OmniFusion: Simultaneous Multilingual Multimodal Translations via Modular Fusion
作者: Sai Koneru, Matthias Huck, Jan Niehues
分类: cs.CL, cs.AI
发布日期: 2025-11-28
备注: Preprint for ACL 2026
🔗 代码/项目: GITHUB
💡 一句话要点
OmniFusion:通过模块化融合实现同步多语种多模态翻译
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态翻译 同步语音翻译 模块化融合 大型语言模型 跨模态学习
📋 核心要点
- 现有语音翻译系统依赖级联流程,导致延迟增加,尤其在同步翻译中,且无法有效利用多模态信息。
- OmniFusion提出一种端到端的多模态翻译方法,通过融合预训练MMFM和翻译LLM,实现跨模态信息的有效利用。
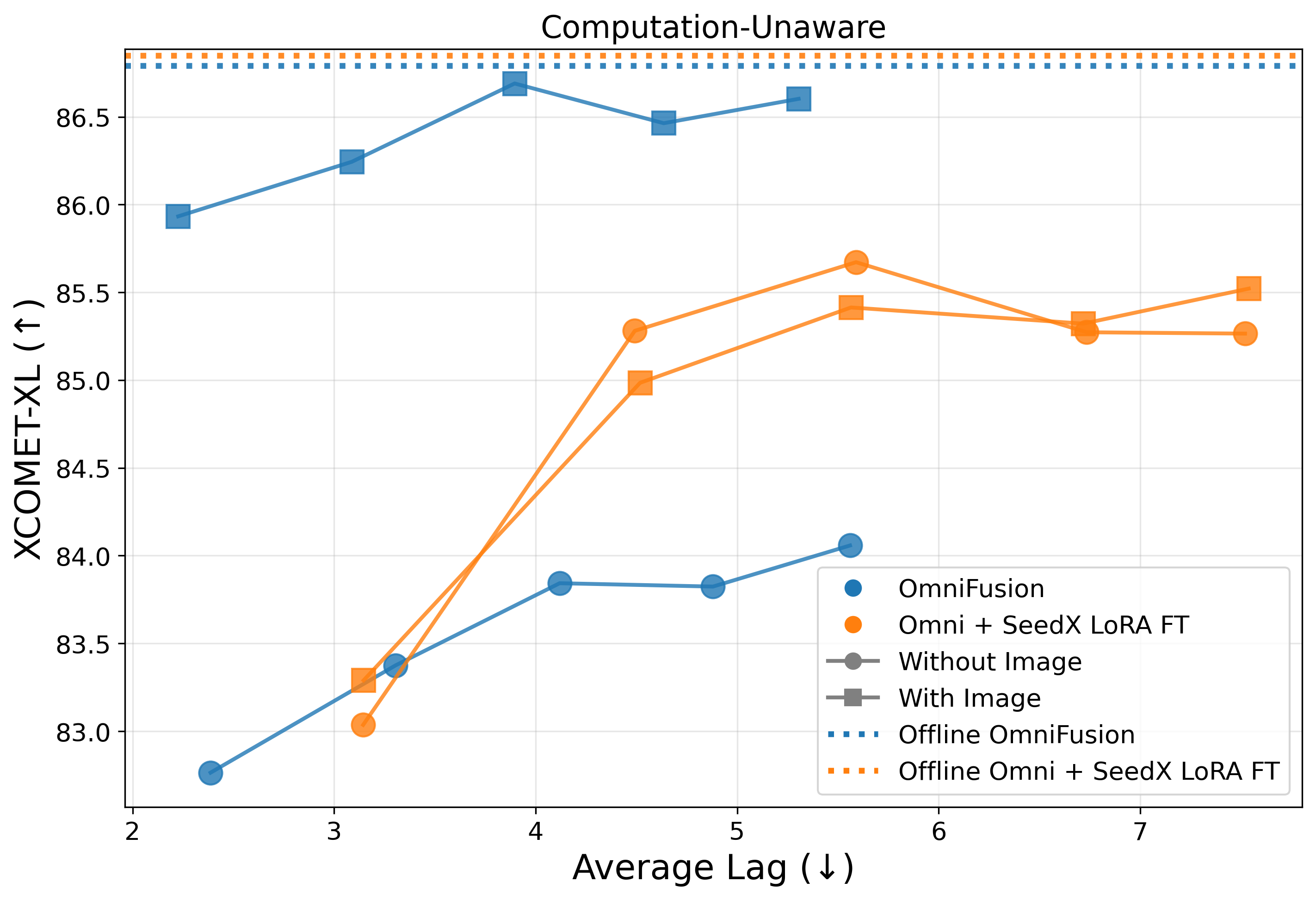
- 实验结果表明,OmniFusion在同步语音翻译中降低了1秒延迟,并提升了整体翻译质量,证明了其有效性。
📝 摘要(中文)
开源的纯文本翻译大型语言模型(LLM)在语言覆盖范围和质量方面取得了显著进展。然而,这些模型只能用于语音翻译(ST)的级联流程中,首先执行自动语音识别,然后进行翻译。这引入了额外的延迟,这在同步ST(SimulST)中尤其关键,并且阻止了模型利用多模态上下文(例如图像)进行消歧。预训练的多模态基础模型(MMFM)已经具备强大的跨多种模态的感知和推理能力,但通常缺乏专用翻译LLM的多语种覆盖范围和专业翻译性能。为了构建有效的多模态翻译系统,我们提出了一种融合MMFM和翻译LLM的端到端方法。我们引入了一种新颖的融合策略,将预训练MMFM多个隐藏层的状态连接到翻译LLM,从而实现联合端到端训练。由此产生的模型OmniFusion,基于Omni 2.5-7B作为MMFM和SeedX PPO-7B作为翻译LLM,可以执行语音到文本、语音和图像到文本以及文本和图像到文本的翻译。实验表明,OmniFusion有效地利用了音频和视觉输入,与级联流程相比,在SimulST中实现了1秒的延迟降低,并且还提高了整体翻译质量。
