Variance-Aware LLM Annotation for Strategy Research: Sources, Diagnostics, and a Protocol for Reliable Measurement
作者: Arnaldo Camuffo, Alfonso Gambardella, Saeid Kazemi, Jakub Malachowski, Abhinav Pandey
分类: cs.CY, cs.CL
发布日期: 2025-12-02 (更新: 2026-01-19)
备注: 41 pages for the main paper 53 pages for appendix
💡 一句话要点
提出方差感知LLM标注协议,提升策略研究中文本标注的可靠性与可复现性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 文本标注 方差分析 策略研究 可复现性 计量经济学 标注协议
📋 核心要点
- 现有LLM文本标注方法忽略了LLM输出的不稳定性,导致结果方差大,影响研究结果的可靠性和可复现性。
- 论文提出一种方差感知的LLM标注协议,通过控制抽样、聚合和报告,降低标注结果的方差。
- 实验表明,细微的设计选择(如提示语措辞、模型选择)可能导致结果产生显著变化,强调了方差感知协议的重要性。
📝 摘要(中文)
大型语言模型(LLM)为策略研究人员提供了大规模文本标注的强大工具,但将LLM生成的标签视为确定性结果忽略了其显著的不稳定性。本文基于内容分析和泛化理论,诊断了五个方差来源:结构规范、界面效应、模型偏好、输出提取和系统级聚合。实证研究表明,细微的设计选择(如提示语措辞、模型选择)可能导致结果产生12-85个百分点的变化。这种方差不仅威胁到可复现性,还威胁到计量经济学识别:与协变量相关的标注误差会偏差参数估计,而与平均准确率无关。本文开发了一种方差感知协议,规定了抽样预算、聚合规则和报告标准,并界定了不应使用LLM标注的范围条件。这些贡献将基于LLM的标注从临时实践转变为可审计的测量基础设施。
🔬 方法详解
问题定义:现有基于LLM的文本标注方法通常将LLM的输出视为确定性的,忽略了LLM在标注过程中的不稳定性。这种不稳定性导致标注结果的方差较大,影响了研究结果的可靠性和可复现性。此外,标注误差如果与协变量相关,还会导致计量经济学分析中的参数估计偏差。
核心思路:论文的核心思路是识别并控制LLM标注过程中的方差来源,通过设计合理的标注协议,降低标注结果的方差,提高标注的可靠性。该协议强调对LLM输出进行多次抽样,并采用合适的聚合规则,以减少随机误差的影响。同时,该协议还强调对标注过程进行详细记录和报告,以便于其他研究者进行审计和复现。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 识别LLM标注过程中的方差来源,包括结构规范、界面效应、模型偏好、输出提取和系统级聚合;2) 设计方差感知的LLM标注协议,包括抽样预算、聚合规则和报告标准;3) 通过实证研究评估该协议的效果,并与其他标注方法进行比较;4) 界定该协议的适用范围,指出在哪些情况下不应使用LLM标注。
关键创新:该研究的关键创新在于提出了方差感知的LLM标注协议,该协议能够有效地控制LLM标注过程中的方差,提高标注的可靠性。与传统的LLM标注方法相比,该协议更加注重对标注过程的控制和管理,从而保证了标注结果的质量。此外,该研究还对LLM标注过程中的方差来源进行了深入的分析,为其他研究者提供了有益的参考。
