From Imitation to Discrimination: Toward A Generalized Curriculum Advantage Mechanism Enhancing Cross-Domain Reasoning Tasks
作者: Changpeng Yang, Jinyang Wu, Yuchen Liu, Shuai Zhang, Yang Li, Qiliang Liang, Hongzhen Wang, Shuai Nie, Jiaming Xu, Runyu Shi, Ying Huang, Guoquan Zhang
分类: cs.CL
发布日期: 2025-12-02 (更新: 2025-12-15)
备注: Accepted by AAAI 2026
💡 一句话要点
提出CAPO:一种基于课程优势的策略优化方法,提升跨领域推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理能力 课程学习 优势函数
📋 核心要点
- 现有强化学习方法在训练LLM时,对正负优势信号不加区分混合,导致早期训练指导模糊,收益有限。
- CAPO通过自适应课程机制,先用正向优势样本进行模仿学习,建立基础,再引入负向信号培养判别能力。
- CAPO与多种优化方法兼容,在数学推理和GUI推理任务上均取得了稳定和显著的性能提升。
📝 摘要(中文)
强化学习已成为后训练大型语言模型、提升其推理能力的一种范式。这类方法为每个样本计算一个优势值,反映其表现优于或劣于预期,从而产生正向和负向的训练信号。然而,现有方法不加区分地混合这两种信号,尤其是在早期阶段,可能导致模糊的指导和有限的收益。为了解决这个问题,我们提出了CAPO(课程优势策略优化),一种基于优势信号的自适应课程机制。该机制首先利用仅包含正向优势样本的模仿学习来建立稳健的基础,然后引入负向信号来培养判别能力,从而提高复杂场景中的泛化能力。我们的方法与GRPO、PPO、RLOO和Reinforce++等多种优化方法兼容,在数学推理任务中始终如一地实现了稳定和显著的改进,并进一步有效地推广到多模态图形用户界面(GUI)推理场景,从而确立了其作为一种通用且稳健的优化框架的地位。
🔬 方法详解
问题定义:现有基于强化学习的LLM推理能力提升方法,在计算优势函数后,直接混合正向和负向信号进行训练。这种不加区分的处理方式,尤其是在训练初期,会导致模型接收到相互矛盾的指导信号,从而影响训练效率和最终性能。痛点在于缺乏一种有效的机制来区分和利用不同类型的优势信号,以实现更有效的学习。
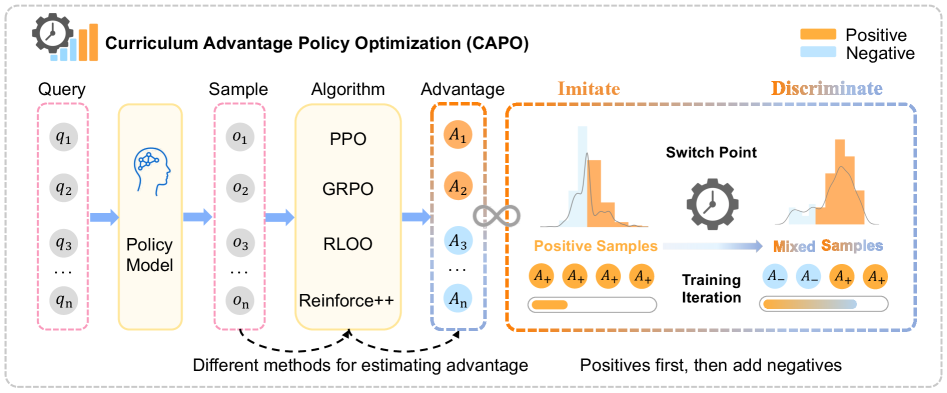
核心思路:CAPO的核心思路是借鉴课程学习的思想,根据优势信号的性质,设计一个自适应的课程。具体来说,首先利用正向优势样本进行模仿学习,使模型快速掌握基本技能,建立一个稳健的基础。然后,逐步引入负向优势样本,引导模型区分优劣,提升判别能力和泛化能力。这样可以避免早期训练中的信号冲突,提高学习效率和最终性能。
技术框架:CAPO的整体框架可以分为两个主要阶段:模仿学习阶段和判别学习阶段。在模仿学习阶段,模型只使用正向优势样本进行训练,目标是模仿高质量的行为。在判别学习阶段,模型同时使用正向和负向优势样本进行训练,目标是区分好的和坏的行为。CAPO可以与多种现有的强化学习优化方法(如GRPO、PPO、RLOO、Reinforce++)结合使用,作为一种通用的优化策略。
关键创新:CAPO的关键创新在于提出了基于优势信号的自适应课程机制。与现有方法不同,CAPO不是简单地混合正负优势信号,而是根据训练阶段和样本质量,动态地调整正负样本的比例,从而实现更有效的学习。这种课程学习机制可以帮助模型更快地收敛,并获得更好的泛化能力。
关键设计:CAPO的关键设计包括:1) 如何定义和计算优势函数;2) 如何确定模仿学习阶段和判别学习阶段的切换时机;3) 如何控制正负样本的比例。论文中可能使用了特定的优势函数计算方法,并根据验证集上的性能来动态调整课程。具体的损失函数和网络结构取决于所使用的基础强化学习算法。
