An Empirical Survey of Model Merging Algorithms for Social Bias Mitigation
作者: Daiki Shirafuji, Tatsuhiko Saito, Yasutomo Kimura
分类: cs.CL, cs.AI
发布日期: 2025-12-02
备注: Accepted in PACLIC 2025
💡 一句话要点
模型融合算法用于缓解社会偏见:一项针对LLM的实证研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会偏见 模型融合 公平性 算法评估
📋 核心要点
- 大型语言模型存在社会偏见,现有方法难以有效缓解且缺乏系统性比较。
- 论文探索模型融合算法,通过合并多个模型参数来减轻LLM中的社会偏见。
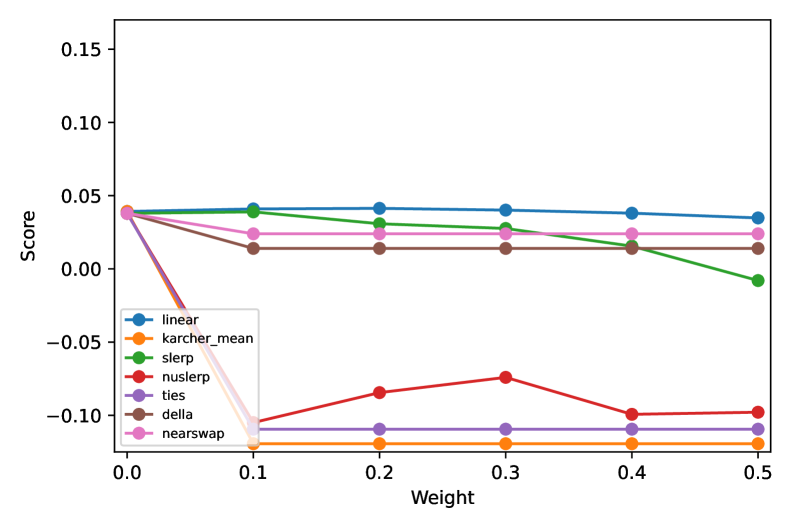
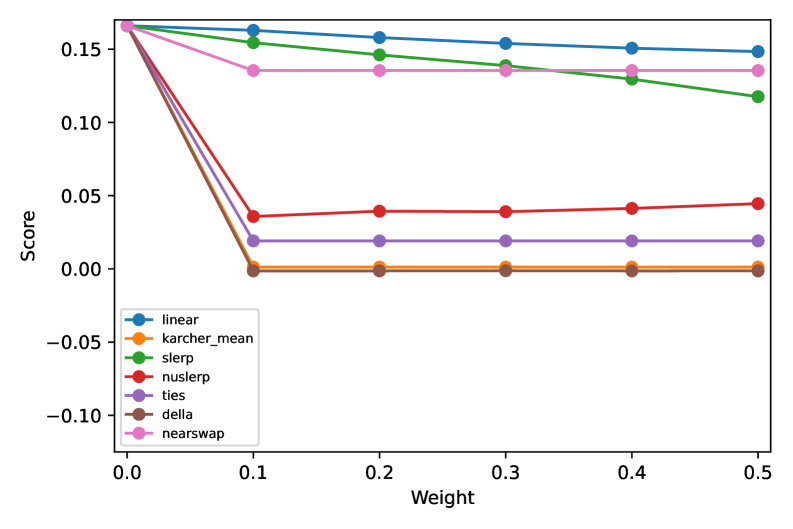
- 实验表明,Linear、SLERP和Nearswap能在减少偏见的同时维持下游任务性能,但过度去偏见会损害语言能力。
📝 摘要(中文)
大型语言模型(LLM)会继承甚至放大预训练语料库中存在的社会偏见,从而威胁公平性和社会信任。为了解决这个问题,最近的研究探索了通过模型融合方法“编辑”LLM参数以减轻社会偏见。然而,目前缺乏实证比较。本文对七种算法进行了实证研究:Linear、Karcher Mean、SLERP、NuSLERP、TIES、DELLA和Nearswap,并将它们应用于GPT、LLaMA和Qwen系列的13个开源权重模型。我们使用三个偏见数据集(BBQ、BOLD和HONEST)进行了全面的评估,并衡量了这些技术对SuperGLUE基准下游任务中LLM性能的影响。我们发现偏见减少和下游性能之间存在权衡:实现更大程度偏见缓解的方法会降低准确性,尤其是在需要阅读理解以及常识和因果推理的任务上。在融合算法中,Linear、SLERP和Nearswap始终如一地减少偏见,同时保持整体性能,其中具有适度插值权重的SLERP成为最平衡的选择。这些结果突出了模型融合算法在缓解偏见方面的潜力,同时也表明过度去偏见或不适当的融合方法可能导致重要语言能力的退化。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中存在的社会偏见问题。现有方法在减轻偏见方面效果有限,并且缺乏对不同模型融合算法的系统性比较。现有方法的痛点在于,如何在减少偏见的同时,尽可能地保持LLM在下游任务中的性能。
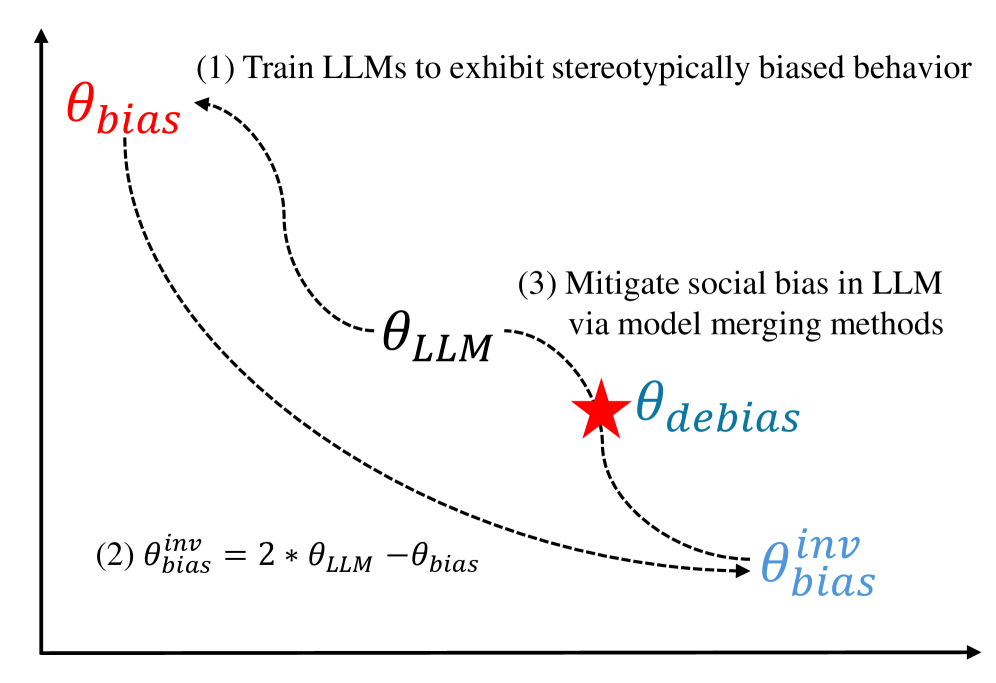
核心思路:论文的核心思路是通过模型融合,将多个具有不同偏见倾向的模型进行合并,从而在整体上降低模型的社会偏见。通过调整融合权重,可以在偏见缓解和性能保持之间取得平衡。这种方法的核心在于找到合适的融合算法和权重,以实现最佳的偏见缓解效果,同时避免对LLM的语言能力造成过大的损害。
技术框架:该研究的技术框架主要包括以下几个阶段: 1. 选择具有代表性的LLM模型(GPT、LLaMA、Qwen系列)。 2. 选择多种模型融合算法(Linear、Karcher Mean、SLERP、NuSLERP、TIES、DELLA、Nearswap)。 3. 使用偏见数据集(BBQ、BOLD、HONEST)评估模型的偏见程度。 4. 使用SuperGLUE基准评估模型在下游任务中的性能。 5. 分析不同融合算法在偏见缓解和性能保持方面的表现,并找出最佳的融合策略。
关键创新:该研究的关键创新在于对多种模型融合算法在缓解LLM社会偏见方面的效果进行了全面的实证比较。之前的研究主要集中在单个模型的偏见缓解方法上,而该研究则探索了通过合并多个模型来降低偏见的可能性。此外,该研究还揭示了偏见缓解和下游任务性能之间的权衡关系,并提出了通过调整融合权重来平衡两者的方法。