关键设计:该研究的关键设计包括:1) 抽样预算:确定需要对每个文本进行多少次标注,以减少随机误差的影响;2) 聚合规则:选择合适的聚合方法,将多次标注结果合并为一个最终结果,例如,可以使用多数投票、平均值或加权平均值等方法;3) 报告标准:规定需要对标注过程进行哪些方面的记录和报告,例如,可以记录使用的LLM模型、提示语、抽样次数、聚合方法等。
🖼️ 关键图片
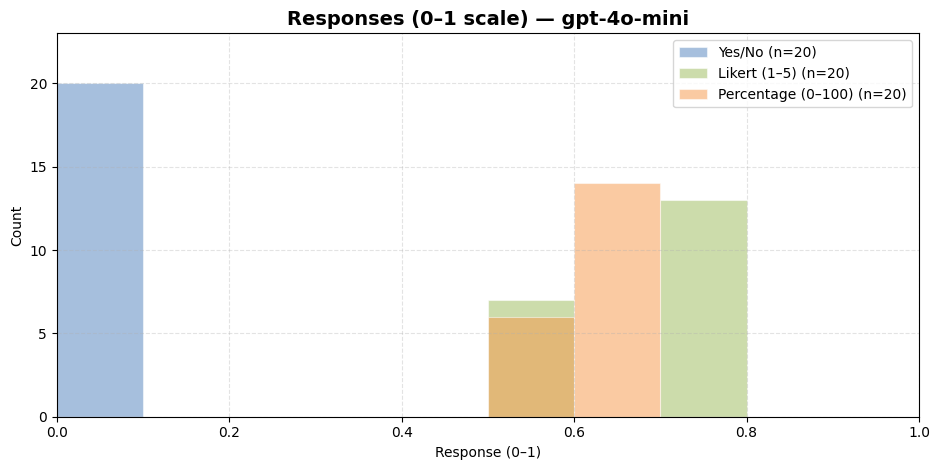
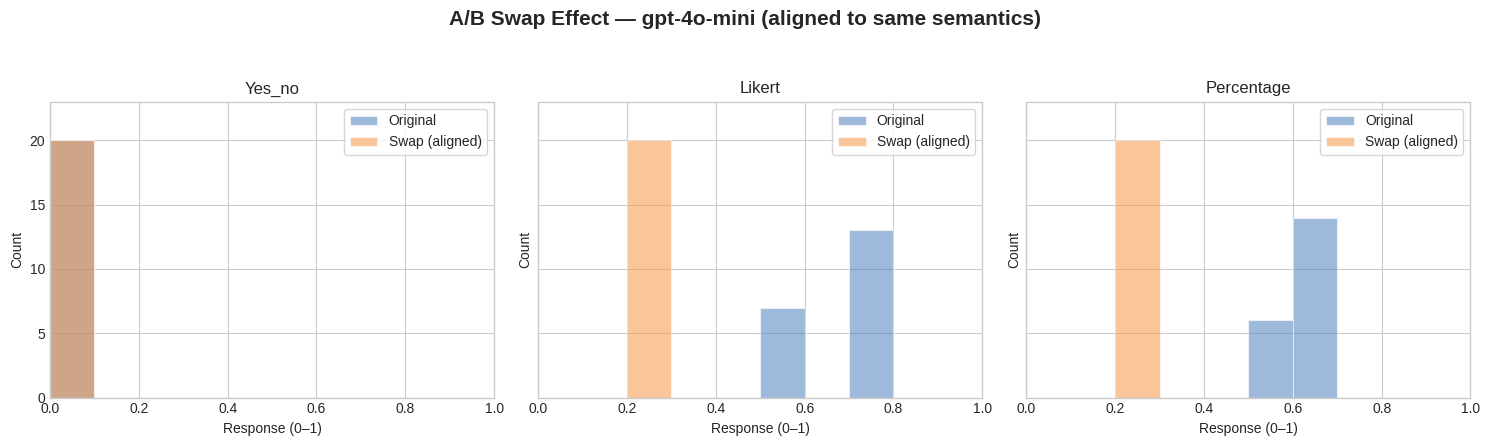
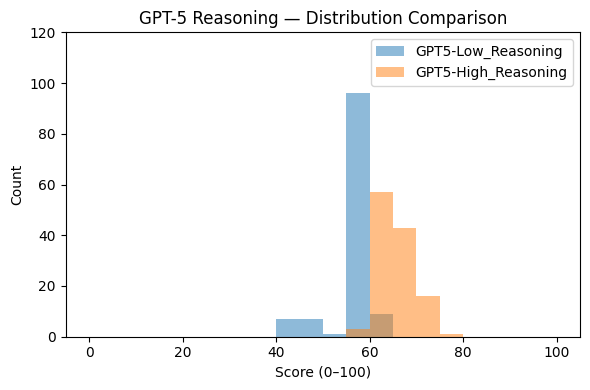
📊 实验亮点
研究表明,细微的设计选择(如提示语措辞、模型选择)可能导致标注结果产生12-85个百分点的变化,突出了方差感知协议的重要性。该协议通过控制抽样、聚合和报告,显著降低了标注结果的方差,提高了标注的可靠性。
🎯 应用场景
该研究成果可广泛应用于策略研究、市场营销、社会科学等领域,提升文本数据分析的质量和效率。通过使用方差感知的LLM标注协议,研究人员可以获得更可靠、更可复现的标注结果,从而提高研究结论的有效性。该研究还有助于推动LLM在文本标注领域的标准化和规范化,促进LLM技术的更广泛应用。
📄 摘要(原文)
Large language models (LLMs) offer strategy researchers powerful tools for annotating text at scale, but treating LLM-generated labels as deterministic overlooks substantial instability. Grounded in content analysis and generalizability theory, we diagnose five variance sources: construct specification, interface effects, model preferences, output extraction, and system-level aggregation. Empirical demonstrations show that minor design choices-prompt phrasing, model selection-can shift outcomes by 12-85 percentage points. Such variance threatens not only reproducibility but econometric identification: annotation errors correlated with covariates bias parameter estimates regardless of average accuracy. We develop a variance-aware protocol specifying sampling budgets, aggregation rules, and reporting standards, and delineate scope conditions where LLM annotation should not be used. These contributions transform LLM-based annotation from ad hoc practice into auditable measurement infrastructure.