised Fine-Tuning Study
作者: Lifeng Chen, Ryan Lai, Tianming Liu
分类: cs.CL
发布日期: 2025-12-03
💡 一句话要点
提出两阶段微调方法,提升大语言模型在低资源藏语上的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低资源语言 藏语 大语言模型 持续预训练 监督微调 机器翻译 语言适配
📋 核心要点
- 低资源语言数据稀缺和跨语言差异导致现有大语言模型难以有效迁移。
- 采用持续预训练和监督微调两阶段策略,提升模型在藏语上的语言理解和翻译能力。
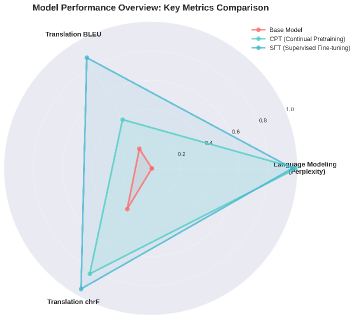
- 实验表明,该方法显著降低了困惑度,并大幅提升了汉藏翻译的BLEU和chrF值。
📝 摘要(中文)
由于数据稀缺和跨语言漂移,将大型语言模型(LLMs)适配到低资源语言仍然是一个主要挑战。本文提出了一种两阶段方法,将Qwen2.5-3B适配到藏语这种形态丰富且代表性不足的语言。我们采用持续预训练(CPT)来建立藏语的语言基础,然后进行监督微调(SFT)以实现任务和翻译的专业化。实验评估表明,困惑度持续降低(从2.98降至1.54),并且汉藏翻译质量显着提高(BLEU:0.046增至0.261;chrF:2.2增至6.6)。对Qwen3-4B中435层的逐层分析表明,适配主要集中在嵌入层和输出头,而中后期的MLP投影编码特定领域的转换。我们的研究结果表明,CPT构建了一个藏语语义流形,而SFT通过最小的表征扰动来锐化任务对齐。这项研究首次对LLM的藏语适配动态进行了定量探索,并为将多语言基础模型扩展到低资源环境提供了一个开放的、可复现的框架。
🔬 方法详解
问题定义:论文旨在解决低资源语言(特别是藏语)的大语言模型适配问题。现有方法在低资源语言上表现不佳,主要痛点在于数据稀缺导致的语言知识不足,以及跨语言迁移带来的语义漂移。
核心思路:核心思路是分阶段进行模型适配。首先通过持续预训练(CPT)让模型学习藏语的语言特性,建立藏语的语义基础。然后,通过监督微调(SFT)使模型专注于特定任务(如翻译),从而提高任务性能。这种分阶段的方法旨在解耦语言学习和任务学习,避免在数据有限的情况下出现过拟合。
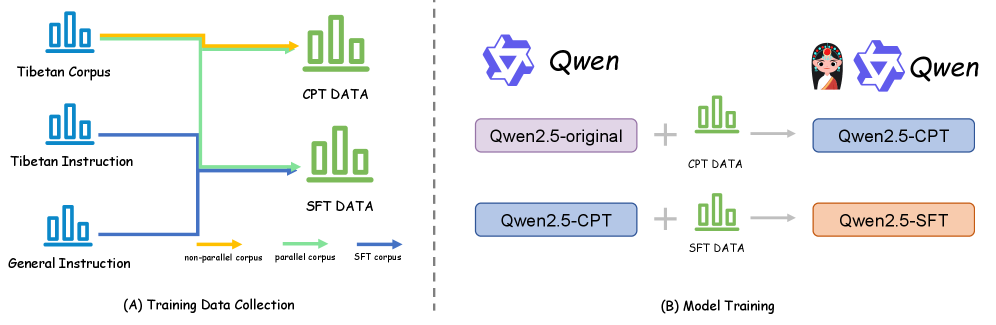
技术框架:整体框架包含两个主要阶段:1) 持续预训练(CPT):使用藏语语料对Qwen2.5-3B进行持续预训练,目标是让模型学习藏语的词汇、语法和语义知识。2) 监督微调(SFT):使用汉藏平行语料对预训练后的模型进行监督微调,目标是提高汉藏翻译的质量。
关键创新:该方法的主要创新在于两阶段适配策略,将语言学习和任务学习分离。通过持续预训练,模型能够更好地理解藏语的语言特性,从而为后续的监督微调奠定基础。此外,论文还对模型不同层在适配过程中的作用进行了分析,发现嵌入层和输出头在适配过程中起着关键作用。
关键设计:CPT阶段使用标准的语言模型训练目标,即预测下一个词。SFT阶段使用交叉熵损失函数,优化翻译结果与目标翻译之间的差异。论文还分析了Qwen3-4B的435层,发现适配主要集中在embedding和output heads,mid-late MLP projections编码领域特定的转换。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够显著提升大语言模型在藏语上的性能。困惑度从2.98降低到1.54,汉藏翻译的BLEU值从0.046提升到0.261,chrF值从2.2提升到6.6。这些结果表明,该方法能够有效地提高模型在藏语上的语言理解和翻译能力,优于直接进行监督微调的方法。
🎯 应用场景
该研究成果可应用于机器翻译、藏语语音识别、藏语文本生成等领域,有助于促进藏语的信息化和智能化发展。该方法为其他低资源语言的大语言模型适配提供了借鉴,具有重要的实际价值和推广意义。未来可进一步探索更有效的低资源语言适配方法,并将其应用于更广泛的自然语言处理任务。
📄 摘要(原文)
Adapting large language models (LLMs) to low-resource languages remains a major challenge due to data scarcity and cross-lingual drift. This work presents a two-stage adaptation of Qwen2.5-3B to Tibetan, a morphologically rich and underrepresented language. We employ Continual Pretraining (CPT) to establish Tibetan linguistic grounding, followed by Supervised Fine-Tuning (SFT) for task and translation specialization. Empirical evaluations demonstrate a consistent decrease in perplexity (from 2.98 $\rightarrow$ 1.54) and substantial improvements in Chinese$\rightarrow$Tibetan translation quality (BLEU: 0.046 $\rightarrow$ 0.261; chrF: 2.2 $\rightarrow$ 6.6). Layer-wise analysis across 435 layers in Qwen3-4B reveals that adaptation primarily concentrates on embedding and output heads, with mid--late MLP projections encoding domain-specific transformations. Our findings suggest that CPT constructs a Tibetan semantic manifold while SFT sharpens task alignment with minimal representational disruption. This study provides the first quantitative exploration of Tibetan adaptation dynamics for LLMs, and offers an open, reproducible framework for extending multilingual foundation models to low-resource settings.