A Preliminary Study on the Promises and Challenges of Native Top-$k$ Sparse Attention
作者: Di Xiu, Hongyin Tang, Bolin Rong, Lizhi Yan, Jingang Wang, Yifan Lu, Xunliang Cai
分类: cs.CL, cs.LG
发布日期: 2025-12-03
💡 一句话要点
提出原生Top-$k$稀疏注意力机制,加速长文本建模并提升LLM推理效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Top-$k$注意力 稀疏注意力 长文本建模 大型语言模型 推理加速
📋 核心要点
- 长文本建模中LLM推理成本高昂,限制了Agent和多模态应用的发展。
- 提出原生Top-$k$注意力机制,在解码和训练阶段仅保留与Query最相似的Top-$k$个Keys。
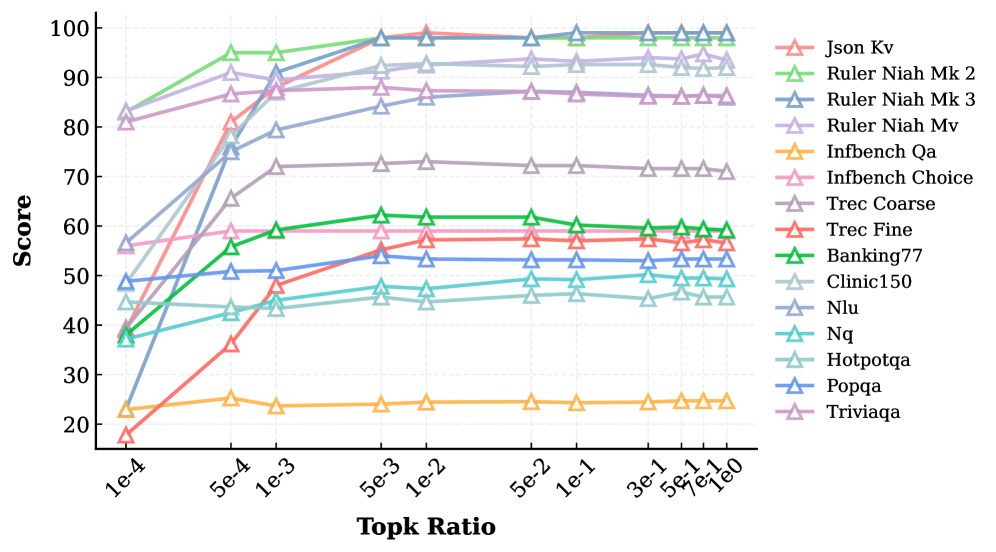
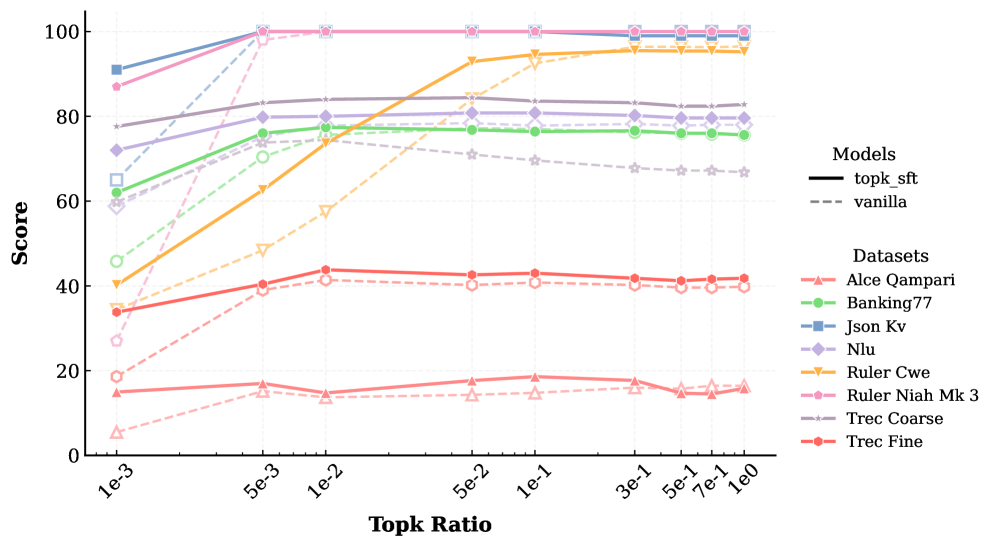
- 实验表明,Top-$k$解码在下游任务上可媲美甚至超越完整注意力,且训练与推理一致性可进一步提升性能。
📝 摘要(中文)
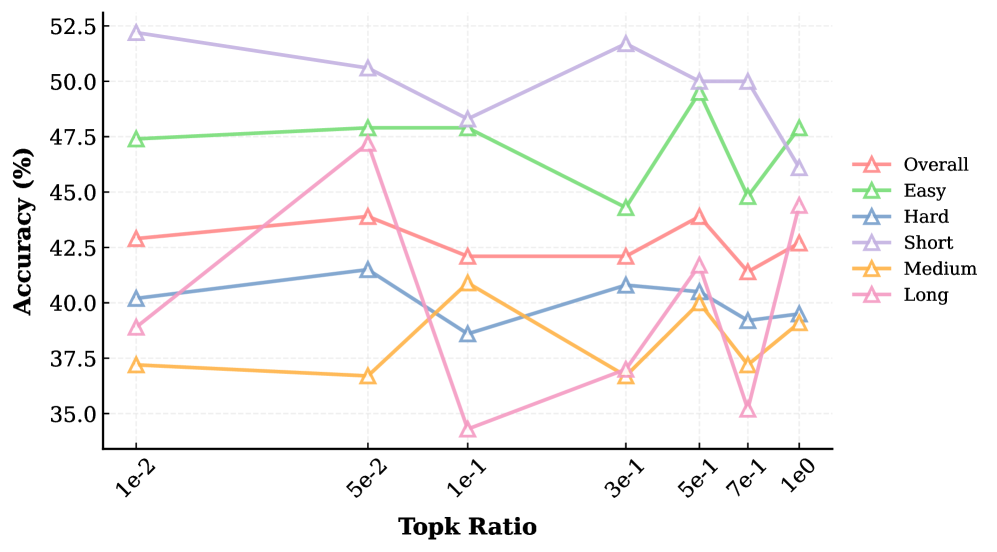
大型语言模型(LLMs)在长文本建模领域日益普及,但其推理计算成本已成为阻碍Agent和多模态应用等任务发展的关键瓶颈。本报告初步研究了Top-$k$注意力机制在解码和训练阶段的有效性和理论机制。首先,通过大量实验验证了精确Top-$k$解码的有效性。实验表明,在解码阶段仅保留与Query最相似的关键Keys作为上下文窗口,在HELMET和LongBench v2等下游任务上实现了与完整注意力相当甚至超越的性能。其次,进一步探索了原生Top-$k$注意力训练策略。实验证实,确保训练和推理在Top-$k$注意力操作上的一致性,有助于进一步释放Top-$k$解码的潜力,从而显著提高模型性能。此外,考虑到精确Top-$k$注意力的高计算复杂度,研究了近似Top-$k$算法精度对下游任务的影响。研究证实了下游任务性能与近似保真度之间存在正相关关系,并提供了DeepSeek-V3.2-Exp模型中Lightning Indexer精度的统计评估。最后,本报告从熵的角度提供了理论解释。实验观察表明,经过Top-$k$注意力SFT的模型在下游任务中表现出明显的熵降低现象,这验证了低熵状态更适合Top-$k$解码的假设。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本建模中推理计算成本过高的问题。现有方法,如完整注意力机制,计算复杂度随序列长度呈平方增长,成为实际应用的瓶颈。因此,如何降低计算复杂度,同时保持甚至提升模型性能,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用Top-$k$注意力机制,在计算注意力权重时,只考虑与Query最相关的Top-$k$个Keys。这样可以显著减少计算量,同时保留最重要的上下文信息。通过在训练和推理阶段保持Top-$k$注意力操作的一致性,进一步优化模型性能。
