Four Over Six: More Accurate NVFP4 Quantization with Adaptive Block Scaling
作者: Jack Cook, Junxian Guo, Guangxuan Xiao, Yujun Lin, Song Han
分类: cs.CL, cs.LG
发布日期: 2025-12-01 (更新: 2026-01-22)
备注: 10 pages, 4 figures
🔗 代码/项目: GITHUB
💡 一句话要点
提出Four Over Six (4/6)自适应块缩放NVFP4量化算法,提升大模型训练和推理精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: NVFP4量化 自适应块缩放 低精度训练 大语言模型 模型压缩
📋 核心要点
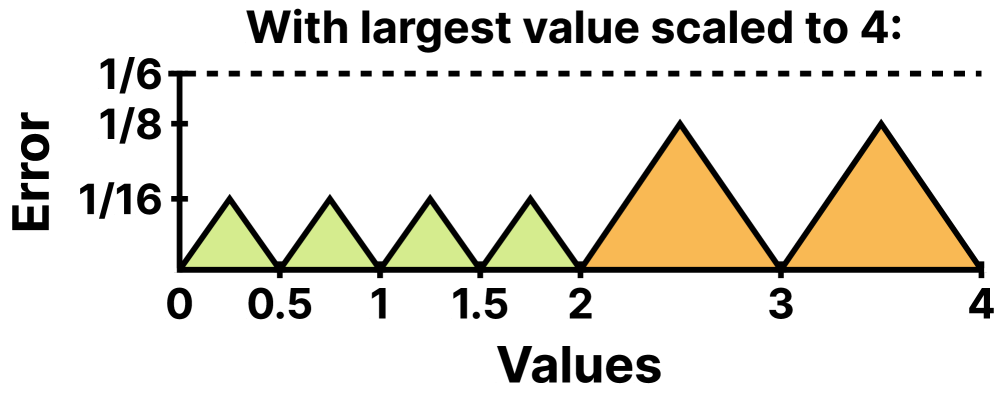
- 现有NVFP4量化精度不足,导致大模型性能显著下降,尤其是在数值较大的区域。
- 4/6通过自适应块缩放,使FP4表示值的分布更均匀,从而降低量化误差,提升精度。
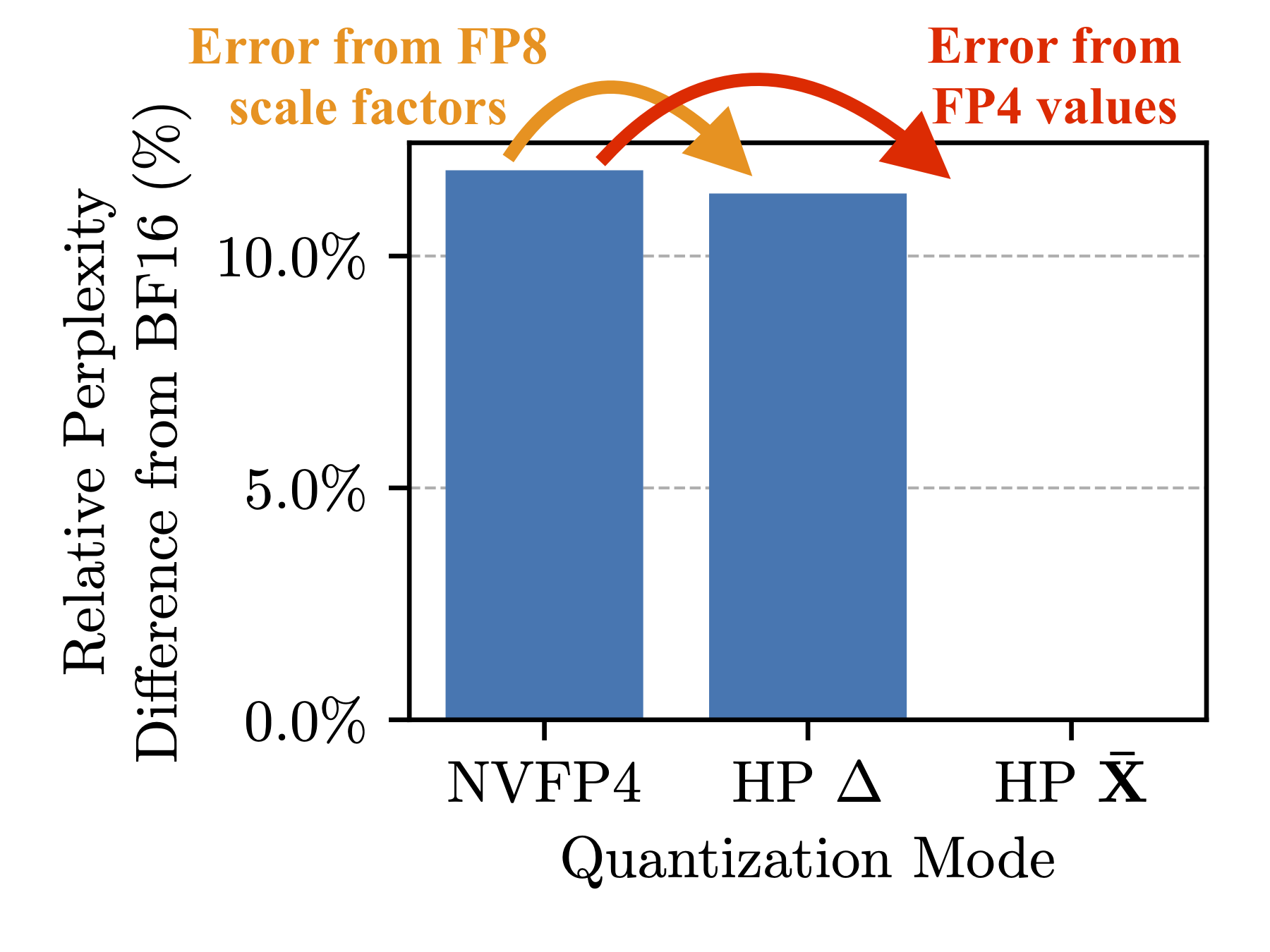
- 在Nemotron 3 Nano 30B-A3B模型上的实验表明,4/6能有效降低训练损失,性能接近BF16。
📝 摘要(中文)
随着大型语言模型规模的增长,低精度数值格式(如NVFP4)因其在提高速度和减少内存使用方面的潜力而备受关注。然而,将模型量化到NVFP4仍然具有挑战性,因为精度的不足通常会降低模型性能。本文提出了Four Over Six (4/6),这是对块缩放NVFP4量化算法的改进,旨在减少量化误差。与整数格式不同,浮点格式具有非均匀的步长,这会在较大的值上产生较大的量化误差。4/6通过自适应地将某些块缩放到较小的FP4值来利用这一点,从而使可表示值的分布更加均匀,并减少接近最大值的量化误差。实验表明,4/6可以在NVIDIA Blackwell GPU上高效实现,从而在预训练和推理过程中获得性能提升,且计算开销极小。在使用Nemotron 3 Nano 30B-A3B模型架构进行的预训练实验中,我们发现与使用当前最先进的NVFP4训练方法训练的模型相比,4/6使训练损失更接近BF16。代码已开源。
🔬 方法详解
问题定义:现有的NVFP4量化方法在量化大数值时,由于浮点格式的非均匀步长,会引入较大的量化误差,导致模型精度下降。尤其是在大型语言模型的训练和推理过程中,这种误差会累积并严重影响模型性能。因此,需要一种更精确的NVFP4量化方法来减少这种误差。
核心思路:论文的核心思路是利用浮点格式的特性,通过自适应地缩放不同的数据块,使得量化后的数值分布更加均匀,从而减少量化误差。具体来说,对于数值较大的数据块,将其缩放到较小的FP4值范围,从而减小量化步长,提高量化精度。
技术框架:4/6算法在块缩放的NVFP4量化基础上进行改进。首先,将输入数据分成若干个块。然后,对于每个块,算法会根据块内数值的分布情况,决定是否需要进行缩放。如果需要缩放,则将该块内的数值缩放到较小的FP4值范围。最后,将量化后的数据存储为NVFP4格式。整个过程可以高效地在NVIDIA Blackwell GPU上实现。
关键创新:4/6的关键创新在于其自适应的块缩放策略。与传统的块缩放方法不同,4/6能够根据每个块内数值的分布情况,动态地调整缩放比例。这种自适应的策略使得量化后的数值分布更加均匀,从而显著降低了量化误差。这是与现有NVFP4量化方法最本质的区别。
关键设计:4/6算法的关键设计包括:1) 如何确定每个块是否需要缩放;2) 如何选择合适的缩放比例。论文中可能使用了某种统计指标(例如,块内数值的最大值或方差)来判断是否需要缩放。缩放比例的选择可能基于某种优化算法,以最小化量化误差。具体的损失函数和网络结构取决于具体的应用场景,论文中使用了Nemotron 3 Nano 30B-A3B模型架构进行实验。