关键设计:论文的关键设计包括: 1. 选择了多种具有代表性的模型融合算法,涵盖了线性插值、几何平均等不同类型的算法。 2. 使用了多个偏见数据集,以全面评估模型的偏见程度。 3. 使用了SuperGLUE基准,以评估模型在下游任务中的性能。 4. 通过调整融合权重,探索了偏见缓解和性能保持之间的权衡关系。 5. 对实验结果进行了详细的分析,并提出了针对不同场景的最佳融合策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Linear、SLERP和Nearswap等模型融合算法能够在一定程度上减少LLM的社会偏见,同时保持下游任务的性能。其中,SLERP算法在适度插值权重下表现出最佳的平衡性。然而,过度去偏见或不适当的融合方法可能导致LLM在阅读理解、常识推理等方面的能力下降。例如,某些算法在BBQ数据集上取得了较好的偏见缓解效果,但在SuperGLUE基准上的性能有所下降。
🎯 应用场景
该研究成果可应用于开发更公平、更值得信赖的LLM。通过模型融合,可以减轻LLM在招聘、信贷评估等敏感领域的偏见,提高决策的公正性。此外,该研究也为未来LLM的偏见缓解提供了新的思路,例如可以探索更有效的模型融合算法或自适应调整融合权重的方法。
📄 摘要(原文)
Large language models (LLMs) are known to inherit and even amplify societal biases present in their pre-training corpora, threatening fairness and social trust. To address this issue, recent work has explored ``editing'' LLM parameters to mitigate social bias with model merging approaches; however, there is no empirical comparison. In this work, we empirically survey seven algorithms: Linear, Karcher Mean, SLERP, NuSLERP, TIES, DELLA, and Nearswap, applying 13 open weight models in the GPT, LLaMA, and Qwen families. We perform a comprehensive evaluation using three bias datasets (BBQ, BOLD, and HONEST) and measure the impact of these techniques on LLM performance in downstream tasks of the SuperGLUE benchmark. We find a trade-off between bias reduction and downstream performance: methods achieving greater bias mitigation degrade accuracy, particularly on tasks requiring reading comprehension and commonsense and causal reasoning. Among the merging algorithms, Linear, SLERP, and Nearswap consistently reduce bias while maintaining overall performance, with SLERP at moderate interpolation weights emerging as the most balanced choice. These results highlight the potential of model merging algorithms for bias mitigation, while indicating that excessive debiasing or inappropriate merging methods may lead to the degradation of important linguistic abilities.