技术框架:整体框架包括两个主要阶段:Top-$k$解码和原生Top-$k$注意力训练。Top-$k$解码阶段,模型在推理时只关注与Query最相似的Top-$k$个Keys。原生Top-$k$注意力训练阶段,模型在训练时也使用Top-$k$注意力机制,以确保训练和推理的一致性。此外,论文还研究了近似Top-$k$算法对性能的影响,并从熵的角度对Top-$k$注意力机制进行了理论解释。
关键创新:最重要的技术创新点在于提出了原生Top-$k$注意力训练策略,即在训练阶段也使用Top-$k$注意力机制。这与以往的研究不同,以往的研究通常只在推理阶段使用稀疏注意力,而训练阶段仍然使用完整注意力。通过保持训练和推理的一致性,可以更好地释放Top-$k$解码的潜力。
关键设计:论文研究了精确Top-$k$和近似Top-$k$算法。对于近似Top-$k$算法,论文评估了Lightning Indexer在DeepSeek-V3.2-Exp模型中的精度,并分析了精度与下游任务性能之间的关系。此外,论文还从熵的角度分析了Top-$k$注意力机制对模型状态的影响,发现Top-$k$注意力SFT可以降低模型在下游任务中的熵。
🖼️ 关键图片
📊 实验亮点
实验结果表明,精确Top-$k$解码在HELMET和LongBench v2等下游任务上实现了与完整注意力相当甚至超越的性能。原生Top-$k$注意力训练策略进一步提升了模型性能。研究还证实了下游任务性能与近似Top-$k$算法精度之间存在正相关关系,并提供了DeepSeek-V3.2-Exp模型中Lightning Indexer精度的统计评估。
🎯 应用场景
该研究成果可广泛应用于需要处理长文本的场景,如智能客服、文档摘要、机器翻译、代码生成等。通过降低LLM的推理计算成本,可以加速这些应用的部署和推广,并为Agent和多模态应用等新兴领域提供更强大的支持。未来,该技术有望成为构建更高效、更智能的AI系统的关键组成部分。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly prevalent in the field of long-context modeling, however, their inference computational costs have become a critical bottleneck hindering the advancement of tasks such as agents and multimodal applications. This report conducts a preliminary investigation into the effectiveness and theoretical mechanisms of the Top-$k$ Attention mechanism during both the decoding and training phases. First, we validate the effectiveness of exact Top-$k$ Decoding through extensive experimentation. Experiments demonstrate that retaining only the pivotal Keys with the highest similarity to the Query as the context window during the decoding stage achieves performance comparable to, or even surpassing, full attention on downstream tasks such as HELMET and LongBench v2. Second, we further explore the native Top-$k$ Attention training strategy. Experiments confirm that ensuring the consistency between training and inference regarding Top-$k$ Attention operations facilitates the further unlocking of Top-$k$ Decoding's potential, thereby significantly enhancing model performance. Furthermore, considering the high computational complexity of exact Top-$k$ Attention, we investigate the impact of approximate Top-$k$ algorithm precision on downstream tasks. Our research confirms a positive correlation between downstream task performance and approximation fidelity, and we provide statistical evaluations of the Lightning Indexer's precision within the DeepSeek-V3.2-Exp model. Finally, this report provides a theoretical interpretation from the perspective of Entropy. Experimental observations indicate that models subjected to Top-$k$ Attention SFT exhibit a distinct phenomenon of entropy reduction in downstream tasks, which validates the hypothesis that low-entropy states are better adapted to Top-$k$ Decoding.