Input Order Shapes LLM Semantic Alignment in Multi-Document Summarization
作者: Jing Ma
分类: cs.CL
发布日期: 2025-12-02
备注: 9 pages, 3 figures, 2 tables
💡 一句话要点
多文档摘要中输入顺序影响LLM的语义对齐,首篇文档具有显著优先效应
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多文档摘要 大型语言模型 输入顺序 语义对齐 首因效应 信息偏差 Gemini 2.5 Flash
📋 核心要点
- 现有LLM在多文档摘要中可能对不同输入赋予不同权重,导致信息偏差,影响摘要质量。
- 通过控制输入文档的立场和顺序,研究LLM在生成摘要时对不同位置文档的语义偏好。
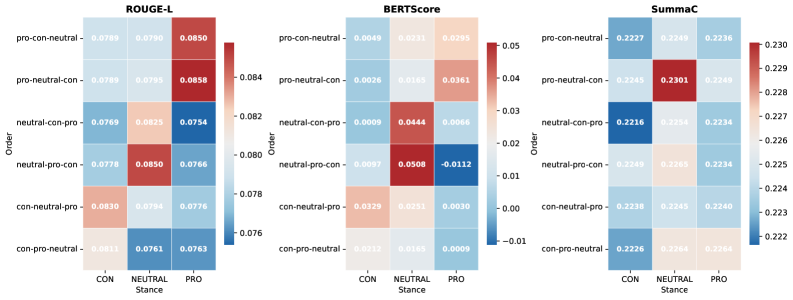
- 实验表明,LLM生成的摘要在语义上更倾向于与第一个输入的文档对齐,存在显著的首因效应。
📝 摘要(中文)
大型语言模型(LLM)目前被广泛应用于多文档摘要场景,例如谷歌的AI Overviews。然而,LLM是否平等地对待所有输入仍然不清楚。本文聚焦于与堕胎相关的新闻,构建了40个由支持、中立和反对三种立场文章组成的三元组,并将每个三元组排列成六种输入顺序,然后提示Gemini 2.5 Flash生成中立的概述。使用ROUGE-L(词汇重叠)、BERTScore(语义相似性)和SummaC(事实一致性)评估每个摘要与其源文章的对齐程度。单因素方差分析表明,所有立场都存在显著的首因效应,表明摘要在语义上更倾向于与第一个看到的文章对齐。成对比较进一步表明,位置1与位置2和3存在显著差异,而后两者之间没有差异,证实了对第一篇文档的选择性偏好。研究结果揭示了依赖LLM生成概述的应用以及Agentic AI系统的风险,因为涉及LLM的步骤可能会对下游行动产生不成比例的影响。
🔬 方法详解
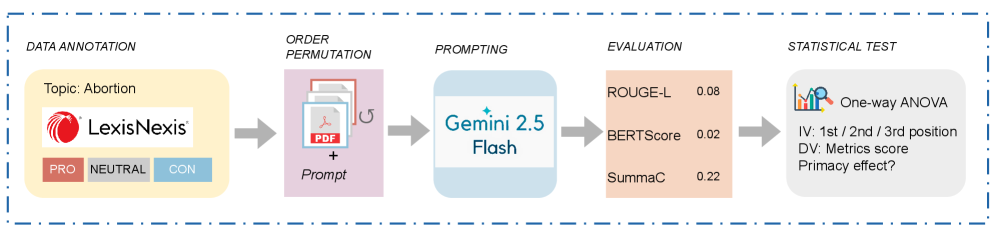
问题定义:本文旨在研究大型语言模型(LLM)在多文档摘要任务中,输入文档顺序对生成摘要内容的影响。现有方法通常假设LLM平等对待所有输入文档,但实际情况可能并非如此,这可能导致摘要结果产生偏差,尤其是在处理具有不同立场或观点的信息时。
核心思路:本文的核心思路是通过控制输入文档的顺序,观察LLM在生成摘要时对不同位置文档的语义偏好。具体来说,通过构建包含不同立场(支持、中立、反对)的文章组合,并改变这些文章的输入顺序,来分析LLM生成的摘要与不同位置文章的语义相似度。
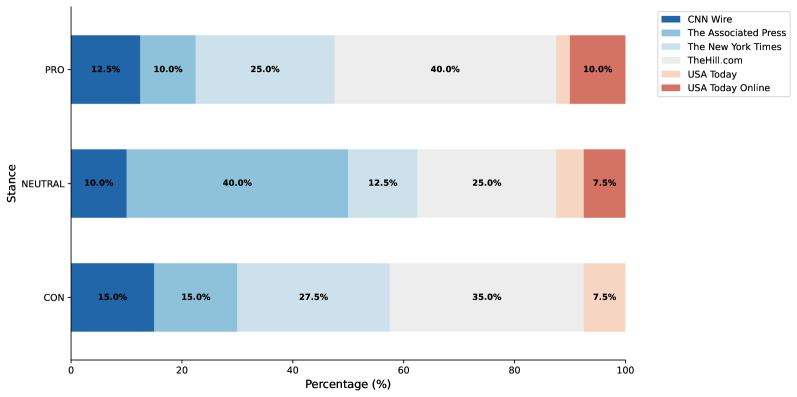
技术框架:研究框架主要包括以下几个步骤:1)构建数据集:收集与堕胎相关的新闻文章,并将其分为支持、中立和反对三种立场。2)生成文章三元组:从每个立场中选择一篇文章,组成一个三元组。3)排列输入顺序:将每个三元组排列成六种不同的输入顺序。4)生成摘要:使用Gemini 2.5 Flash模型,提示其为每个输入顺序生成中立的概述。5)评估摘要质量:使用ROUGE-L、BERTScore和SummaC等指标,评估每个摘要与其源文章的词汇重叠、语义相似性和事实一致性。6)统计分析:使用单因素方差分析和成对比较,分析不同输入位置对摘要质量的影响。
关键创新:本文的关键创新在于揭示了LLM在多文档摘要任务中存在的“首因效应”,即LLM生成的摘要在语义上更倾向于与第一个输入的文档对齐。这一发现挑战了LLM平等对待所有输入的假设,并提出了对LLM在信息处理中可能存在的偏差的担忧。
