Enhancing Job Matching: Occupation, Skill and Qualification Linking with the ESCO and EQF taxonomies
作者: Stylianos Saroglou, Konstantinos Diamantaras, Francesco Preta, Marina Delianidi, Apostolos Benisis, Christian Johannes Meyer
分类: cs.CL, cs.LG
发布日期: 2025-12-02
备注: 14 pages, 1 figure, Preprint
🔗 代码/项目: GITHUB
💡 一句话要点
利用语言模型增强职位匹配,连接职业、技能与欧洲分类体系
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 职位匹配 语言模型 技能提取 劳动力市场 ESCO EQF 实体链接 句子链接
📋 核心要点
- 现有职位匹配方法在深层语义理解和跨语言、跨文化适配方面存在不足。
- 论文提出结合句子链接和实体链接,并探索大型语言模型在职位匹配中的应用。
- 论文发布开源工具和带注释数据集,促进劳动力分类和就业研究。
📝 摘要(中文)
本研究探讨了利用语言模型改进劳动力市场信息分类的潜力,通过将招聘文本与两个主要的欧洲框架相连接:欧洲技能、能力、资格和职业(ESCO)分类体系以及欧洲资格框架(EQF)。我们研究并比较了文献中两种突出的方法:句子链接和实体链接。为了支持正在进行的研究,我们发布了一个开源工具,其中包含这两种方法,旨在促进劳动力分类和就业论述方面的进一步工作。为了超越表面层面的技能提取,我们引入了两个专门用于评估职业和资格如何在招聘文本中表示的带注释数据集。此外,我们还研究了利用生成式大型语言模型完成此任务的不同方法。我们的发现有助于推进职位实体提取的最新技术水平,并为在数字化中介经济中检查工作、技能和劳动力市场叙事提供计算基础设施。我们的代码已公开发布。
🔬 方法详解
问题定义:论文旨在解决劳动力市场信息分类的问题,具体而言,是将招聘文本中的职业、技能和资格与欧洲技能、能力、资格和职业(ESCO)分类体系以及欧洲资格框架(EQF)进行有效链接。现有方法主要依赖于关键词匹配或简单的规则,难以捕捉招聘文本中复杂的语义信息,并且缺乏对职业和资格的深层理解。此外,现有方法在处理不同语言和文化背景下的招聘信息时,泛化能力较弱。
核心思路:论文的核心思路是利用语言模型强大的语义理解能力,将招聘文本中的信息映射到 ESCO 和 EQF 分类体系中。通过句子链接和实体链接两种方法,提取招聘文本中的关键信息,并将其与 ESCO 和 EQF 中的概念进行匹配。同时,探索利用生成式大型语言模型直接生成匹配结果的可能性。这种方法能够更准确地理解招聘文本的含义,并提高匹配的准确性和泛化能力。
技术框架:论文提出的技术框架主要包含以下几个模块:1) 数据预处理:对招聘文本进行清洗、分词等处理;2) 句子链接:利用语言模型计算招聘文本句子与 ESCO/EQF 概念描述之间的相似度,选择最相关的概念;3) 实体链接:识别招聘文本中的职业、技能和资格实体,并将其链接到 ESCO/EQF 中的对应实体;4) 大型语言模型生成:使用大型语言模型直接生成招聘文本与 ESCO/EQF 概念的匹配结果;5) 结果评估:使用带注释的数据集评估不同方法的性能。
关键创新:论文的关键创新点在于:1) 结合句子链接和实体链接两种方法,提高了匹配的准确性;2) 探索了大型语言模型在职位匹配中的应用,为未来的研究提供了新的方向;3) 发布了开源工具和带注释数据集,促进了劳动力分类和就业研究的发展。
