Beware of Reasoning Overconfidence: Pitfalls in the Reasoning Process for Multi-solution Tasks
作者: Jiannan Guan, Qiguang Chen, Libo Qin, Dengyun Peng, Jinhao Liu, Liangyu Huo, Jian Xie, Wanxiang Che
分类: cs.CL
发布日期: 2025-12-01
💡 一句话要点
针对多解任务,揭示LLM推理过程中的过度自信问题,并提出缓解策略。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多解任务 推理过度自信 长链思维 认知僵化
📋 核心要点
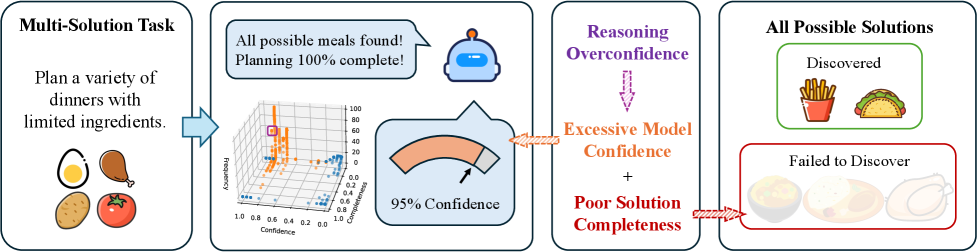
- 现有LLM在多解推理任务中表现不佳,主要挑战在于无法生成全面且多样化的答案。
- 论文提出通过长链思维(Long-CoT)提示,利用迭代探索和自我反思来缓解LLM的推理过度自信问题。
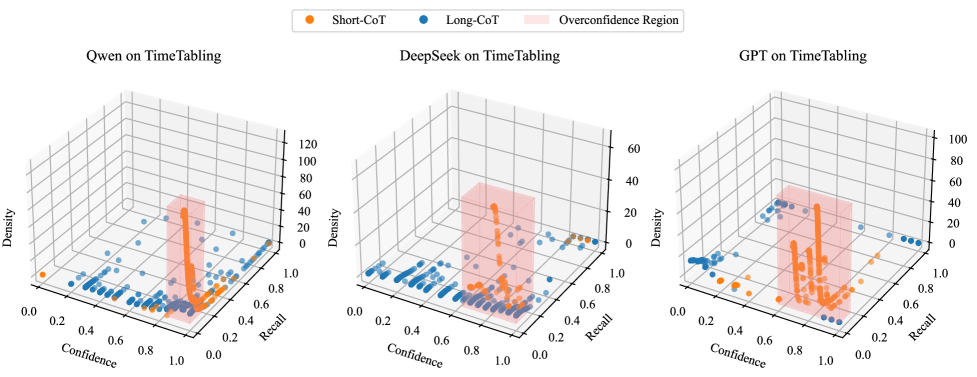
- 实验表明,Long-CoT能有效缓解Short-CoT的过度自信,并初步验证了认知僵化假说。
📝 摘要(中文)
大型语言模型(LLMs)在需要单一正确答案的推理任务中表现出色,但在需要生成全面和多样化答案的多解任务中表现不佳。我们将这种局限性归因于推理过度自信:即在不完整的解决方案集合中表现出过度的确定性。为了检验这种影响,我们引入了MuSoBench,一个多解问题基准。实验表明,传统的短链思维(Short-CoT)提示范式表现出明显的过度自信,而新兴的长链思维(Long-CoT)方法通过迭代探索和自我反思来缓解它。我们进一步描述了可观察的行为和影响因素。为了探究根本原因,我们提出了认知僵化假说,该假说认为,当推理过程过早地收敛于一组狭窄的思维路径时,就会产生过度自信。注意力熵分析为这一观点提供了初步支持。这些发现为评估LLM推理的完整性提供了工具,并强调需要将评估从单一答案的准确性转向全面的探索。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在多解任务中表现出的推理过度自信问题。现有方法,如短链思维(Short-CoT),倾向于过早收敛于单一或少数几个解决方案,无法充分探索所有可能的答案,导致答案的全面性和多样性不足。这种过度自信阻碍了LLM在需要发散性思维的任务中的应用。
核心思路:论文的核心思路是通过引入长链思维(Long-CoT)提示策略,鼓励LLM进行更充分的迭代探索和自我反思。Long-CoT旨在打破LLM的认知僵化,使其能够探索更广泛的思维路径,从而生成更全面和多样化的解决方案集合。这种方法模拟了人类解决复杂问题时不断探索、反思和修正答案的过程。
技术框架:论文主要通过实验分析和基准测试来验证Long-CoT的有效性。首先,构建了一个多解问题基准MuSoBench,用于评估LLM在多解任务中的性能。然后,分别使用Short-CoT和Long-CoT提示LLM,并比较它们在MuSoBench上的表现。此外,论文还进行了注意力熵分析,以初步验证认知僵化假说。整体流程包括问题定义、基准构建、实验评估和结果分析。
关键创新:论文最重要的技术创新点在于提出了认知僵化假说,并利用Long-CoT提示策略来缓解LLM的推理过度自信。与传统的Short-CoT相比,Long-CoT鼓励LLM进行更深入的探索和反思,从而打破认知僵化,生成更全面和多样化的答案。这种方法强调了推理过程的重要性,而不仅仅是最终答案的准确性。
关键设计:Long-CoT的关键设计在于迭代探索和自我反思机制。具体实现方式未知,论文侧重于验证其有效性而非具体实现细节。注意力熵分析用于评估LLM在推理过程中探索不同思维路径的程度,熵值越高表示探索越充分,认知僵化程度越低。MuSoBench基准的设计需要保证问题具有多个合理的解决方案,并且能够有效区分不同推理策略的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Long-CoT提示策略能够有效缓解LLM在多解任务中的推理过度自信问题。在MuSoBench基准测试中,Long-CoT的表现明显优于传统的Short-CoT。注意力熵分析为认知僵化假说提供了初步支持,表明Long-CoT能够促使LLM探索更广泛的思维路径。具体的性能提升数据未知,论文侧重于定性分析和概念验证。
🎯 应用场景
该研究成果可应用于需要创造性问题解决、头脑风暴和方案设计的领域,例如产品设计、战略规划、科学研究等。通过缓解LLM的推理过度自信,可以提高其在这些领域的应用价值,辅助人类进行更全面和深入的思考,并生成更具创新性的解决方案。未来,该研究可以促进开发更可靠和高效的AI辅助决策系统。
📄 摘要(原文)
Large Language Models (LLMs) excel in reasoning tasks requiring a single correct answer, but they perform poorly in multi-solution tasks that require generating comprehensive and diverse answers. We attribute this limitation to \textbf{reasoning overconfidence}: a tendency to express undue certainty in an incomplete solution set. To examine the effect, we introduce \textit{MuSoBench}, a benchmark of multi-solution problems. Experiments show that the conventional short chain-of-thought (Short-CoT) prompting paradigm exhibits pronounced overconfidence, whereas the emerging long chain-of-thought (Long-CoT) approach mitigates it through iterative exploration and self-reflection. We further characterise observable behaviours and influential factors. To probe the underlying cause, we propose the \textbf{cognitive-rigidity hypothesis}, which posits that overconfidence arises when the reasoning process prematurely converges on a narrow set of thought paths. An attention-entropy analysis offers preliminary support for this view. These findings provide tools for assessing the completeness of LLM reasoning and highlight the need to move evaluation beyond single-answer accuracy toward comprehensive exploration.