MCAT: Scaling Many-to-Many Speech-to-Text Translation with MLLMs to 70 Languages
作者: Yexing Du, Kaiyuan Liu, Youcheng Pan, Bo Yang, Keqi Deng, Xie Chen, Yang Xiang, Ming Liu, Bin Qin, YaoWei Wang
分类: cs.CL
发布日期: 2025-12-01
🔗 代码/项目: GITHUB
💡 一句话要点
MCAT:利用MLLM扩展多对多语音到文本翻译至70种语言
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音到文本翻译 多模态大语言模型 多语言翻译 课程学习 数据平衡
📋 核心要点
- 现有S2TT数据集主要以英语为中心,限制了MLLM多对多翻译能力的扩展。
- MCAT框架通过课程学习和数据平衡策略,有效扩展了MLLM的语言覆盖范围至70种。
- 优化的语音适配器模块显著减少了语音序列长度,提升了MLLM的推理效率。
📝 摘要(中文)
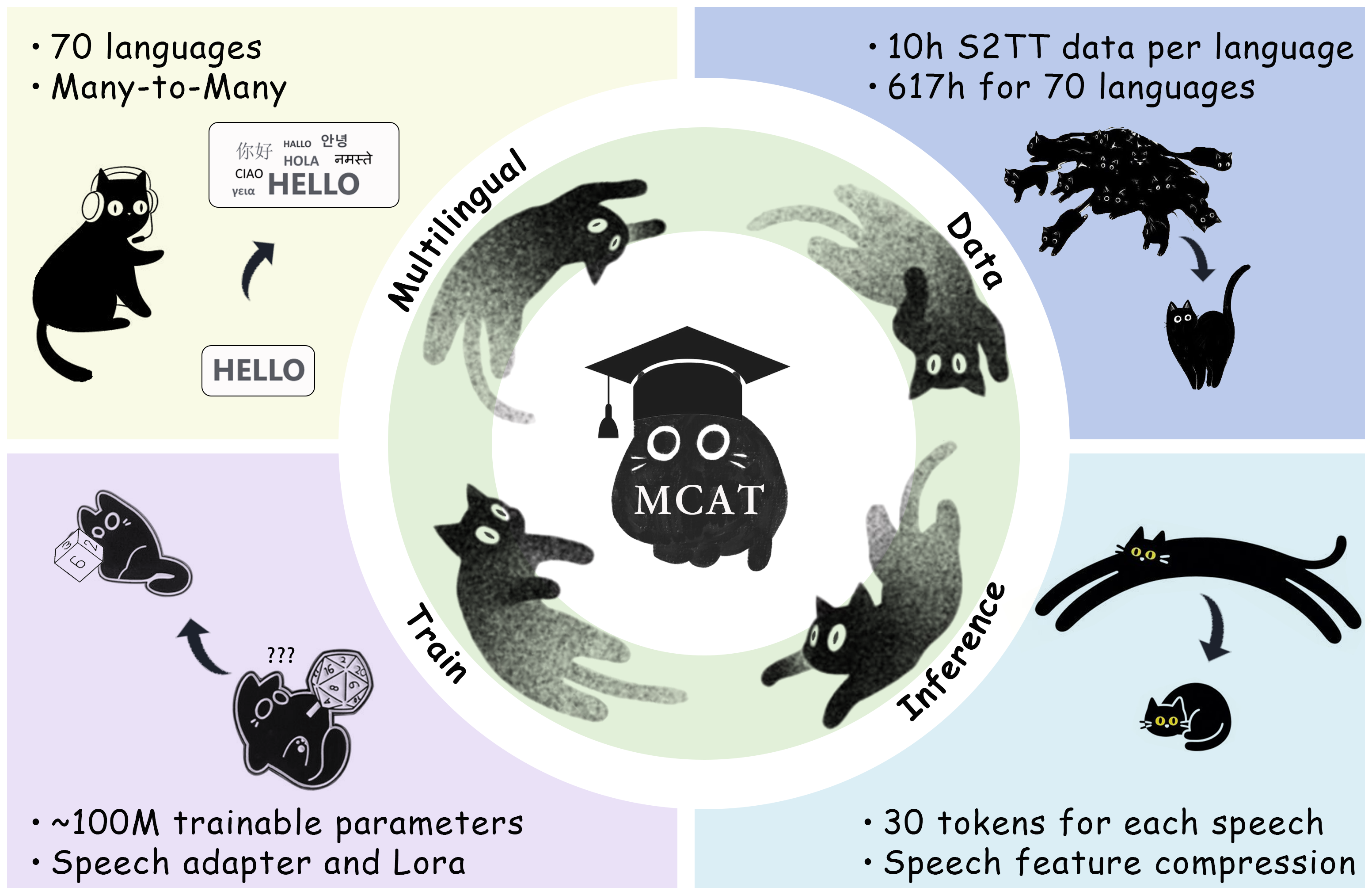
本文提出了一种多语言、低成本、加速的语音到文本翻译器(MCAT)框架,旨在解决多模态大型语言模型(MLLM)在语音到文本翻译(S2TT)任务中面临的语言覆盖范围和效率问题。MCAT包含两项创新:一是利用课程学习和数据平衡策略扩展MLLM支持的语言覆盖范围至70种语言,实现这些语言之间的互译;二是设计优化的语音适配器模块,将语音序列的长度缩短至仅30个token。在不同规模的MLLM(9B和27B)上进行了大量实验,结果表明MCAT不仅在FLEURS数据集上超越了最先进的端到端模型(70x69个翻译方向),而且提高了批量推理效率。该方法仅需约1亿个可训练参数,且每种语言仅使用10小时的S2TT数据。MCAT已开源,以促进MLLM在鲁棒S2TT能力方面的发展。
🔬 方法详解
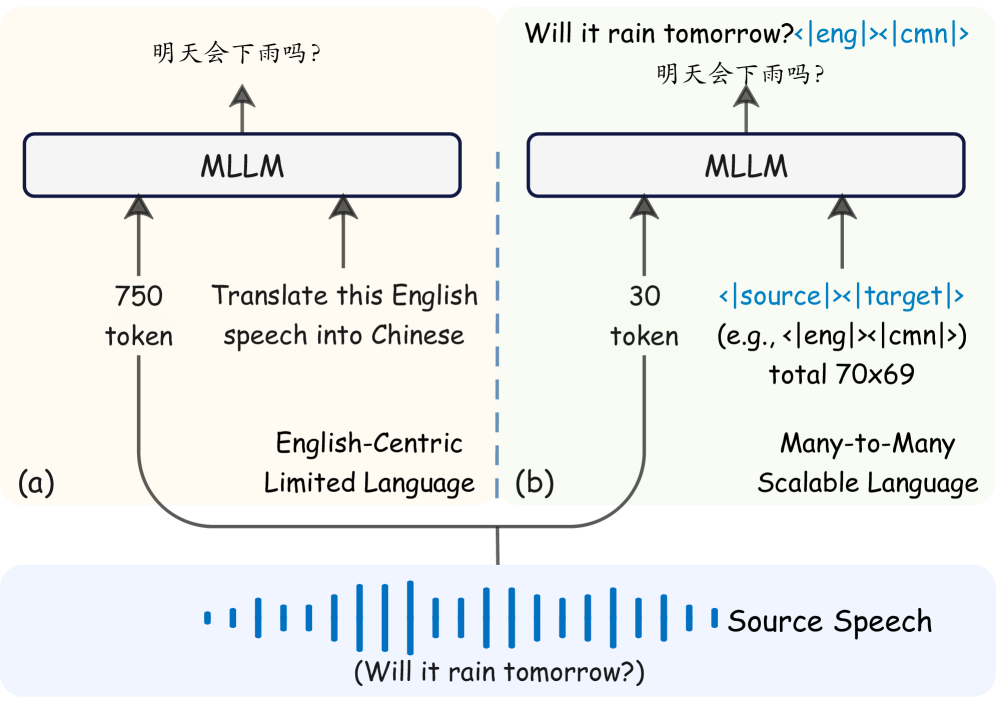
问题定义:论文旨在解决多模态大型语言模型(MLLM)在语音到文本翻译(S2TT)任务中面临的两个主要问题:一是语言覆盖范围有限,现有数据集大多以英语为中心,难以支持多对多翻译;二是推理效率低下,将语音转换为长序列会导致MLLM推理速度显著下降。
核心思路:论文的核心思路是通过课程学习和数据平衡策略来扩展语言覆盖范围,并设计一个优化的语音适配器模块来缩短语音序列的长度,从而提高推理效率。这种方法旨在以较低的计算成本实现高性能的多语言S2TT。