关键设计:论文中,句子链接方法使用了预训练的句子嵌入模型(例如 Sentence-BERT)来计算句子之间的相似度。实体链接方法使用了命名实体识别(NER)模型来识别招聘文本中的实体,并使用知识图谱嵌入模型来计算实体之间的相似度。大型语言模型使用了预训练的生成式模型(例如 GPT-3)进行微调,以生成招聘文本与 ESCO/EQF 概念的匹配结果。损失函数方面,可能使用了交叉熵损失或对比损失来优化模型。
🖼️ 关键图片
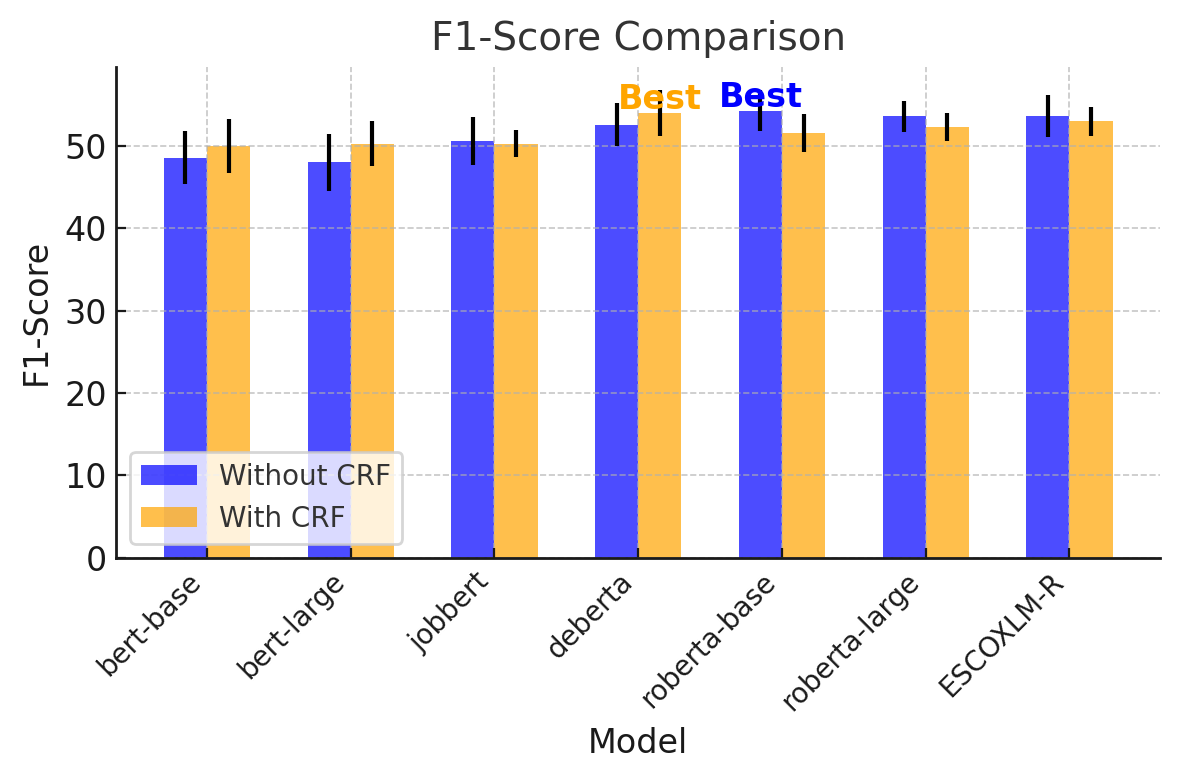
📊 实验亮点
论文通过实验验证了所提出方法的有效性,并与现有的基线方法进行了比较。虽然具体性能数据未在摘要中给出,但强调了该研究在职位实体提取方面的进步,并为数字化经济中工作、技能和劳动力市场叙事的检查提供了计算基础设施。开源工具和数据集的发布也为后续研究提供了便利。
🎯 应用场景
该研究成果可应用于智能招聘系统、职业技能培训推荐、劳动力市场分析等领域。通过更准确地匹配职位需求和求职者技能,可以提高招聘效率,促进就业,并为政府制定劳动力市场政策提供数据支持。未来,该研究可以扩展到其他语言和文化背景,并与其他领域的知识图谱进行融合,构建更全面的劳动力市场信息平台。
📄 摘要(原文)
This study investigates the potential of language models to improve the classification of labor market information by linking job vacancy texts to two major European frameworks: the European Skills, Competences, Qualifications and Occupations (ESCO) taxonomy and the European Qualifications Framework (EQF). We examine and compare two prominent methodologies from the literature: Sentence Linking and Entity Linking. In support of ongoing research, we release an open-source tool, incorporating these two methodologies, designed to facilitate further work on labor classification and employment discourse. To move beyond surface-level skill extraction, we introduce two annotated datasets specifically aimed at evaluating how occupations and qualifications are represented within job vacancy texts. Additionally, we examine different ways to utilize generative large language models for this task. Our findings contribute to advancing the state of the art in job entity extraction and offer computational infrastructure for examining work, skills, and labor market narratives in a digitally mediated economy. Our code is made publicly available: https://github.com/tabiya-tech/tabiya-livelihoods-classifier