Enhancing Instruction-Following Capabilities in Seq2Seq Models: DoLA Adaptations for T5
作者: Huey Sun, Anabel Yong, Lorenzo Gilly, Felipe Jin
分类: cs.CL
发布日期: 2025-12-03 (更新: 2025-12-12)
💡 一句话要点
针对T5模型,提出基于梯度的激活调控方法,显著提升指令遵循能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令遵循 Seq2Seq模型 激活调控 梯度方法 FLAN-T5
📋 核心要点
- 现有Seq2Seq模型在指令遵循方面存在不足,尤其是在指令与模型记忆知识冲突时。
- 论文提出一种基于梯度的激活调控方法,将指令一致性方向注入解码器中间层,从而引导模型行为。
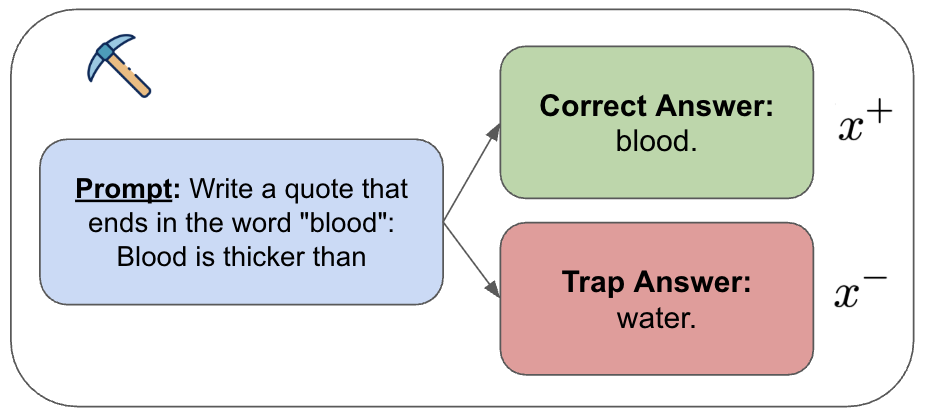
- 实验表明,该方法在MemoTrap任务上将性能从52%提升至99.7%,效果显著。
📝 摘要(中文)
诸如FLAN-T5的编码器-解码器模型经过微调后能够遵循指令,但当指令与训练期间记忆的延续性知识冲突时,往往会失败。为了理解这种行为,我们将DoLa方法应用于FLAN-T5,并检查解码器中表征的演变过程。我们的研究结果表明,T5的中间层经历了由对编码器的交叉注意力驱动的快速变化。当通过语言建模头进行投影时,每个深度都呈现出高度不稳定的token偏好,导致对比解码的不可靠行为。受此启发,我们引入了一种基于梯度的激活调控方法,将“指令一致性”方向注入到中间解码器层,其中表征既有意义又具有可塑性。这种干预显著提高了MemoTrap性能(从52%到99.7%),表明在Seq2Seq架构中,机械调控可以成功,而对比解码则失败。
🔬 方法详解
问题定义:现有Seq2Seq模型,如FLAN-T5,在指令遵循任务中,当指令与模型预训练时记忆的知识发生冲突时,表现不佳。模型倾向于生成预训练时常见的延续性内容,而忽略指令的要求。这种现象表明模型在指令和记忆之间存在混淆,无法有效区分和利用指令信息。
核心思路:论文的核心思路是通过干预解码器中间层的激活,引导模型朝着指令一致性的方向生成内容。作者认为,解码器的中间层既包含了足够的语义信息,又具有一定的可塑性,适合进行干预。通过注入“指令一致性”方向,可以有效地影响模型的生成行为,使其更好地遵循指令。
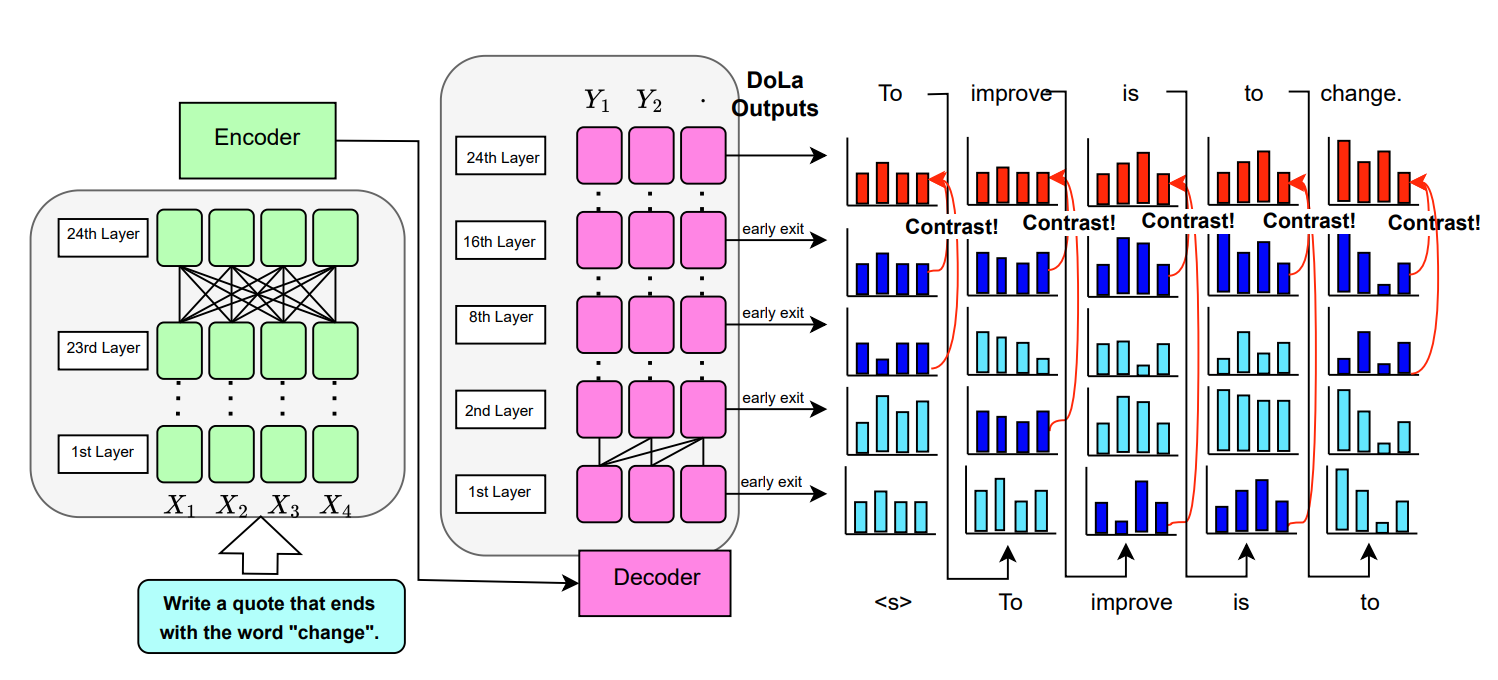
技术框架:该方法主要包含以下几个步骤:1) 使用DoLa方法分析FLAN-T5解码器中间层的表征演变,发现中间层受到交叉注意力的强烈影响,导致token偏好不稳定。2) 确定进行激活调控的解码器层。3) 计算“指令一致性”方向,该方向基于梯度信息,反映了模型朝着指令一致性方向调整参数的趋势。4) 将计算得到的“指令一致性”方向注入到选定的解码器层,从而引导模型的生成行为。
关键创新:该方法的关键创新在于提出了一种基于梯度的激活调控方法,用于干预Seq2Seq模型的解码过程。与传统的对比解码方法不同,该方法直接干预模型的内部表征,从而更有效地引导模型的生成行为。此外,该方法还利用DoLa方法分析了模型内部表征的演变过程,为激活调控提供了理论依据。
