Improving Alignment Between Human and Machine Codes: An Empirical Assessment of Prompt Engineering for Construct Identification in Psychology
作者: Kylie L. Anglin, Stephanie Milan, Brittney Hernandez, Claudia Ventura
分类: cs.CL
发布日期: 2025-12-03
备注: 22 pages, 2 figures
💡 一句话要点
提出一种基于提示工程的框架,提升LLM在心理学构念识别任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示工程 大型语言模型 心理学构念识别 文本分类 少样本学习
📋 核心要点
- 大型语言模型在文本分类任务中表现出色,但其性能高度依赖于提示语的设计,尤其是在心理学等专业领域。
- 该研究提出一个经验框架,通过提示工程优化LLM在心理学构念识别任务中的性能,旨在提升模型输出与专家判断的一致性。
- 实验结果表明,结合代码手册引导的经验提示选择和自动提示工程的少样本提示,能够取得与专家判断最一致的分类结果。
📝 摘要(中文)
大型语言模型(LLM)由于其架构和庞大的预训练数据,展现出强大的文本分类性能。然而,LLM的输出(此处指分配给文本的类别)严重依赖于提示语的措辞。虽然关于提示工程的文献正在扩展,但很少有研究关注分类任务,更少的研究涉及心理学等领域,在这些领域中,构念具有精确的、理论驱动的定义,这些定义可能在预训练数据中没有得到很好的体现。我们提出了一个经验框架,用于通过提示工程优化LLM在文本中识别构念的性能。我们通过零样本和少样本分类,实验性地评估了五种提示策略——代码手册引导的经验提示选择、自动提示工程、角色提示、思维链推理和解释性提示。我们发现,角色、思维链和解释并不能完全解决伴随措辞不当的提示而来的性能损失。相反,提示语中最有影响力的特征是构念定义、任务框架,以及在较小程度上提供的示例。在三个构念和两个模型中,与专家判断最一致的分类结果来自结合了代码手册引导的经验提示选择和自动提示工程的少样本提示。基于我们的发现,我们建议研究人员生成和评估尽可能多的提示变体,无论是人工制作的、自动生成的,或者理想情况下两者兼而有之,并基于训练数据集中的经验性能选择提示和示例,并在保留集中验证最终方法。这种程序为优化LLM提示提供了一种实用、系统和理论驱动的方法,在与专家判断保持一致至关重要的设置中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在心理学构念识别任务中,由于提示语措辞不当导致的性能下降问题。现有方法缺乏系统性的提示工程方法,难以保证LLM输出与心理学领域专家判断的一致性。
核心思路:论文的核心思路是通过实验评估多种提示策略,并结合代码手册引导的经验提示选择和自动提示工程,寻找最优的提示语组合。这种方法强调基于经验数据选择提示语,而非仅仅依赖人工设计或理论推导。
技术框架:该研究采用经验性的评估框架,主要包含以下几个阶段: 1. 定义心理学构念,并准备相应的文本数据集。 2. 设计并实现五种提示策略:代码手册引导的经验提示选择、自动提示工程、角色提示、思维链推理和解释性提示。 3. 使用零样本和少样本分类,评估不同提示策略在LLM上的性能。 4. 分析实验结果,确定最优的提示语组合,并进行验证。
关键创新:该研究的关键创新在于: 1. 提出了一个系统性的提示工程框架,用于优化LLM在心理学构念识别任务中的性能。 2. 结合了代码手册引导的经验提示选择和自动提示工程,提升了提示语的有效性。 3. 通过实验评估多种提示策略,为研究人员提供了实用的提示工程指导。
关键设计:论文的关键设计包括: 1. 详细定义了心理学构念,并构建了高质量的文本数据集。 2. 精心设计了五种提示策略,涵盖了不同的提示工程方法。 3. 采用零样本和少样本分类,评估不同提示策略的性能。 4. 使用代码手册引导的经验提示选择,确保提示语与心理学理论相符。
🖼️ 关键图片

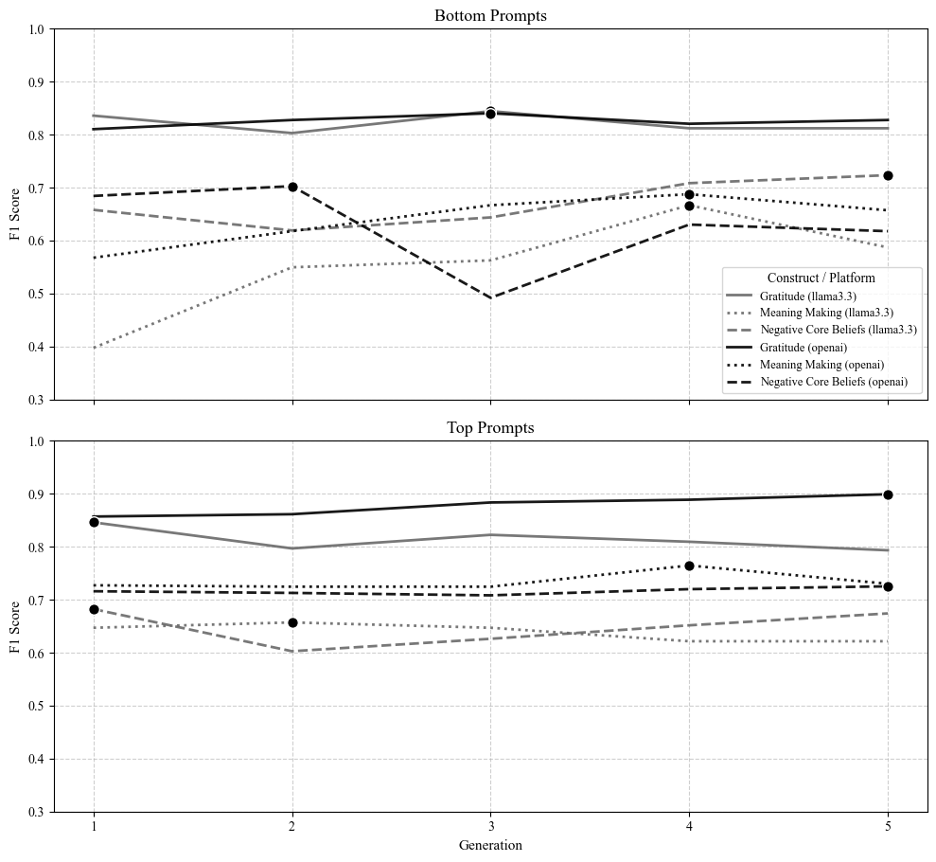
📊 实验亮点
实验结果表明,结合代码手册引导的经验提示选择和自动提示工程的少样本提示,能够显著提升LLM在心理学构念识别任务中的性能,使模型输出与专家判断更加一致。该方法在三个构念和两个模型上均取得了较好的效果,验证了其有效性和泛化能力。
🎯 应用场景
