Rectifying LLM Thought from Lens of Optimization
作者: Junnan Liu, Hongwei Liu, Songyang Zhang, Kai Chen
分类: cs.CL, cs.AI
发布日期: 2025-12-01
备注: Work in progress
💡 一句话要点
提出RePro,通过优化视角提升LLM的思维链推理能力,缓解过度思考问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 思维链 强化学习 推理优化 过程级奖励
📋 核心要点
- 长思维链(CoT)提示虽能提升LLM推理能力,但常导致过度思考和推理链过长等次优行为,影响性能。
- 论文将CoT推理过程视为梯度下降优化,提出RePro方法,通过过程级奖励来优化LLM的推理过程。
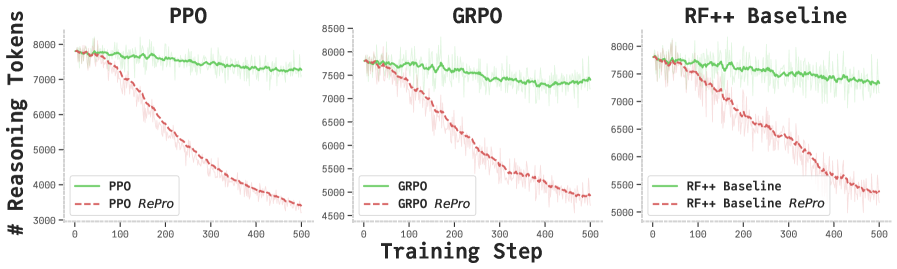
- 实验表明,RePro能有效提升LLM在数学、科学和编码等任务上的推理性能,并缓解过度思考问题。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展得益于其涌现的推理能力,特别是通过长思维链(CoT)提示,实现了彻底的探索和审议。尽管取得了这些进展,但长CoT LLM常常表现出次优的推理行为,例如过度思考和过长的推理链,这会损害性能。本文从优化的角度分析了推理过程,将CoT视为梯度下降过程,其中每个推理步骤都构成朝着问题解决的更新。在此基础上,我们引入了RePro(Rectifying Process-level Reward),这是一种在后训练期间改进LLM推理的新方法。RePro定义了一个替代目标函数来评估CoT的底层优化过程,利用双重评分机制来量化其强度和稳定性。这些分数被聚合为复合的过程级奖励,无缝集成到具有可验证奖励的强化学习(RLVR)管道中,以优化LLM。在跨多个强化学习算法和不同LLM的广泛实验中,并在涵盖数学、科学和编码的基准上进行评估,证明RePro始终可以提高推理性能并减轻次优推理行为。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在使用长思维链(CoT)进行推理时出现的次优行为,例如过度思考和推理链过长。现有方法虽然利用CoT提升了推理能力,但缺乏对推理过程的有效控制,导致性能下降。
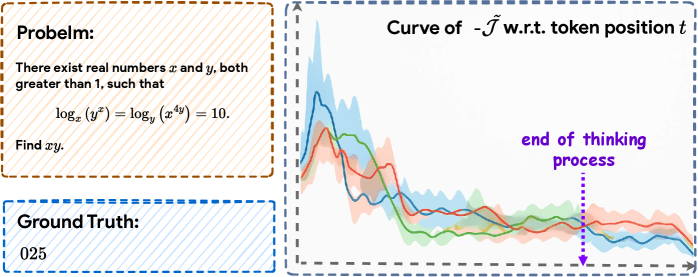
核心思路:论文的核心思路是将CoT推理过程视为一个优化过程,类比于梯度下降。每个推理步骤都被看作是对问题解决方案的一次更新。通过优化这个过程,可以引导LLM进行更有效、更稳定的推理。
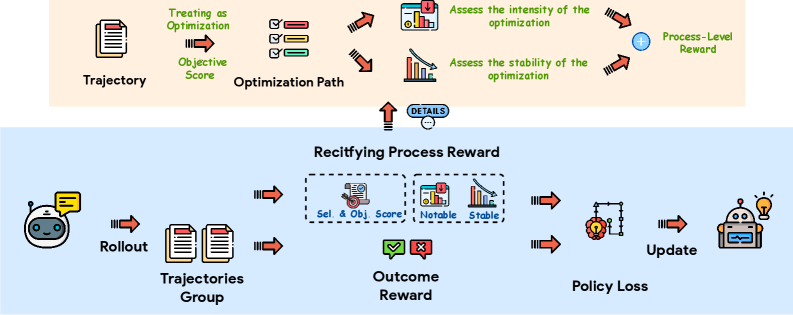
技术框架:RePro方法的核心是定义一个替代目标函数,用于评估CoT推理过程的质量。该框架包含以下主要模块:1) 双重评分机制:量化推理过程的强度和稳定性。2) 过程级奖励:将强度和稳定性评分聚合为复合奖励。3) 强化学习:将过程级奖励集成到RLVR管道中,以优化LLM。整体流程是,首先利用LLM生成CoT推理过程,然后使用双重评分机制评估该过程,生成过程级奖励,最后利用强化学习算法优化LLM,使其生成更优的推理过程。
关键创新:RePro的关键创新在于将CoT推理过程视为一个优化问题,并提出了过程级奖励的概念。与传统的端到端优化方法不同,RePro关注的是推理过程中的每一步,通过量化推理过程的强度和稳定性来引导LLM进行更有效的推理。
关键设计:RePro的关键设计包括:1) 强度评分:衡量每个推理步骤对最终答案的贡献程度。2) 稳定性评分:衡量推理过程的连贯性和一致性。3) 奖励函数:将强度和稳定性评分进行加权组合,形成过程级奖励。具体的权重参数需要根据不同的任务和LLM进行调整。论文使用了RLVR框架,确保奖励的可验证性,从而提高训练的稳定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RePro在数学、科学和编码等多个基准测试中,显著提升了LLM的推理性能。例如,在某些数学问题上,RePro可以将LLM的准确率提高10%以上。与现有的强化学习方法相比,RePro能够更有效地缓解LLM的过度思考问题,并生成更简洁、更有效的推理链。
🎯 应用场景
该研究成果可应用于各种需要复杂推理的场景,例如智能客服、自动编程、科学研究等。通过优化LLM的推理过程,可以提高其解决问题的能力和效率,降低错误率,从而在实际应用中产生更大的价值。未来,该方法有望扩展到其他类型的推理任务和模型,进一步提升LLM的通用性和可靠性。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have been driven by their emergent reasoning capabilities, particularly through long chain-of-thought (CoT) prompting, which enables thorough exploration and deliberation. Despite these advances, long-CoT LLMs often exhibit suboptimal reasoning behaviors, such as overthinking and excessively protracted reasoning chains, which can impair performance. In this paper, we analyze reasoning processes through an optimization lens, framing CoT as a gradient descent procedure where each reasoning step constitutes an update toward problem resolution. Building on this perspective, we introduce RePro (Rectifying Process-level Reward), a novel approach to refine LLM reasoning during post-training. RePro defines a surrogate objective function to assess the optimization process underlying CoT, utilizing a dual scoring mechanism to quantify its intensity and stability. These scores are aggregated into a composite process-level reward, seamlessly integrated into reinforcement learning with verifiable rewards (RLVR) pipelines to optimize LLMs. Extensive experiments across multiple reinforcement learning algorithms and diverse LLMs, evaluated on benchmarks spanning mathematics, science, and coding, demonstrate that RePro consistently enhances reasoning performance and mitigates suboptimal reasoning behaviors.