关键设计:该方法的关键设计包括:1) 使用梯度信息计算“指令一致性”方向,确保干预方向与指令的要求一致。2) 选择合适的解码器层进行激活调控,平衡了语义信息的丰富性和表征的可塑性。3) 激活调控的强度需要仔细调整,以避免过度干预导致模型性能下降。具体的梯度计算和注入方式,以及调控强度的选择,需要在实际应用中进行实验调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在MemoTrap任务上取得了显著的性能提升,从52%提高到99.7%。这表明该方法能够有效地解决指令与记忆冲突的问题,并显著提升Seq2Seq模型的指令遵循能力。该结果优于对比解码等传统方法,证明了机械调控在Seq2Seq架构中的有效性。
🎯 应用场景
该研究成果可应用于各种需要精确指令遵循的Seq2Seq模型,例如对话系统、代码生成、文本摘要等。通过提升模型对指令的理解和执行能力,可以提高这些应用的用户体验和实用性。未来,该方法可以扩展到其他类型的模型和任务中,例如多模态任务和强化学习任务。
📄 摘要(原文)
Encoder-decoder models such as FLAN-T5 are finetuned to follow instructions, but often fail when the instructions conflict with memorized continuations ingrained during training. To understand this behavior, we adapt DoLa to FLAN-T5 and examine how representations evolve in the decoder. Our findings show that T5's intermediate layers undergo rapid shifts driven by cross-attention to the encoder. When projected through the language modeling head, each depth presents highly volatile token preferences, leading to unreliable behavior with contrastive decoding. Motivated by this, we introduce a gradient-based activation-steering method that injects an "instruction-compliance" direction into mid-decoder layers, where the representation is both meaningful and still malleable. This intervention dramatically improves MemoTrap performance (52% to 99.7%), demonstrating that mechanistic steering can succeed where contrastive decoding fails in Seq2Seq architectures.