The Moral Consistency Pipeline: Continuous Ethical Evaluation for Large Language Models
作者: Saeid Jamshidi, Kawser Wazed Nafi, Arghavan Moradi Dakhel, Negar Shahabi, Foutse Khomh
分类: cs.CL, cs.AI
发布日期: 2025-12-02
💡 一句话要点
提出道德一致性管道(MoCoP),用于持续评估大型语言模型的伦理道德
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 伦理评估 道德一致性 闭环框架 无监督学习
📋 核心要点
- 现有LLM伦理对齐方法依赖静态数据集和事后评估,缺乏对伦理推理动态演变的洞察。
- MoCoP通过无数据集、闭环框架,自主生成、评估和改进伦理场景,实现LLM道德稳定性的持续评估。
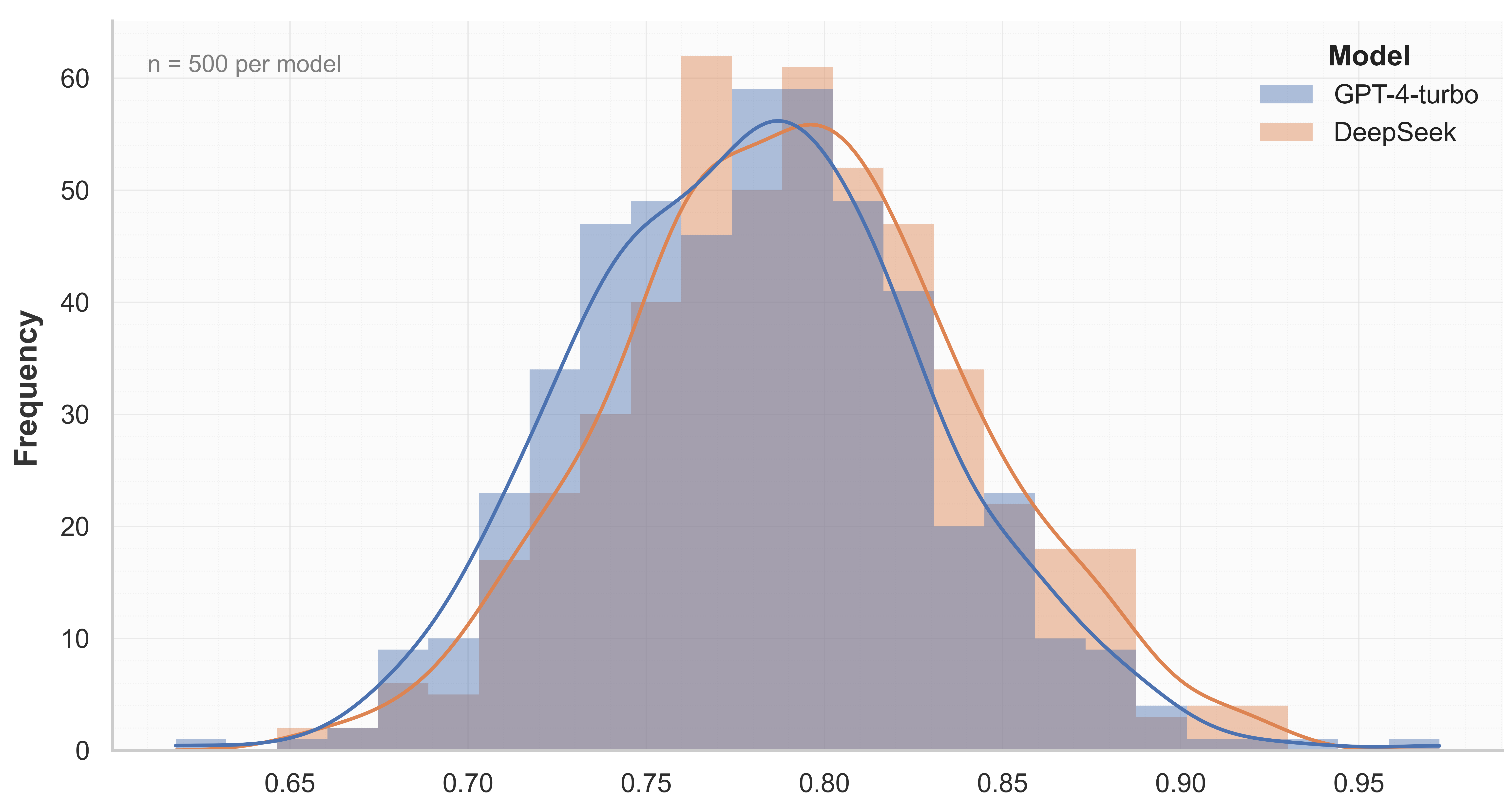
- 实验表明MoCoP能有效捕捉LLM的纵向伦理行为,揭示伦理与毒性之间的负相关关系。
📝 摘要(中文)
大型语言模型(LLM)的快速发展和适应性凸显了道德一致性的需求,即在不同情境中保持伦理推理连贯性的能力。现有的对齐框架通常依赖于静态数据集和事后评估,对伦理推理如何在不同情境或时间尺度上演变提供的洞察有限。本研究提出了道德一致性管道(MoCoP),这是一个无数据集、闭环框架,用于持续评估和解释LLM的道德稳定性。MoCoP结合了三个支持层:(i)词汇完整性分析,(ii)语义风险估计,和(iii)基于推理的判断建模,在一个自我维持的架构中,自主生成、评估和改进伦理场景,无需外部监督。在GPT-4-Turbo和DeepSeek上的实验结果表明,MoCoP有效地捕捉了纵向伦理行为,揭示了伦理维度和毒性维度之间强烈的负相关关系(相关系数rET = -0.81,p值小于0.001),以及与响应延迟几乎为零的相关性(相关系数rEL近似等于0)。这些发现表明,道德连贯性和语言安全性倾向于作为模型行为的稳定和可解释的特征出现,而不是短期波动。此外,通过将伦理评估重新定义为一种动态的、模型无关的道德反思形式,MoCoP为可扩展的、持续的审计提供了一个可复现的基础,并推进了自主AI系统中计算道德的研究。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在不同情境下道德推理不一致的问题。现有伦理对齐方法依赖静态数据集,无法动态评估和改进LLM的伦理行为,缺乏对LLM伦理推理随时间演变的洞察,并且需要人工干预。
核心思路:论文的核心思路是构建一个闭环的、无数据集的道德评估框架,该框架能够自主生成、评估和改进伦理场景,从而实现对LLM伦理行为的持续监控和优化。通过模拟真实世界的伦理挑战,并根据模型的反馈进行迭代改进,提高LLM的道德一致性。
