Principled RL for Diffusion LLMs Emerges from a Sequence-Level Perspective
作者: Jingyang Ou, Jiaqi Han, Minkai Xu, Shaoxuan Xu, Jianwen Xie, Stefano Ermon, Yi Wu, Chongxuan Li
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-12-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出ESPO,解决扩散LLM中序列层面强化学习的难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 强化学习 序列生成 ELBO 策略优化
📋 核心要点
- 扩散LLM缺乏token级别的条件概率,使得传统的token级别强化学习方法难以直接应用。
- ESPO将整个序列生成视为一个动作,利用ELBO作为序列级别似然的代理,进行策略优化。
- 实验表明,ESPO在数学推理、编码和规划任务上显著优于token级别的基线方法。
📝 摘要(中文)
强化学习已被证明对自回归语言模型非常有效,但将这些方法应用于扩散大型语言模型(dLLM)提出了根本性的挑战。核心困难在于似然近似:自回归模型自然地提供token级别的条件概率,这对于token级别的RL目标(例如,GRPO)至关重要,而dLLM通过迭代的非自回归去噪步骤生成序列,缺乏这种分解。为了解决这个根本性的不匹配,我们提出了基于ELBO的序列级别策略优化(ESPO),这是一个原则性的RL框架,它将整个序列生成视为一个单一的动作,并使用ELBO作为可处理的序列级别似然代理。我们的方法结合了重要性比率的per-token归一化和鲁棒的KL散度估计,以确保稳定的大规模训练。在数学推理、编码和规划任务上的大量实验表明,ESPO显著优于token级别的基线,在Countdown任务上实现了20-40分的显著改进,同时在数学和编码基准上保持了一致的收益。我们的方法将序列级别优化确立为dLLM中RL的一种原则性和经验有效的范例。
🔬 方法详解
问题定义:现有基于强化学习的语言模型主要集中在自回归模型上,这些模型能够自然地提供token级别的条件概率,从而方便进行token级别的策略优化。然而,扩散LLM通过迭代的非自回归去噪过程生成序列,缺乏这种token级别的概率分解,使得直接应用token级别的强化学习方法变得困难。因此,如何为扩散LLM设计有效的强化学习方法是一个关键问题。
核心思路:ESPO的核心思路是将整个序列的生成过程视为一个单一的动作,从而避免了对token级别条件概率的依赖。通过使用ELBO(Evidence Lower Bound)作为序列级别似然的代理,ESPO能够对整个序列进行策略优化,而无需分解为token级别的优化。这种方法能够更好地适应扩散LLM的生成方式,从而实现更有效的强化学习。
技术框架:ESPO的整体框架包括以下几个主要步骤:1) 使用扩散LLM生成序列;2) 计算生成序列的ELBO值,作为序列级别似然的代理;3) 使用强化学习算法(如Policy Gradient)优化策略,目标是最大化ELBO值;4) 为了保证训练的稳定性,引入了per-token归一化和鲁棒的KL散度估计。
关键创新:ESPO最重要的创新点在于将序列级别的优化引入到扩散LLM的强化学习中。与传统的token级别优化方法不同,ESPO直接优化整个序列的生成过程,从而更好地适应扩散LLM的非自回归生成方式。此外,使用ELBO作为序列级别似然的代理也是一个关键创新,它提供了一种可行的序列级别策略优化方法。
关键设计:ESPO的关键设计包括:1) 使用ELBO作为奖励信号,指导序列级别的策略优化;2) 引入per-token归一化,以减小重要性采样的方差,提高训练的稳定性;3) 使用鲁棒的KL散度估计,防止策略更新过于激进,保证训练的收敛性。具体的损失函数包括ELBO损失、KL散度损失等。