该研究成果可应用于心理学、教育学、社会科学等领域,辅助研究人员进行文本分析、情感识别、行为预测等任务。通过优化LLM的提示语,可以提升模型在专业领域的应用效果,减少人工干预,提高工作效率。未来,该方法有望推广到其他需要与专家知识对齐的领域。
📄 摘要(原文)
Due to their architecture and vast pre-training data, large language models (LLMs) demonstrate strong text classification performance. However, LLM output - here, the category assigned to a text - depends heavily on the wording of the prompt. While literature on prompt engineering is expanding, few studies focus on classification tasks, and even fewer address domains like psychology, where constructs have precise, theory-driven definitions that may not be well represented in pre-training data. We present an empirical framework for optimizing LLM performance for identifying constructs in texts via prompt engineering. We experimentally evaluate five prompting strategies --codebook-guided empirical prompt selection, automatic prompt engineering, persona prompting, chain-of-thought reasoning, and explanatory prompting - with zero-shot and few-shot classification. We find that persona, chain-of-thought, and explanations do not fully address performance loss accompanying a badly worded prompt. Instead, the most influential features of a prompt are the construct definition, task framing, and, to a lesser extent, the examples provided. Across three constructs and two models, the classifications most aligned with expert judgments resulted from a few-shot prompt combining codebook-guided empirical prompt selection with automatic prompt engineering. Based on our findings, we recommend that researchers generate and evaluate as many prompt variants as feasible, whether human-crafted, automatically generated, or ideally both, and select prompts and examples based on empirical performance in a training dataset, validating the final approach in a holdout set. This procedure offers a practical, systematic, and theory-driven method for optimizing LLM prompts in settings where alignment with expert judgment is critical.