Separating Constraint Compliance from Semantic Accuracy: A Novel Benchmark for Evaluating Instruction-Following Under Compression
作者: Rahul Baxi
分类: cs.CL, cs.AI
发布日期: 2025-12-02
备注: 19 pages, 9 figures; currently under peer review at TMLR
💡 一句话要点
提出CDCT基准,揭示压缩条件下LLM指令遵循中约束遵从与语义准确的权衡。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 指令遵循 提示压缩 约束遵从性 语义准确性 RLHF 基准测试
📋 核心要点
- 现有研究缺乏对提示压缩下LLM指令遵循能力下降的深入分析,尤其是在约束遵从性方面。
- 提出CDCT基准,独立评估压缩条件下LLM的约束遵从性和语义准确性,揭示性能下降的根本原因。
- 实验表明,RLHF训练的“helpful”行为是中等压缩下约束违反的主要原因,移除该信号可显著提升约束遵从性。
📝 摘要(中文)
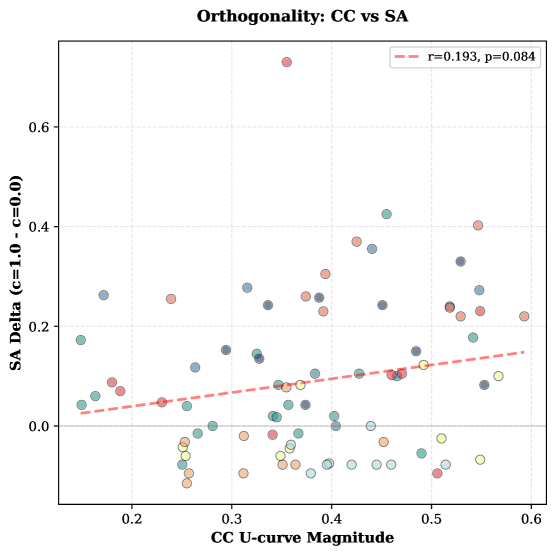
大型语言模型(LLM)在提示压缩下性能下降,但其机制尚不清楚。我们引入了压缩衰减理解测试(CDCT)基准,该基准独立测量跨压缩级别的约束遵从性(CC)和语义准确性(SA)。我们使用从极端(c=0.0,约2个词)到无(c=1.0,约135个词)的5个压缩级别评估了8个概念上的9个前沿LLM。一个由三个LLM组成的评审团在CC上实现了几乎完美的评分者间一致性(Fleiss' \k{appa}=0.90)。我们观察到约束遵从性方面普遍存在U型曲线模式(97.2%的普遍性),违规行为在中等压缩(c=0.5,约27个词)时达到峰值。与直觉相反,模型在极端压缩下的表现优于中等长度。这些维度在统计上是正交的(r=0.193,p=0.084),约束效应比语义效应大2.9倍。通过RLHF消融进行的实验验证证实了我们的约束显著性假设:移除“helpful”信号平均提高了598%的CC(71/72次试验,p<0.001),其中79%实现了完全遵从。这表明,经过RLHF训练的helpful行为是中等压缩下违反约束的主要原因。推理模型比高效模型的性能高27.5%(Cohen's d=0.96)。我们的研究结果揭示了RLHF对齐和指令遵循之间存在根本性的紧张关系,为改进已部署的系统提供了可操作的指导。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在提示压缩后,指令遵循能力下降的问题。现有方法难以区分是语义理解错误还是约束违反导致性能下降,缺乏细粒度的评估手段。
核心思路:论文的核心思路是将指令遵循能力分解为约束遵从性(Constraint Compliance, CC)和语义准确性(Semantic Accuracy, SA)两个维度,并设计基准测试独立评估这两个维度在不同压缩程度下的表现。通过这种方式,可以更清晰地理解压缩对LLM指令遵循的影响。
技术框架:论文提出了Compression-Decay Comprehension Test (CDCT)基准,包含以下几个关键组成部分: 1. 指令集:包含8个概念的指令,用于测试LLM的指令遵循能力。 2. 压缩级别:定义了5个压缩级别,从极端压缩到无压缩,模拟不同的信息损失程度。 3. 评估指标:定义了约束遵从性(CC)和语义准确性(SA)两个指标,用于独立评估LLM在不同维度上的表现。 4. LLM评审团:使用三个LLM组成评审团,对LLM的输出进行评估,确保评估的客观性和准确性。
关键创新:论文最重要的创新点在于提出了CDCT基准,能够独立测量约束遵从性和语义准确性。这使得研究人员可以更深入地理解压缩对LLM指令遵循的影响,并找到提高LLM在压缩条件下性能的方法。此外,论文还发现RLHF训练的“helpful”行为是中等压缩下约束违反的主要原因,这是一个重要的发现。
关键设计:CDCT基准的关键设计包括: 1. 指令设计:指令的设计需要同时考虑约束和语义信息,以便能够独立评估CC和SA。 2. 压缩策略:选择合适的压缩算法和压缩级别,模拟真实场景下的信息损失。 3. 评估流程:设计清晰的评估流程,确保评审团能够客观地评估LLM的输出。 4. RLHF消融实验:通过移除RLHF训练中的“helpful”信号,验证其对约束遵从性的影响。
🖼️ 关键图片


📊 实验亮点
实验结果表明,约束遵从性普遍存在U型曲线模式,在中等压缩时性能最差。移除RLHF训练中的“helpful”信号可显著提升约束遵从性,平均提高598%,79%的试验达到完全遵从。推理模型比高效模型性能高27.5%(Cohen's d=0.96)。
🎯 应用场景
该研究成果可应用于提升LLM在资源受限环境下的指令遵循能力,例如移动设备、边缘计算等场景。通过优化提示压缩策略和调整RLHF训练目标,可以提高LLM在信息不完整情况下的可靠性和实用性。此外,该基准也可用于评估和比较不同LLM在压缩条件下的性能。
📄 摘要(原文)
Large language models (LLMs) exhibit degraded performance under prompt compression, but the mechanisms remain poorly understood. We introduce the Compression-Decay Comprehension Test (CDCT), a benchmark that independently measures constraint compliance (CC) and semantic accuracy (SA) across compression levels. We evaluate 9 frontier LLMs across 8 concepts using 5 compression levels from extreme (c=0.0, ~2 words) to none (c=1.0, ~135 words). A three-judge LLM jury achieves almost perfect inter-rater agreement on CC (Fleiss' \k{appa}=0.90). We observe a universal U-curve pattern in constraint compliance (97.2% prevalence), with violations peaking at medium compression (c=0.5, ~27 words). Counterintuitively, models perform better at extreme compression than medium lengths. The dimensions are statistically orthogonal (r=0.193, p=0.084), with constraint effects 2.9x larger than semantic effects. Experimental validation via RLHF ablation confirms our constraint salience hypothesis: removing "helpfulness" signals improves CC by 598% on average (71/72 trials, p<0.001), with 79% achieving perfect compliance. This demonstrates that RLHF-trained helpfulness behaviors are the dominant cause of constraint violations at medium compression. Reasoning models outperform efficient models by 27.5% (Cohen's d=0.96). Our findings reveal a fundamental tension between RLHF alignment and instruction-following, providing actionable guidelines for improving deployed systems.