Securing Large Language Models (LLMs) from Prompt Injection Attacks
作者: Omar Farooq Khan Suri, John McCrae
分类: cs.CR, cs.CL, cs.LG
发布日期: 2025-12-01
备注: 10 pages, 1 figure, 1 table
💡 一句话要点
评估JATMO防御LLM免受提示注入攻击的有效性,揭示其局限性与改进方向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示注入攻击 大型语言模型安全 对抗性攻击 模型微调 JATMO HOUYI 鲁棒性评估
📋 核心要点
- 大型语言模型易受提示注入攻击,攻击者利用模型的指令遵循能力诱导其执行恶意任务,现有防御方法存在不足。
- 论文评估了JATMO防御提示注入攻击的有效性,JATMO通过微调非指令调整的基础模型来执行单一功能,降低对抗性指令的敏感性。
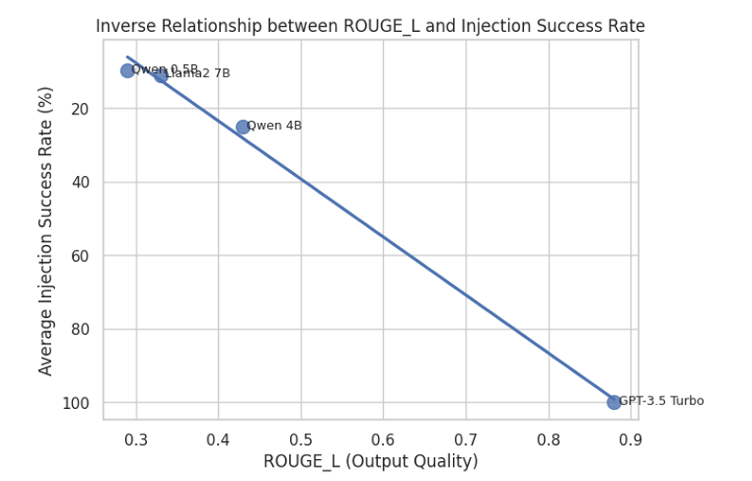
- 实验结果表明,JATMO虽然降低了攻击成功率,但不能完全阻止注入,且生成质量与注入漏洞之间存在权衡。
📝 摘要(中文)
大型语言模型(LLMs)日益广泛地应用于实际场景,但其灵活性也使其容易受到提示注入攻击。这些攻击利用模型遵循指令的能力来执行恶意任务。最近的研究提出了JATMO,一种特定于任务的微调方法,它训练非指令调整的基础模型来执行单一功能,从而降低对抗性指令的敏感性。本研究评估了JATMO针对HOUYI的鲁棒性,HOUYI是一个系统地变异和优化对抗性提示的遗传攻击框架。我们通过引入自定义适应度评分、修改后的变异逻辑以及用于本地模型测试的新工具来调整HOUYI,从而更准确地评估防御效果。我们根据JATMO方法微调了LLaMA 2-7B、Qwen1.5-4B和Qwen1.5-0.5B模型,并将其与微调的GPT-3.5-Turbo基线进行了比较。结果表明,虽然JATMO降低了相对于指令调整模型的攻击成功率,但它并不能完全阻止注入;利用多语言线索或代码相关破坏者的攻击仍然可以绕过防御。我们还观察到生成质量和注入漏洞之间的权衡,表明更好的任务性能通常与更高的敏感性相关。我们的结果突出了基于微调的防御的希望和局限性,并指出了对分层、对抗性知情的缓解策略的需求。
🔬 方法详解
问题定义:论文旨在评估JATMO方法在防御大型语言模型免受提示注入攻击方面的有效性。现有指令调整模型容易受到提示注入攻击,而JATMO试图通过任务特定的微调来限制模型的行为,降低其对恶意指令的敏感性。然而,JATMO的防御能力尚未得到充分评估,尤其是在面对系统性的对抗性攻击时。
核心思路:论文的核心思路是通过对抗性攻击来评估JATMO的鲁棒性。具体来说,作者使用改进的遗传算法框架HOUYI来生成和优化对抗性提示,并测试这些提示是否能够绕过JATMO的防御。这种方法能够系统地探索提示空间,找到最有效的攻击策略。
技术框架:整体框架包括以下几个主要步骤:1) 使用JATMO方法微调不同的语言模型(LLaMA 2-7B, Qwen1.5-4B, Qwen1.5-0.5B);2) 改进HOUYI攻击框架,包括自定义适应度评分、修改变异逻辑和本地模型测试工具;3) 使用改进的HOUYI框架生成对抗性提示,并测试这些提示对微调模型的攻击效果;4) 分析实验结果,评估JATMO的防御效果,并识别其局限性。
关键创新:论文的关键创新在于:1) 对HOUYI攻击框架进行了改进,使其更适合评估JATMO的防御能力。改进包括自定义适应度评分,以更准确地衡量攻击的成功程度;修改变异逻辑,以更有效地探索提示空间;以及引入本地模型测试工具,以提高评估的效率和准确性。2) 系统地评估了JATMO在面对对抗性攻击时的鲁棒性,揭示了其局限性,并指出了未来的改进方向。
关键设计:HOUYI的适应度函数被修改为更精确地反映攻击的成功率。变异逻辑也进行了调整,以生成更多样化和有效的对抗性提示。此外,还开发了一个本地模型测试工具,允许在本地环境中快速评估提示的有效性,而无需依赖远程API。
🖼️ 关键图片
📊 实验亮点
实验结果表明,JATMO虽然降低了相对于指令调整模型的攻击成功率,但仍无法完全阻止提示注入攻击。利用多语言线索或代码相关破坏者的攻击仍然可以绕过防御。此外,研究还发现生成质量和注入漏洞之间存在权衡,表明更好的任务性能通常与更高的敏感性相关。例如,某些模型在特定任务上表现更好,但更容易受到攻击。
🎯 应用场景
该研究成果可应用于提升大型语言模型在实际应用中的安全性,例如在聊天机器人、内容生成、代码助手等领域。通过对抗性测试评估和改进防御机制,可以降低模型被恶意利用的风险,保护用户数据和系统安全。研究结果有助于开发更可靠、更安全的LLM应用。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly being deployed in real-world applications, but their flexibility exposes them to prompt injection attacks. These attacks leverage the model's instruction-following ability to make it perform malicious tasks. Recent work has proposed JATMO, a task-specific fine-tuning approach that trains non-instruction-tuned base models to perform a single function, thereby reducing susceptibility to adversarial instructions. In this study, we evaluate the robustness of JATMO against HOUYI, a genetic attack framework that systematically mutates and optimizes adversarial prompts. We adapt HOUYI by introducing custom fitness scoring, modified mutation logic, and a new harness for local model testing, enabling a more accurate assessment of defense effectiveness. We fine-tuned LLaMA 2-7B, Qwen1.5-4B, and Qwen1.5-0.5B models under the JATMO methodology and compared them with a fine-tuned GPT-3.5-Turbo baseline. Results show that while JATMO reduces attack success rates relative to instruction-tuned models, it does not fully prevent injections; adversaries exploiting multilingual cues or code-related disruptors still bypass defenses. We also observe a trade-off between generation quality and injection vulnerability, suggesting that better task performance often correlates with increased susceptibility. Our results highlight both the promise and limitations of fine-tuning-based defenses and point toward the need for layered, adversarially informed mitigation strategies.