技术框架:MCAT框架主要包含两个核心模块:1) 语言扩展模块:采用课程学习策略,逐步增加训练难度,并结合数据平衡策略,解决不同语言数据量不平衡的问题,从而扩展MLLM的语言覆盖范围。2) 语音适配器模块:该模块负责将语音特征转换为更短的token序列,以减少MLLM的计算负担。整体流程是:输入语音信号,通过语音适配器模块提取特征并压缩序列长度,然后将压缩后的序列输入到MLLM中进行翻译,最后输出目标语言的文本。
关键创新:论文的关键创新在于结合课程学习和数据平衡策略的语言扩展方法,以及优化的语音适配器模块。与现有方法相比,MCAT能够以更低的计算成本支持更多的语言,并显著提高推理效率。现有方法通常依赖于大规模的平行语料库或者复杂的模型结构,而MCAT通过更有效的数据利用和模型设计,实现了更好的性能。
关键设计:在语言扩展模块中,课程学习策略的具体实现方式是逐步增加训练数据的难度,例如从高资源语言开始,逐步引入低资源语言。数据平衡策略则通过对低资源语言进行过采样或者对高资源语言进行欠采样来平衡不同语言的数据量。语音适配器模块的设计目标是在尽可能保留语音信息的前提下,显著减少序列长度。具体实现方式未知,但推测可能采用了pooling、stride卷积或者其他降维技术。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MCAT在FLEURS数据集上超越了最先进的端到端模型,实现了70x69个翻译方向的性能提升。此外,MCAT仅需约1亿个可训练参数,且每种语言仅使用10小时的S2TT数据,即可实现高性能的多语言S2TT。同时,MCAT显著提高了批量推理效率,降低了计算成本。
🎯 应用场景
该研究成果可广泛应用于多语言语音助手、跨语言会议同传、国际新闻广播、多语言教育等领域。通过支持更多的语言和提高翻译效率,MCAT能够促进不同语言人群之间的交流和理解,具有重要的社会价值和商业潜力。未来,该技术有望进一步扩展到更多语言和领域,例如语音搜索、语音摘要等。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) have achieved great success in Speech-to-Text Translation (S2TT) tasks. However, current research is constrained by two key challenges: language coverage and efficiency. Most of the popular S2TT datasets are substantially English-centric, which restricts the scaling-up of MLLMs' many-to-many translation capabilities. Moreover, the inference speed of MLLMs degrades dramatically when the speech is converted into long sequences (e.g., 750 tokens). To address these limitations, we propose a Multilingual Cost-effective Accelerated Speech-to-Text Translator (MCAT) framework, which includes two innovations. First, a language scaling method that leverages curriculum learning and a data balancing strategy is introduced to extend the language coverage supported by MLLMs to 70 languages and achieve mutual translation among these languages. Second, an optimized speech adapter module is designed to reduce the length of the speech sequence to only 30 tokens. Extensive experiments were conducted on MLLMs of different scales (9B and 27B). The experimental results demonstrate that MCAT not only surpasses state-of-the-art end-to-end models on the FLEURS dataset across 70x69 directions but also enhances batch inference efficiency. This is achieved with only ~100M trainable parameters and by using only 10 hours of S2TT data per language. Furthermore, we have released MCAT as open-source to promote the development of MLLMs for robust S2TT capabilities. The code and models are released at https://github.com/yxduir/m2m-70.