PretrainZero: Reinforcement Active Pretraining
作者: Xingrun Xing, Zhiyuan Fan, Jie Lou, Guoqi Li, Jiajun Zhang, Debing Zhang
分类: cs.CL
发布日期: 2025-12-03
💡 一句话要点
提出PretrainZero,通过强化主动学习框架提升预训练模型通用推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 主动学习 预训练 通用推理 自监督学习
📋 核心要点
- 现有大模型依赖特定领域的可验证奖励,限制了通用推理能力的扩展。
- PretrainZero通过强化主动学习,从预训练语料库中学习推理策略,无需标签和微调。
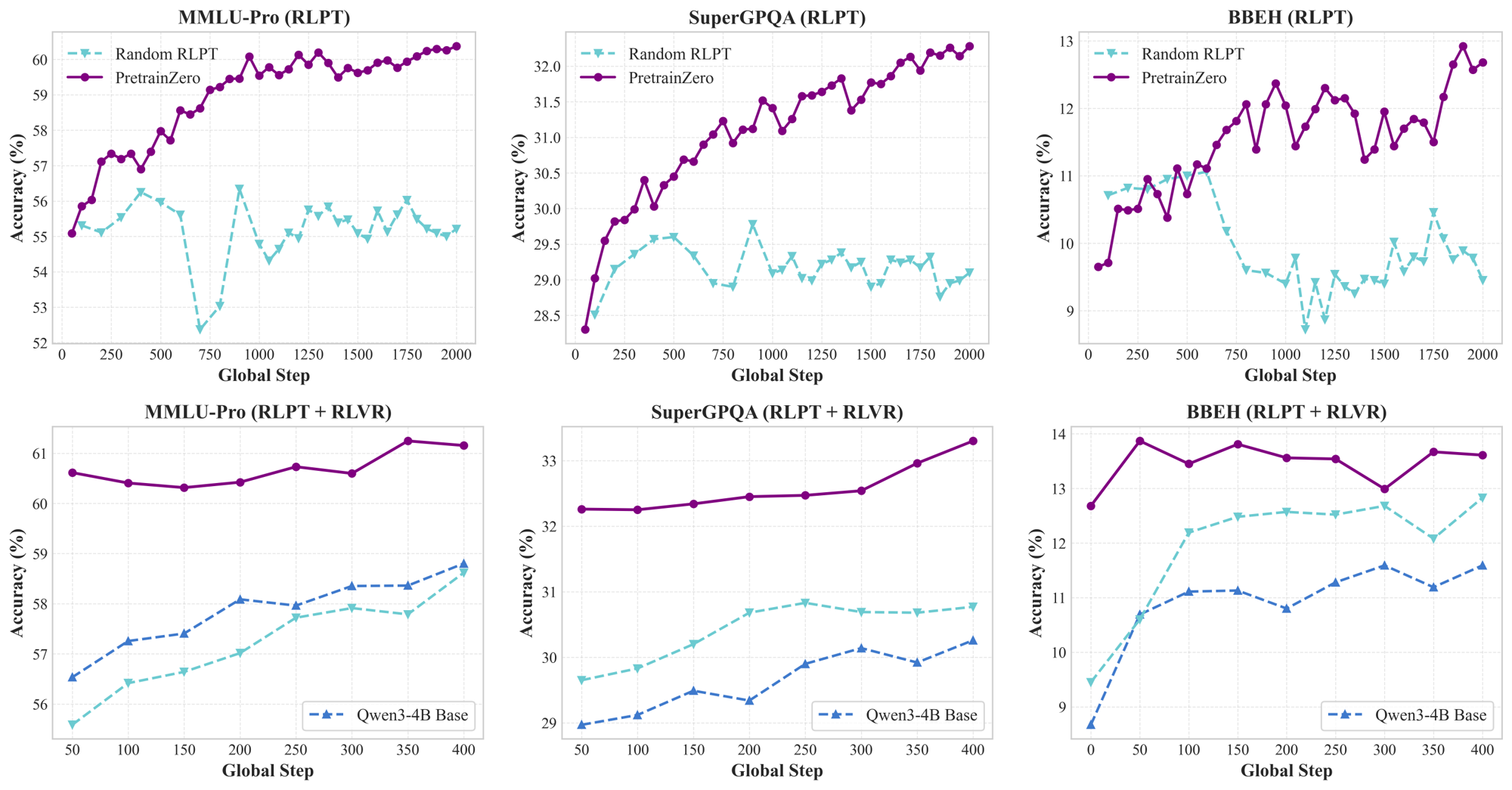
- 实验表明,PretrainZero显著提升了预训练模型在MMLU-Pro等基准上的通用推理能力。
📝 摘要(中文)
本文提出了PretrainZero,一个基于预训练语料库的强化主动学习框架,旨在将强化学习从特定领域的后训练扩展到通用预训练。PretrainZero具有以下特点:1) 主动预训练:模仿人类的主动学习能力,学习一个统一的推理策略,主动从预训练语料库中识别合理且信息丰富的内容,并通过强化学习推理预测这些内容。2) 自监督学习:无需任何可验证的标签、预训练的奖励模型或监督微调,直接使用强化学习在通用维基百科语料库上预训练3到30B的基础模型,显著打破了通用推理的验证数据壁垒。3) 验证扩展:通过处理越来越具有挑战性的掩码跨度,PretrainZero显著增强了预训练基础模型的通用推理能力。在强化预训练中,PretrainZero在MMLU-Pro、SuperGPQA和数学平均基准测试中,分别将Qwen3-4B-Base提高了8.43、5.96和10.60。在后训练中,预训练模型还可以作为下游RLVR任务的推理基础模型。
🔬 方法详解
问题定义:现有的大型语言模型在通用推理能力上仍然受限于对特定领域可验证奖励的依赖。这意味着模型需要在特定任务上进行大量的监督训练或强化学习微调才能获得较好的性能,而缺乏从通用经验中主动学习和推理的能力。因此,如何打破这种对特定领域数据的依赖,提升模型在更广泛领域的通用推理能力是一个关键问题。
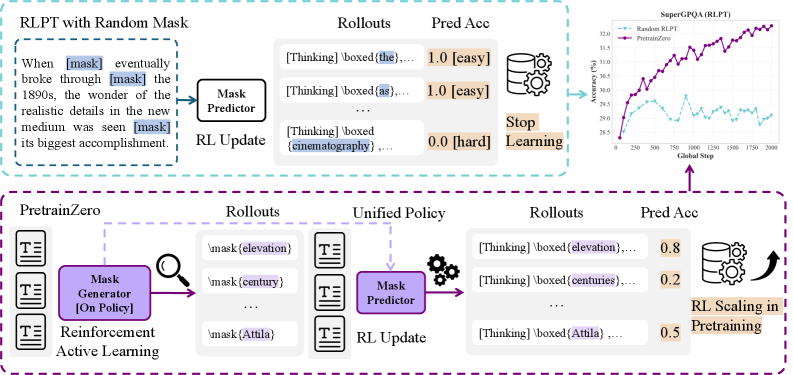
核心思路:PretrainZero的核心思路是模仿人类的主动学习能力,让模型能够从大量的预训练语料库中主动选择信息丰富且合理的片段进行学习和推理。通过强化学习的方式,训练一个策略来选择合适的学习内容,并预测这些内容,从而在没有显式标签的情况下提升模型的通用推理能力。
技术框架:PretrainZero的整体框架包含以下几个主要模块:1) 预训练语料库:使用通用的预训练语料库,例如维基百科。2) 强化学习策略:训练一个强化学习策略,用于从语料库中选择合适的片段进行学习。这个策略的目标是选择那些能够最大化模型推理能力的片段。3) 推理模型:使用预训练的基础模型作为推理模型,例如Qwen3-4B-Base。4) 奖励函数:设计一个奖励函数,用于评估模型在预测所选片段时的表现。这个奖励函数不需要显式的标签,而是基于模型自身的预测能力进行评估。
关键创新:PretrainZero的关键创新在于将强化学习应用于预训练阶段,实现了主动预训练。与传统的预训练方法不同,PretrainZero不是被动地学习语料库中的所有内容,而是主动选择信息丰富且合理的片段进行学习。此外,PretrainZero还实现了自监督学习,无需任何可验证的标签、预训练的奖励模型或监督微调。
关键设计:在强化学习策略的设计上,可以使用各种强化学习算法,例如PPO或DQN。奖励函数的设计可以基于模型预测的置信度或准确率。在训练过程中,可以通过调整掩码跨度的长度来控制学习的难度。例如,可以从较短的掩码跨度开始,逐渐增加到较长的掩码跨度,从而逐步提升模型的推理能力。
🖼️ 关键图片

📊 实验亮点
PretrainZero在MMLU-Pro、SuperGPQA和数学平均基准测试中,分别将Qwen3-4B-Base提高了8.43、5.96和10.60。这些结果表明,PretrainZero能够显著提升预训练模型的通用推理能力。值得注意的是,这些提升是在没有使用任何可验证标签的情况下实现的,这进一步证明了PretrainZero的有效性。