🖼️ 关键图片

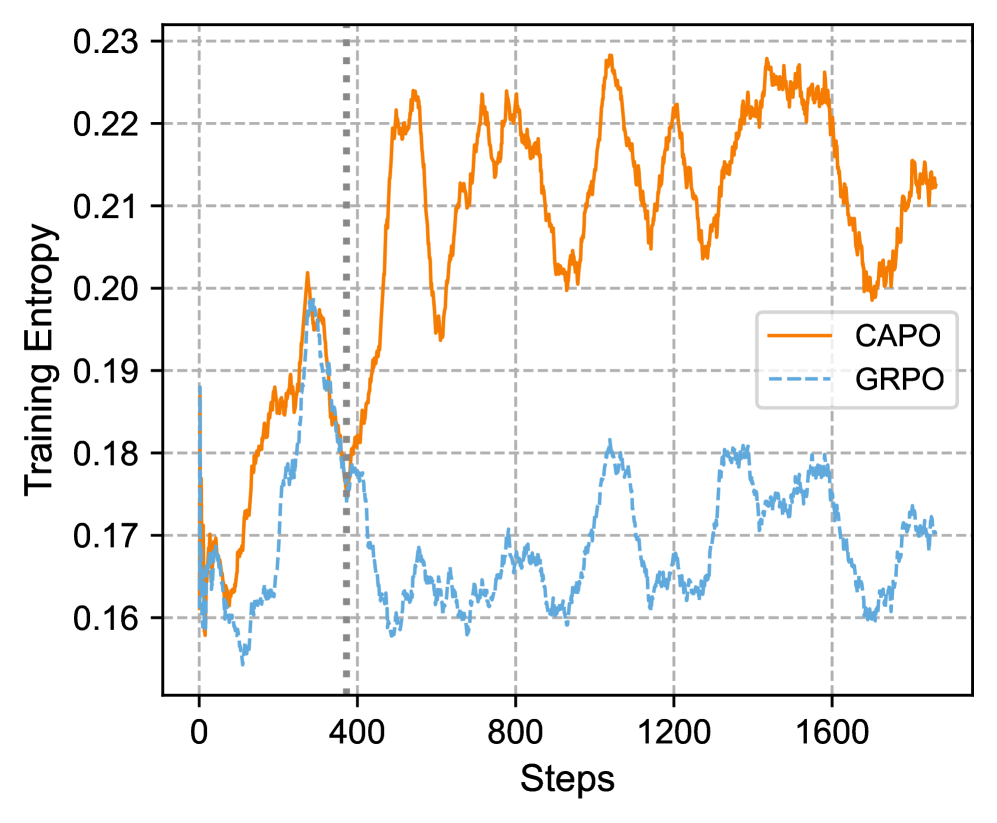
📊 实验亮点
CAPO在数学推理任务和GUI推理任务上都取得了显著的性能提升。在数学推理任务中,CAPO与GRPO、PPO、RLOO和Reinforce++等多种优化方法结合使用,均取得了稳定和显著的改进。在GUI推理任务中,CAPO也表现出了良好的泛化能力,证明了其作为一种通用优化框架的有效性。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
CAPO具有广泛的应用前景,可以应用于各种需要提升LLM推理能力的场景,例如数学问题求解、代码生成、游戏AI、机器人控制等。通过更有效地利用优势信号,CAPO可以帮助LLM更好地理解和解决复杂问题,提高其在实际应用中的性能和可靠性。此外,CAPO的自适应课程学习机制也可以推广到其他类型的机器学习任务中,例如图像识别、自然语言处理等。
📄 摘要(原文)
Reinforcement learning has emerged as a paradigm for post-training large language models, boosting their reasoning capabilities. Such approaches compute an advantage value for each sample, reflecting better or worse performance than expected, thereby yielding both positive and negative signals for training. However, the indiscriminate mixing of the two signals in existing methods, especially from the early stages, may lead to ambiguous guidance and limited gains. To address this issue, we propose CAPO (Curriculum Advantage Policy Optimization), an adaptive curriculum mechanism based on advantage signals. The proposed mechanism bootstraps imitation learning with positive-only advantage samples to establish robust foundations, and subsequently introduces negative signals to cultivate discriminative capabilities, thereby improving generalization across complex scenarios. Compatible with diverse optimization methods including GRPO, PPO, RLOO, and Reinforce++, our method consistently achieves stable and significant improvements in mathematical reasoning tasks, and further generalizes effectively to multimodal Graphical User Interface (GUI) reasoning scenarios, establishing itself as a versatile and robust optimization framework.