🖼️ 关键图片

📊 实验亮点
实验结果表明,与当前最先进的NVFP4训练方法相比,使用4/6训练的Nemotron 3 Nano 30B-A3B模型在预训练过程中,训练损失更接近BF16,表明4/6能够有效提高NVFP4量化的精度,并提升模型的性能。此外,4/6算法可以在NVIDIA Blackwell GPU上高效实现,且计算开销极小,保证了实际应用中的可行性。
🎯 应用场景
该研究成果可广泛应用于大型语言模型的训练和推理加速,尤其是在资源受限的场景下,例如边缘设备或移动设备。通过使用4/6量化算法,可以在保证模型性能的前提下,显著降低内存占用和计算复杂度,从而实现更高效的模型部署和应用。未来,该技术有望推动人工智能在更多领域的普及。
📄 摘要(原文)
As large language models have grown larger, interest has grown in low-precision numerical formats such as NVFP4 as a way to improve speed and reduce memory usage. However, quantizing models to NVFP4 remains difficult as the lack of precision generally degrades model performance. In this work, we address this issue with Four Over Six (4/6), a modification to the block-scaled NVFP4 quantization algorithm that yields reduced quantization error. Unlike integer formats, floating point formats have non-uniform step sizes which create larger quantization error on larger values. 4/6 takes advantage of this by adaptively scaling some blocks to smaller FP4 values, making the distribution of representable values more uniform and reducing quantization error for near-maximal values. We show that 4/6 can be implemented efficiently on NVIDIA Blackwell GPUs, resulting in performance gains during both pre-training and inference with minimal computational overhead. In pre-training experiments with the Nemotron 3 Nano 30B-A3B model architecture, we find that 4/6 brings training loss closer to BF16 compared to models trained with current state-of-the-art NVFP4 training recipes. Our code is available at http://github.com/mit-han-lab/fouroversix.