OPOR-Bench: Evaluating Large Language Models on Online Public Opinion Report Generation
作者: Jinzheng Yu, Yang Xu, Haozhen Li, Junqi Li, Yifan Feng, Ligu Zhu, Hao Shen, Lei Shi
分类: cs.CL
发布日期: 2025-12-01
备注: 27 pages, accepted by CMC-Computers, Materials & Continua, 2025
💡 一句话要点
提出OPOR-Bench基准测试,用于评估大语言模型在在线舆情报告生成任务中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 在线舆情报告生成 大型语言模型 基准测试 自动评估 危机管理
📋 核心要点
- 现有方法缺乏针对在线舆情报告生成的系统性研究和正式任务定义,阻碍了该领域的发展。
- 论文定义了自动在线舆情报告生成(OPOR-GEN)任务,并构建了相应的基准数据集OPOR-BENCH。
- 提出了OPOR-EVAL评估框架,通过模拟人类专家评估,实现对生成报告质量的有效评估,并验证了其与人类判断的高度相关性。
📝 摘要(中文)
在线舆情报告整合新闻和社交媒体信息,为政府和企业提供及时的危机管理。尽管大型语言模型在技术上已经使自动报告生成成为可能,但该领域的系统性研究仍然明显缺失,尤其缺乏正式的任务定义和相应的基准。为了弥合这一差距,我们定义了自动在线舆情报告生成(OPOR-GEN)任务,并构建了OPOR-BENCH,这是一个以事件为中心的benchmark数据集,涵盖463个危机事件及其对应的新闻文章、社交媒体帖子和参考摘要。为了评估报告质量,我们提出了OPOR-EVAL,这是一个新颖的基于代理的框架,通过分析上下文中的生成报告来模拟人类专家的评估。对前沿模型的实验表明,我们的框架与人类判断具有高度相关性。我们全面的任务定义、基准数据集和评估框架为该关键领域的未来研究奠定了坚实的基础。
🔬 方法详解
问题定义:论文旨在解决在线舆情报告自动生成的问题。现有方法缺乏针对该任务的专门研究和基准数据集,导致难以系统地评估和提升模型性能。此外,如何客观、高效地评估生成报告的质量也是一个挑战,传统方法依赖人工评估,成本高且效率低。
核心思路:论文的核心思路是构建一个完整的评估体系,包括任务定义、数据集和评估框架。通过定义OPOR-GEN任务,提供OPOR-BENCH数据集,并提出OPOR-EVAL评估框架,为研究者提供了一个标准化的平台,用于开发和评估在线舆情报告生成模型。OPOR-EVAL通过模拟人类专家评估,降低了评估成本,提高了评估效率。
技术框架:整体框架包含三个主要部分:1) OPOR-GEN任务定义,明确了输入(新闻文章、社交媒体帖子)和输出(舆情报告摘要)的形式;2) OPOR-BENCH数据集,包含463个危机事件及其相关数据;3) OPOR-EVAL评估框架,使用基于代理的模型模拟人类专家,对生成报告进行评估。评估过程包括信息提取、观点分析、逻辑推理等步骤。
关键创新:论文的关键创新在于提出了OPOR-EVAL评估框架,该框架通过模拟人类专家评估,实现了对生成报告质量的自动化评估。与传统的基于指标的评估方法相比,OPOR-EVAL能够更好地捕捉报告的语义信息和逻辑结构,更准确地反映报告的质量。此外,OPOR-BENCH数据集的构建也为该领域的研究提供了宝贵的数据资源。
