The Art of Scaling Test-Time Compute for Large Language Models
作者: Aradhye Agarwal, Ayan Sengupta, Tanmoy Chakraborty
分类: cs.CL
发布日期: 2025-12-01
💡 一句话要点
大规模语言模型测试时计算缩放策略的系统性对比研究
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 测试时计算缩放 大型语言模型 推理优化 计算资源分配 模型性能评估
📋 核心要点
- 现有测试时计算缩放策略缺乏系统性对比,模型类型和问题难度对性能的影响尚不明确。
- 论文通过大规模实验,研究不同测试时计算缩放策略在不同模型和数据集上的表现。
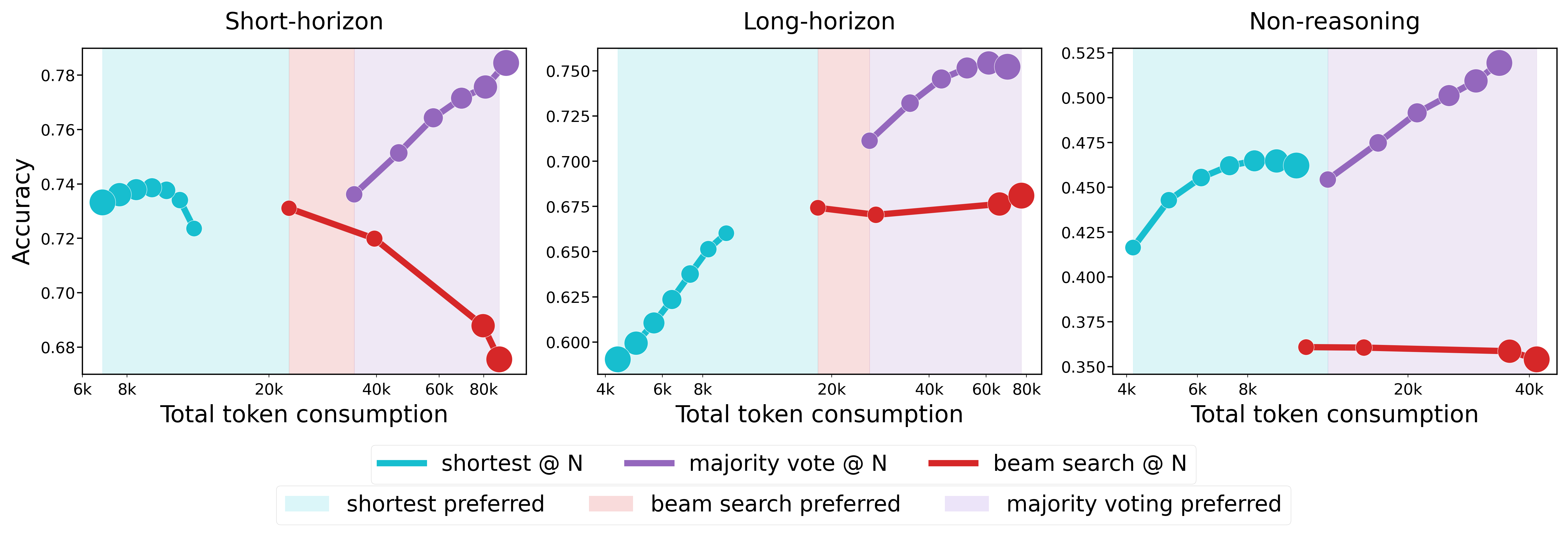
- 实验结果表明,没有单一最优策略,模型表现与问题难度和计算预算密切相关,并据此提出了策略选择方法。
📝 摘要(中文)
测试时计算缩放(TTS)是一种在推理过程中动态分配计算资源,以提升大型语言模型(LLM)推理能力的有效方法。然而,目前缺乏对现有TTS策略在相同条件下的系统性比较,并且模型类型和问题难度对性能的影响尚不明确。为了弥补这些不足,我们首次对TTS进行了大规模研究,使用了8个开源LLM(参数规模从7B到235B),生成了超过300亿个token,并评估了它们在四个推理数据集上的表现。我们观察到三个一致的趋势:(1)没有一种TTS策略在所有情况下都占据主导地位;(2)推理模型在不同问题难度和trace长度下表现出不同的trace质量模式,可分为短时程和长时程类别;(3)对于给定的模型类型,最优TTS性能随计算预算单调递增。基于这些发现,我们提供了一个实用的方法,用于根据问题难度、模型类型和计算预算选择最佳TTS策略,为有效的推理时缩放提供实用指导。
🔬 方法详解
问题定义:论文旨在解决大型语言模型推理过程中,如何根据不同的模型、任务难度和计算资源,选择最优的测试时计算缩放(TTS)策略的问题。现有方法缺乏系统性的比较,无法指导用户在实际应用中选择合适的策略,导致计算资源的浪费或性能的下降。
核心思路:论文的核心思路是通过大规模的实验,系统性地比较各种已知的TTS策略在不同模型、不同数据集上的表现,从而揭示不同策略的优缺点以及适用场景。通过分析实验结果,找出影响TTS策略性能的关键因素,例如问题难度、模型类型和计算预算,并据此提出一种实用的策略选择方法。
技术框架:论文的技术框架主要包括以下几个部分:1) 选择具有代表性的开源LLM,涵盖不同的参数规模(7B到235B);2) 选择具有代表性的推理数据集,涵盖不同的问题难度;3) 实现并比较多种已知的TTS策略,例如自适应计算时间(ACT)、置信度驱动的停止等;4) 进行大规模的实验,生成大量的token,并记录各种TTS策略的性能指标;5) 分析实验结果,找出影响TTS策略性能的关键因素,并提出一种实用的策略选择方法。
关键创新:论文的关键创新在于:1) 首次对TTS策略进行了大规模的系统性比较,揭示了不同策略的优缺点以及适用场景;2) 发现了推理模型在不同问题难度和trace长度下表现出不同的trace质量模式,并将其分为短时程和长时程类别;3) 提出了一种实用的策略选择方法,可以根据问题难度、模型类型和计算预算选择最佳TTS策略。