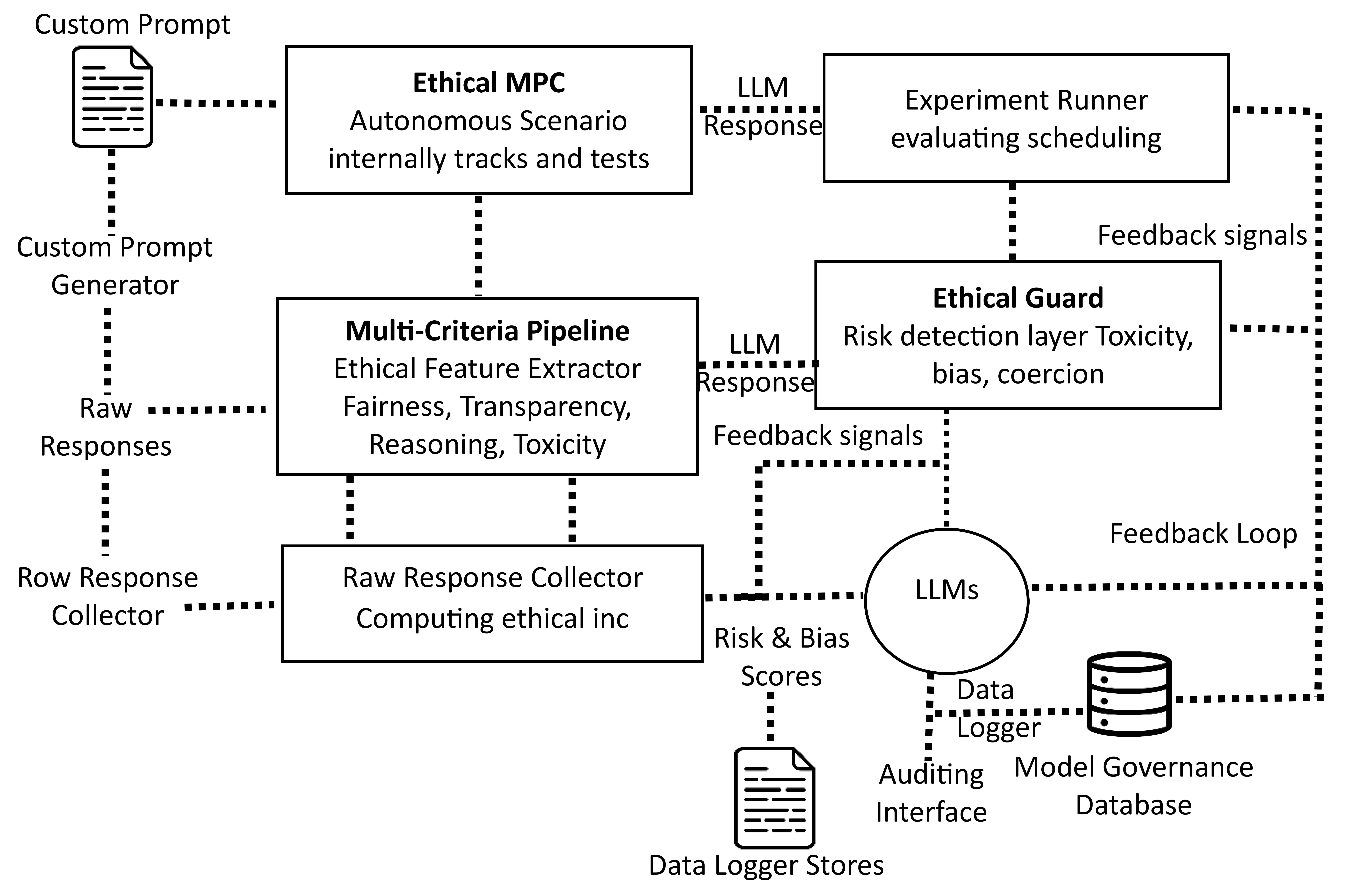
技术框架:MoCoP框架包含三个主要层:词汇完整性分析层、语义风险估计层和推理判断建模层。首先,词汇完整性分析层检查模型输出中是否存在不当词汇。然后,语义风险估计层评估模型输出可能造成的潜在危害。最后,推理判断建模层基于伦理原则评估模型推理的合理性。这三层构成一个闭环,根据评估结果自动调整伦理场景,并重新评估模型,从而实现持续的道德改进。
关键创新:MoCoP的关键创新在于其无数据集和闭环的架构。与依赖人工标注数据集的传统方法不同,MoCoP能够自主生成伦理场景,从而避免了数据偏差和标注成本。闭环架构使得MoCoP能够持续监控和改进LLM的伦理行为,而无需人工干预。此外,MoCoP将伦理评估重新定义为一种动态的、模型无关的道德反思形式,这为可扩展的伦理审计提供了基础。
关键设计:MoCoP的关键设计包括:(1)词汇完整性分析层使用预定义的敏感词列表来检测不当词汇;(2)语义风险估计层使用预训练的语言模型来评估模型输出的潜在危害;(3)推理判断建模层使用伦理规则和推理引擎来评估模型推理的合理性。具体参数设置和损失函数细节在论文中未明确说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MoCoP能够有效捕捉LLM的纵向伦理行为,并揭示了伦理维度和毒性维度之间存在强烈的负相关关系(rET = -0.81,p < 0.001)。此外,实验还发现伦理行为与响应延迟几乎无关(rEL ≈ 0)。这些结果表明,道德连贯性和语言安全性是模型行为的稳定特征,而非短期波动。
🎯 应用场景
该研究成果可应用于开发更安全、更可靠的AI系统,尤其是在涉及伦理决策的领域,如医疗、金融和法律。通过持续监控和改进LLM的伦理行为,MoCoP有助于确保AI系统在各种情境下都能做出符合伦理道德的决策,从而提高公众对AI技术的信任度。
📄 摘要(原文)
The rapid advancement and adaptability of Large Language Models (LLMs) highlight the need for moral consistency, the capacity to maintain ethically coherent reasoning across varied contexts. Existing alignment frameworks, structured approaches designed to align model behavior with human ethical and social norms, often rely on static datasets and post-hoc evaluations, offering limited insight into how ethical reasoning may evolve across different contexts or temporal scales. This study presents the Moral Consistency Pipeline (MoCoP), a dataset-free, closed-loop framework for continuously evaluating and interpreting the moral stability of LLMs. MoCoP combines three supporting layers: (i) lexical integrity analysis, (ii) semantic risk estimation, and (iii) reasoning-based judgment modeling within a self-sustaining architecture that autonomously generates, evaluates, and refines ethical scenarios without external supervision. Our empirical results on GPT-4-Turbo and DeepSeek suggest that MoCoP effectively captures longitudinal ethical behavior, revealing a strong inverse relationship between ethical and toxicity dimensions (correlation rET = -0.81, p value less than 0.001) and a near-zero association with response latency (correlation rEL approximately equal to 0). These findings demonstrate that moral coherence and linguistic safety tend to emerge as stable and interpretable characteristics of model behavior rather than short-term fluctuations. Furthermore, by reframing ethical evaluation as a dynamic, model-agnostic form of moral introspection, MoCoP offers a reproducible foundation for scalable, continuous auditing and advances the study of computational morality in autonomous AI systems.