关键设计:OPOR-EVAL框架的关键设计在于如何有效地模拟人类专家评估。论文使用了大型语言模型作为代理,并设计了一系列评估指标,包括信息覆盖率、观点一致性、逻辑连贯性等。为了提高评估的准确性,论文还采用了上下文分析技术,将生成报告置于事件背景下进行评估。具体参数设置和模型结构在论文中未详细说明,属于未知信息。
🖼️ 关键图片


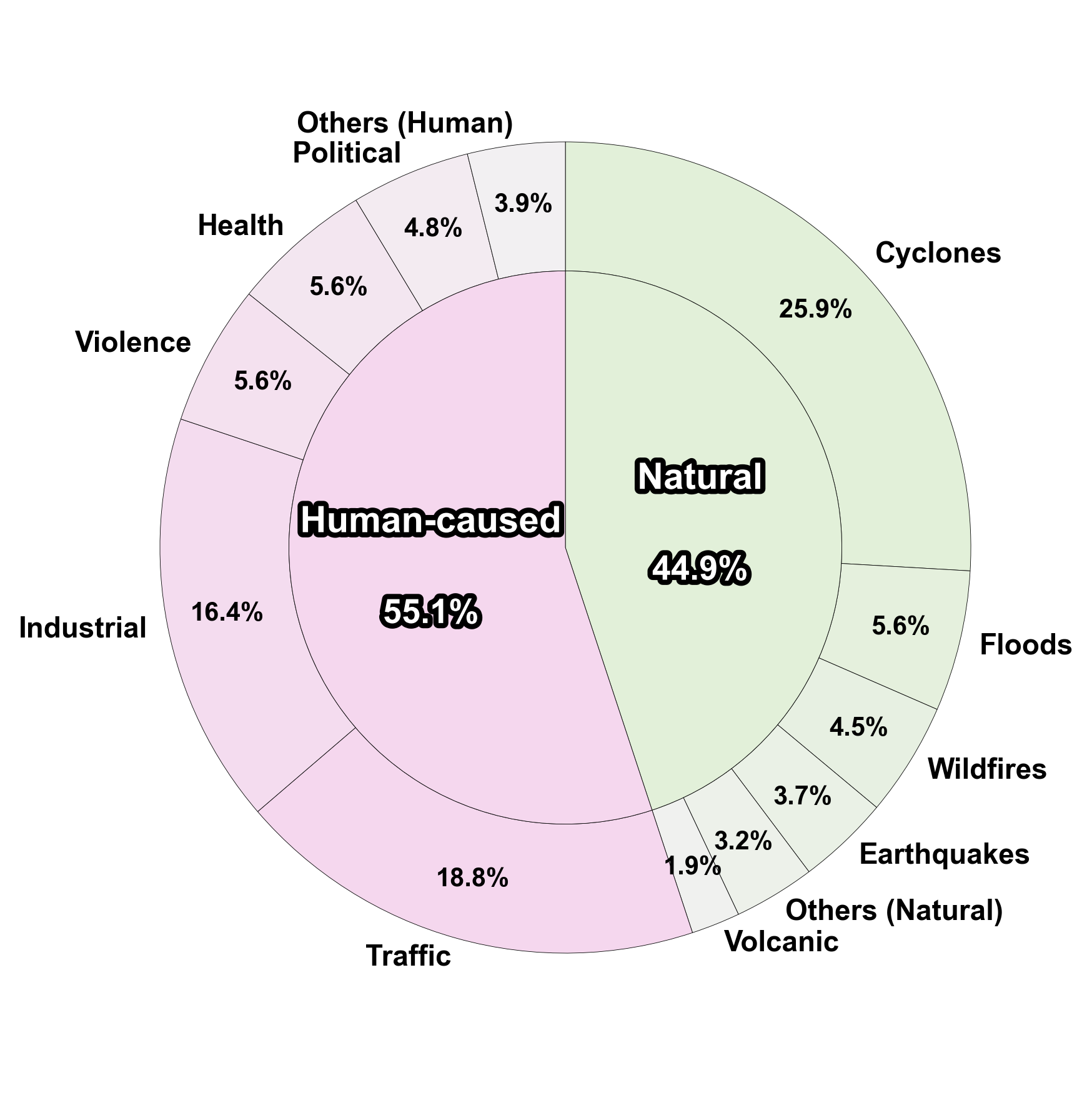
📊 实验亮点
实验结果表明,OPOR-EVAL评估框架与人类判断具有高度相关性,验证了其有效性。论文对多个前沿模型进行了评估,并分析了它们的优缺点,为未来的研究提供了参考。具体的性能数据和提升幅度在论文中未详细说明,属于未知信息。
🎯 应用场景
该研究成果可应用于政府部门、企业和媒体机构,用于自动生成在线舆情报告,辅助危机管理和舆论引导。通过及时、准确地了解舆情动态,相关机构可以更好地应对突发事件,维护社会稳定和企业形象。未来,该技术还可以扩展到其他领域的报告生成,例如金融分析报告、市场调研报告等。
📄 摘要(原文)
Online Public Opinion Reports consolidate news and social media for timely crisis management by governments and enterprises. While large language models have made automated report generation technically feasible, systematic research in this specific area remains notably absent, particularly lacking formal task definitions and corresponding benchmarks. To bridge this gap, we define the Automated Online Public Opinion Report Generation (OPOR-GEN) task and construct OPOR-BENCH, an event-centric dataset covering 463 crisis events with their corresponding news articles, social media posts, and a reference summary. To evaluate report quality, we propose OPOR-EVAL, a novel agent-based framework that simulates human expert evaluation by analyzing generated reports in context. Experiments with frontier models demonstrate that our framework achieves high correlation with human judgments. Our comprehensive task definition, benchmark dataset, and evaluation framework provide a solid foundation for future research in this critical domain.