Learning the Boundary of Solvability: Aligning LLMs to Detect Unsolvable Problems
作者: Dengyun Peng, Qiguang Chen, Bofei Liu, Jiannan Guan, Libo Qin, Zheng Yan, Jinhao Liu, Jianshu Zhang, Wanxiang Che
分类: cs.CL, cs.AI
发布日期: 2025-12-01 (更新: 2026-01-31)
备注: preprint
🔗 代码/项目: GITHUB
💡 一句话要点
提出UnsolvableQA数据集与UnsolvableRL框架,提升LLM对不可解问题的识别能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不可解问题检测 强化学习 数据集构建 幻觉抑制
📋 核心要点
- 现有LLM无法有效区分客观不可解问题和自身能力不足,导致在不可解问题上产生幻觉。
- 论文提出UnsolvableQA数据集和UnsolvableRL框架,通过强化学习对齐模型,提升不可解问题识别能力。
- 实验表明,该方法显著提升了LLM对不可解问题的检测率,并提高了在可解问题上的推理准确率。
📝 摘要(中文)
为了提升大型语言模型(LLM)的可靠性,需要区分客观不可解性(内在矛盾)和主观能力限制(超出模型能力的任务)。目前的LLM常常混淆这两个维度,导致对固有不可解的查询返回自信的幻觉答案。为了解决这个问题,我们提出了一个包含可解和不可解问题的多领域数据集UnsolvableQA,以及一个对齐框架UnsolvableRL。首先,我们通过“逆向构造”系统地将逻辑矛盾注入到原本有效的推理链中,构建UnsolvableQA。其次,我们引入UnsolvableRL,这是一种强化学习范式,它平衡了客观不可解性检测与能力限制下的校准置信度。实验表明,我们的方法实现了强大的不可解性检测(>85%的检测率),并将Qwen3-4B-Instruct在可解推理上的准确率从43.4%提高到69.4%。重要的是,我们发现了一种数据-训练交互:严格的对齐约束在没有不可解数据的情况下会导致能力崩溃,但当包含此类数据时,可以作为严谨性的正则化器,从而提高整体鲁棒性。
🔬 方法详解
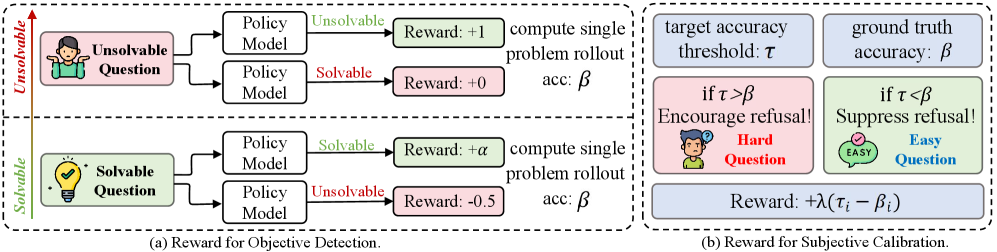
问题定义:论文旨在解决大型语言模型(LLM)无法有效区分客观不可解问题(例如,包含逻辑矛盾的问题)和主观能力限制问题(超出模型能力范围的问题)的难题。现有LLM常常对不可解问题给出自信但错误的答案,即产生幻觉,这严重影响了LLM的可靠性。
核心思路:论文的核心思路是通过构建包含可解和不可解问题的数据集,并利用强化学习来训练LLM,使其能够准确识别不可解问题,并在能力不足时降低置信度。这种方法旨在使LLM的输出与问题的可解性保持一致,从而减少幻觉的产生。
技术框架:整体框架包含两个主要部分:UnsolvableQA数据集的构建和UnsolvableRL强化学习框架的设计。UnsolvableQA数据集通过“逆向构造”方法,在原本可解的推理链中注入逻辑矛盾,从而生成不可解问题。UnsolvableRL框架则利用强化学习,奖励模型正确识别不可解问题,并惩罚模型在不可解问题上给出自信的错误答案。该框架旨在平衡不可解性检测与能力限制下的置信度校准。
关键创新:论文的关键创新在于提出了UnsolvableQA数据集和UnsolvableRL框架,这是一种系统性的方法,用于训练LLM区分可解和不可解问题。与以往主要关注提升LLM在可解问题上的性能不同,该论文关注LLM在不可解问题上的表现,并提出了一种新的训练范式。
关键设计:UnsolvableQA数据集的关键设计在于“逆向构造”方法,通过在可解推理链中注入矛盾,确保不可解问题的生成具有系统性和可控性。UnsolvableRL框架的关键设计在于奖励函数的设计,该函数旨在平衡不可解性检测的准确率和模型在能力限制下的置信度校准。具体的参数设置和网络结构细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在不可解问题检测方面取得了显著的性能提升,检测率超过85%。同时,在可解问题上的推理准确率也从43.4%提高到69.4%(基于Qwen3-4B-Instruct)。研究还发现,在训练过程中加入不可解数据可以作为正则化器,防止模型在严格对齐约束下出现能力崩溃。
🎯 应用场景
该研究成果可应用于提升各种LLM应用的可靠性,例如智能客服、自动问答系统和决策支持系统。通过使LLM能够识别不可解问题,可以避免其给出错误的建议或误导性信息,从而提高用户满意度和信任度。未来,该方法可以扩展到更广泛的问题类型和领域,并与其他技术相结合,进一步提升LLM的鲁棒性和安全性。
📄 摘要(原文)
Ensuring large language model (LLM) reliability requires distinguishing objective unsolvability (inherent contradictions) from subjective capability limitations (tasks exceeding model competence). Current LLMs often conflate these dimensions, leading to hallucinations in which they return confident answers to inherently unsolvable queries. To address this issue, we propose a multi-domain dataset containing both solvable and unsolvable questions, UnsolvableQA, together with an alignment framework, UnsolvableRL. First, we construct UnsolvableQA by "Reverse Construction" that systematically injects logical contradictions into otherwise valid reasoning chains. Second, we introduce UnsolvableRL, a reinforcement learning paradigm that balances objective unsolvability detection with calibrated confidence under capability limits. Empirically, our approach achieves robust unsolvability detection (>85% detection rate) and boosts solvable reasoning accuracy from 43.4% to 69.4% on Qwen3-4B-Instruct. Crucially, we identify a data-training interaction: strict alignment constraints induce Capability Collapse without unsolvable data, but act as a regularizer for rigor when such data are included, thereby improving overall robustness. Our code and data are available at https://github.com/sfasfaffa/unsolvableQA .