关键设计:本文的关键设计包括:1)使用包含不同立场文章的三元组,以模拟真实世界中复杂的信息环境。2)使用多种评估指标(ROUGE-L、BERTScore和SummaC),以全面评估摘要的质量。3)使用单因素方差分析和成对比较等统计方法,以验证首因效应的显著性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM生成的摘要在语义上更倾向于与第一个输入的文档对齐,存在显著的首因效应。具体来说,BERTScore的单因素方差分析显示,不同输入位置对摘要的语义相似度有显著影响(p < 0.05)。成对比较进一步表明,位置1与位置2和3存在显著差异,而后两者之间没有差异,证实了对第一篇文档的选择性偏好。
🎯 应用场景
该研究结果对依赖LLM生成概述的应用具有重要意义,例如新闻聚合、信息检索和决策支持系统。了解LLM的输入顺序偏好可以帮助我们设计更公平、更可靠的AI系统。此外,该研究也对Agentic AI系统具有潜在影响,因为LLM在这些系统中的决策过程可能会受到输入顺序的影响,从而导致下游行动的偏差。
📄 摘要(原文)
Large language models (LLMs) are now used in settings such as Google's AI Overviews, where it summarizes multiple long documents. However, it remains unclear whether they weight all inputs equally. Focusing on abortion-related news, we construct 40 pro-neutral-con article triplets, permute each triplet into six input orders, and prompt Gemini 2.5 Flash to generate a neutral overview. We evaluate each summary against its source articles using ROUGE-L (lexical overlap), BERTScore (semantic similarity), and SummaC (factual consistency). One-way ANOVA reveals a significant primacy effect for BERTScore across all stances, indicating that summaries are more semantically aligned with the first-seen article. Pairwise comparisons further show that Position 1 differs significantly from Positions 2 and 3, while the latter two do not differ from each other, confirming a selective preference for the first document. The findings present risks for applications that rely on LLM-generated overviews and for agentic AI systems, where the steps involving LLMs can disproportionately influence downstream actions.