🖼️ 关键图片

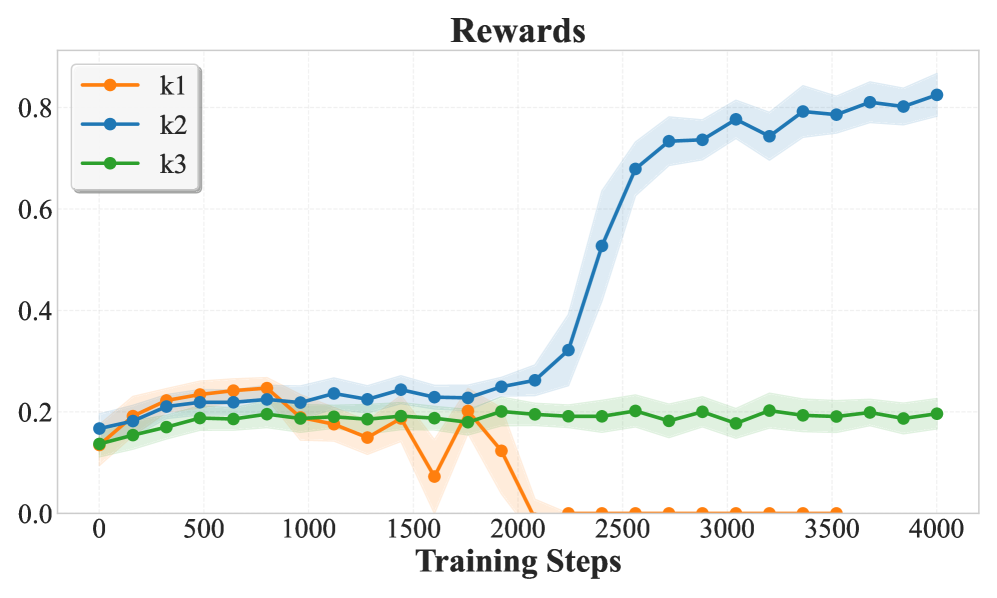
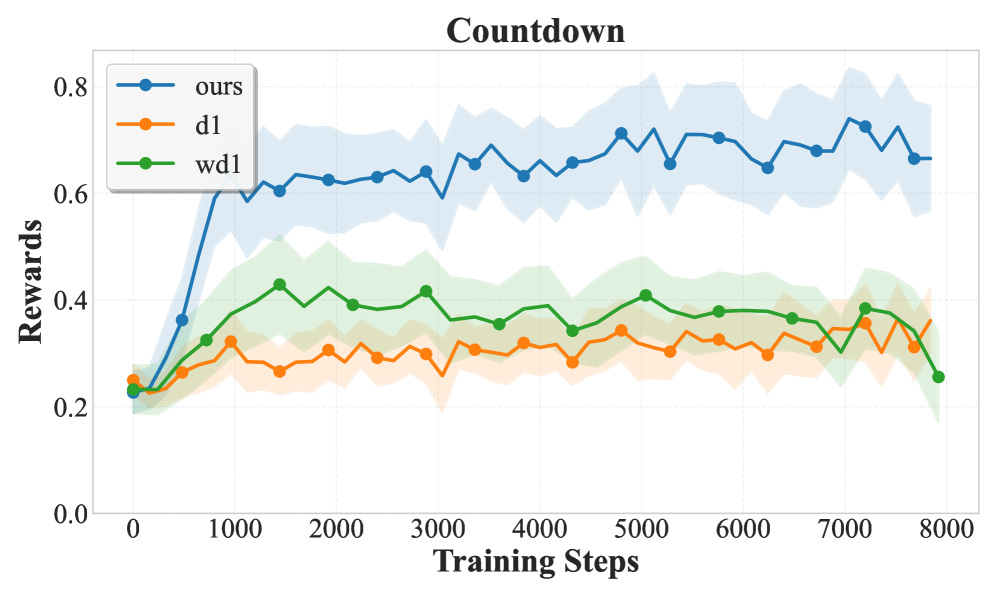
📊 实验亮点
ESPO在数学推理、编码和规划任务上取得了显著的性能提升。特别是在Countdown任务上,ESPO相比token级别的基线方法,实现了20-40分的巨大提升。同时,在数学和编码基准测试中,ESPO也保持了一致的性能提升,证明了其有效性和泛化能力。
🎯 应用场景
ESPO方法可以应用于各种需要序列生成的任务,例如数学推理、代码生成、规划等。通过强化学习,可以提升扩散LLM在这些任务上的性能,使其能够生成更准确、更符合要求的序列。该研究对于推动扩散模型在实际应用中的发展具有重要意义。
📄 摘要(原文)
Reinforcement Learning (RL) has proven highly effective for autoregressive language models, but adapting these methods to diffusion large language models (dLLMs) presents fundamental challenges. The core difficulty lies in likelihood approximation: while autoregressive models naturally provide token-level conditional probabilities essential for token-level RL objectives (e.g., GRPO), dLLMs generate sequences through iterative non-autoregressive denoising steps that lack this factorization. To address this fundamental mismatch, we propose ELBO-based Sequence-level Policy Optimization (ESPO), a principled RL framework that treats entire sequence generation as a single action and uses the ELBO as a tractable sequence-level likelihood proxy. Our method incorporates per-token normalization of importance ratios and robust KL-divergence estimation to ensure stable large-scale training. Extensive experiments on mathematical reasoning, coding, and planning tasks demonstrate that ESPO significantly outperforms token-level baselines, achieving dramatic improvements of 20-40 points on the Countdown task, while maintaining consistent gains on math and coding benchmarks. Our approach establishes sequence-level optimization as a principled and empirically effective paradigm for RL in dLLMs. Our code is available at https://github.com/ML-GSAI/ESPO.