关键设计:论文的关键设计包括:1) 选择了具有代表性的开源LLM和推理数据集,保证了实验结果的泛化性;2) 实现了多种已知的TTS策略,并进行了公平的比较;3) 采用了大量的实验数据,保证了实验结果的可靠性;4) 提出了实用的策略选择方法,方便用户在实际应用中使用。
🖼️ 关键图片


📊 实验亮点
该研究通过对8个开源LLM(7B到235B)在四个推理数据集上进行大规模实验,发现没有单一TTS策略在所有情况下都占据主导地位。实验揭示了模型在不同问题难度和trace长度下表现出不同的trace质量模式,并证明了对于给定的模型类型,最优TTS性能随计算预算单调递增。基于这些发现,论文提供了一个实用的TTS策略选择方法。
🎯 应用场景
该研究成果可应用于各种需要使用大型语言模型进行推理的场景,例如问答系统、对话系统、代码生成等。通过选择合适的TTS策略,可以在保证性能的同时,有效地降低计算成本,提高推理效率。该研究为大型语言模型的实际应用提供了重要的指导意义。
📄 摘要(原文)
Test-time scaling (TTS) -- the dynamic allocation of compute during inference -- is a promising direction for improving reasoning in large language models (LLMs). However, a systematic comparison of well-known TTS strategies under identical conditions is missing, and the influence of model type and problem difficulty on performance remains unclear. To address these gaps, we conduct the first large-scale study of TTS, spanning over thirty billion tokens generated using eight open-source LLMs (7B to 235B parameters), across four reasoning datasets. We observe three consistent trends: (1) no single TTS strategy universally dominates; (2) reasoning models exhibit distinct trace-quality patterns across problem difficulty and trace length, forming short-horizon and long-horizon categories; and (3) for a given model type, the optimal TTS performance scales monotonically with compute budget. Based on these insights, we provide a practical recipe for selecting the best TTS strategy, considering problem difficulty, model type, and compute budget, providing a practical guide to effective inference-time scaling.