InvertiTune: High-Quality Data Synthesis for Cost-Effective Single-Shot Text-to-Knowledge Graph Generation
作者: Faezeh Faez, Marzieh S. Tahaei, Yaochen Hu, Ali Pourranjbar, Mahdi Biparva, Mark Coates, Yingxue Zhang
分类: cs.CL, cs.AI
发布日期: 2025-12-02
💡 一句话要点
InvertiTune:通过高质量数据合成,实现高性价比的单次文本到知识图谱生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到知识图谱生成 数据合成 监督微调 大型语言模型 知识库 单次生成 数据质量 泛化能力
📋 核心要点
- 现有Text2KG方法依赖迭代LLM提示,计算成本高,易忽略文本中的复杂关系。
- InvertiTune通过可控数据生成和监督微调,生成高质量训练数据,提升模型性能。
- 实验表明,InvertiTune在CE12k数据集上优于大型LLM和现有Text2KG方法,泛化性更强。
📝 摘要(中文)
大型语言模型(LLMs)极大地提升了理解和生成文本的能力,推动了从文本自动构建知识图谱(Text2KG)的显著进展。然而,许多Text2KG方法依赖于迭代式的LLM提示,计算成本高昂,且容易忽略文本中分布的复杂关系。为了解决这些限制,我们提出了InvertiTune,一个结合了可控数据生成流程和监督微调(SFT)的框架。该框架系统地从大型知识库中提取子图,应用噪声过滤,并利用LLM生成相应的自然文本描述,这项任务更符合LLM的能力,而非直接从文本生成KG。该流程能够生成包含更长文本和更大KG的数据集,更好地反映了真实世界的场景,从而支持轻量级模型进行有效的单次KG构建的SFT。在CE12k(一个使用我们提出的流程生成的数据集)上的实验结果表明,InvertiTune优于更大的非微调LLM以及最先进的Text2KG方法,同时在CrossEval-1200(一个由三个已建立的基准数据集和CE12k创建的测试集)上表现出更强的跨数据集泛化能力。这些发现突出了现实、高质量训练数据对于推进高效和高性能Text2KG系统的重要性。
🔬 方法详解
问题定义:论文旨在解决现有Text2KG方法中存在的计算成本高昂和难以捕捉复杂关系的问题。现有方法通常依赖于迭代式的LLM提示,这不仅耗费资源,而且在处理长文本和复杂关系时容易出现遗漏或错误。因此,需要一种更高效、更准确的Text2KG方法。
核心思路:InvertiTune的核心思路是通过高质量的数据合成和监督微调来训练轻量级模型,使其能够以单次(single-shot)的方式从文本中生成知识图谱。这种方法避免了迭代提示带来的高计算成本,并通过精心设计的数据生成流程来提升模型的性能和泛化能力。
技术框架:InvertiTune框架主要包含两个阶段:数据生成和模型微调。数据生成阶段首先从大型知识库中提取子图,然后应用噪声过滤来保证数据的质量。接着,利用LLM将这些子图转换为自然语言描述。模型微调阶段则使用生成的数据集对轻量级模型进行监督微调,使其能够从文本中直接生成知识图谱。
关键创新:InvertiTune的关键创新在于其数据生成流程。与以往直接从文本生成知识图谱不同,InvertiTune反向利用LLM,从知识图谱生成文本描述。这种方式更符合LLM的优势,能够生成更长、更复杂、更贴近真实场景的训练数据。此外,InvertiTune还通过噪声过滤等手段来保证数据的质量。
关键设计:在数据生成阶段,论文设计了特定的规则和策略来提取子图,并使用特定的prompt来指导LLM生成文本描述。噪声过滤可能涉及到一些阈值设定或规则,以去除低质量或不一致的数据。在模型微调阶段,选择合适的轻量级模型架构(具体架构未知)和损失函数(未知)对于最终性能至关重要。具体参数设置和网络结构细节在论文中可能有所描述,但摘要中未提及。
🖼️ 关键图片

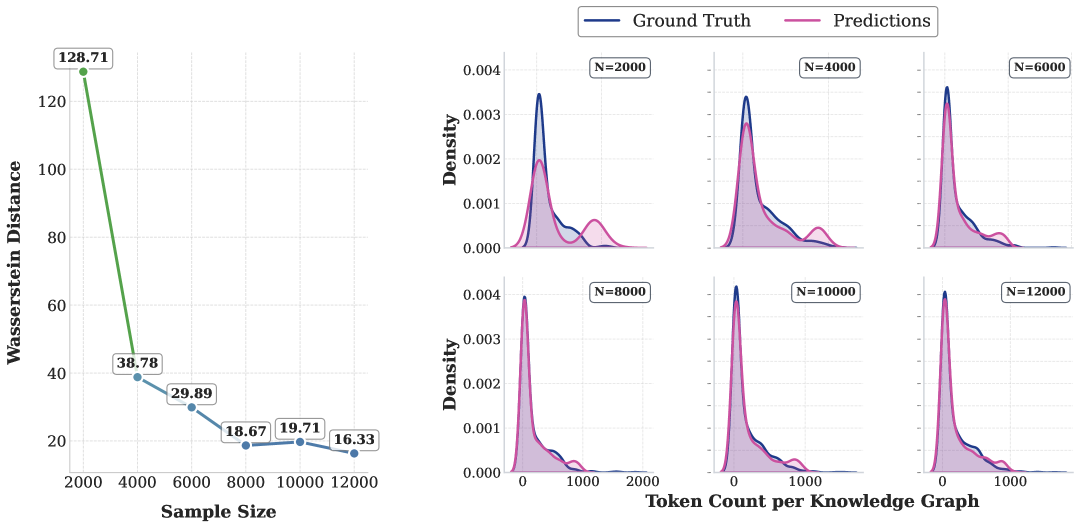

📊 实验亮点