🎯 应用场景
PretrainZero具有广泛的应用前景,可以应用于各种需要通用推理能力的场景,例如智能问答、文本摘要、机器翻译等。通过提升模型的通用推理能力,可以使其在各种不同的任务上都表现出色,从而实现更通用的人工智能。此外,PretrainZero还可以作为下游强化学习任务的推理基础模型,为这些任务提供更好的初始化。
📄 摘要(原文)
Mimicking human behavior to actively learning from general experience and achieve artificial general intelligence has always been a human dream. Recent reinforcement learning (RL) based large-thinking models demonstrate impressive expert-level abilities, i.e., software and math, but still rely heavily on verifiable rewards in specific domains, placing a significant bottleneck to extend the performance boundary of general reasoning capabilities. In this work, we propose PretrainZero, a reinforcement active learning framework built on the pretraining corpus to extend RL from domain-specific post-training to general pretraining. PretrainZero features the following characteristics: 1) Active pretraining: inspired by the active learning ability of humans, PretrainZero learns a unified reasoning policy to actively identify reasonable and informative contents from pretraining corpus, and reason to predict these contents by RL. 2) Self-supervised learning: without any verifiable labels, pretrained reward models, or supervised fine-tuning, we directly pretrain reasoners from 3 to 30B base models on the general Wikipedia corpus using RL, significantly breaking the verification data-wall for general reasoning. 3) Verification scaling: by tackling increasingly challenging masked spans, PretrainZero substantially enhances the general reasoning abilities of pretrained base models. In reinforcement pretraining, PretrainZero improves Qwen3-4B-Base for 8.43, 5.96 and 10.60 on MMLU-Pro, SuperGPQA and math average benchmarks. In post-training, the pretrained models can also serve as reasoning foundation models for downstream RLVR tasks.