InvertiTune在CE12k数据集上取得了显著的性能提升,优于大型非微调LLM以及最先进的Text2KG方法。此外,在CrossEval-1200数据集上的实验表明,InvertiTune具有更强的跨数据集泛化能力。这些结果表明,高质量的训练数据对于提升Text2KG系统的性能至关重要。
🎯 应用场景
InvertiTune可应用于多种需要从文本中提取知识的场景,例如信息抽取、问答系统、知识库构建和更新等。该方法能够降低知识图谱构建的成本,提高效率,并提升知识图谱的质量,从而为下游应用提供更好的支持。未来,该方法有望应用于更广泛的领域,例如智能客服、金融风控、医疗诊断等。
📄 摘要(原文)
Large Language Models (LLMs) have revolutionized the ability to understand and generate text, enabling significant progress in automatic knowledge graph construction from text (Text2KG). Many Text2KG methods, however, rely on iterative LLM prompting, making them computationally expensive and prone to overlooking complex relations distributed throughout the text. To address these limitations, we propose InvertiTune, a framework that combines a controlled data generation pipeline with supervised fine-tuning (SFT). Within this framework, the data-generation pipeline systematically extracts subgraphs from large knowledge bases, applies noise filtering, and leverages LLMs to generate corresponding natural text descriptions, a task more aligned with LLM capabilities than direct KG generation from text. This pipeline enables generating datasets composed of longer texts paired with larger KGs that better reflect real-world scenarios compared to existing benchmarks, thus supporting effective SFT of lightweight models for single-shot KG construction. Experimental results on CE12k, a dataset generated using the introduced pipeline, show that InvertiTune outperforms larger non-fine-tuned LLMs as well as state-of-the-art Text2KG approaches, while also demonstrating stronger cross-dataset generalization on CrossEval-1200, a test set created from three established benchmark datasets and CE12k. These findings highlight the importance of realistic, high-quality training data for advancing efficient and high-performing Text2KG systems.