🔬 方法详解
问题定义:论文旨在解决多模态同步翻译中,现有级联系统延迟高、无法有效利用多模态信息的问题。现有方法通常先进行语音识别,再进行文本翻译,导致延迟,且忽略了图像等其他模态的信息,限制了翻译质量。
核心思路:核心思路是将预训练的多模态基础模型(MMFM)与翻译LLM进行融合,构建一个端到端的系统。通过直接利用MMFM的跨模态感知能力和翻译LLM的翻译能力,避免了级联流程的延迟,并允许模型同时利用语音、图像等多种模态的信息进行翻译。
技术框架:OmniFusion的整体框架包括一个预训练的MMFM(Omni 2.5-7B)和一个翻译LLM(SeedX PPO-7B)。关键在于一个新颖的融合策略,该策略将MMFM多个隐藏层的状态连接到翻译LLM。具体来说,MMFM的多个隐藏层输出被选择性地注入到翻译LLM的相应层中,从而实现跨模态信息的有效传递和融合。整个模型进行端到端训练,以优化多模态翻译性能。
关键创新:最关键的创新点在于提出的模块化融合策略,它允许将预训练的MMFM的隐藏状态灵活地注入到翻译LLM中。这种方法避免了从头开始训练一个大型多模态翻译模型的需求,而是利用了现有预训练模型的优势,实现了高效的多模态翻译。与传统的级联方法相比,OmniFusion实现了端到端的训练,减少了延迟,并允许模型更好地利用多模态信息。
关键设计:论文的关键设计包括选择合适的MMFM和翻译LLM,以及确定最佳的融合点。具体来说,Omni 2.5-7B被选为MMFM,因为它具有强大的多模态感知能力,而SeedX PPO-7B被选为翻译LLM,因为它具有出色的翻译性能。融合点(即MMFM的哪些隐藏层输出被注入到翻译LLM的哪些层)是通过实验确定的,以最大化多模态翻译性能。损失函数采用标准的交叉熵损失函数,用于优化翻译质量。
🖼️ 关键图片


📊 实验亮点
OmniFusion在同步语音翻译(SimulST)中实现了1秒的延迟降低,与级联流程相比,显著提升了实时性。此外,OmniFusion还提高了整体翻译质量,证明了其有效利用音频和视觉输入的能力。这些实验结果表明,OmniFusion是一种有前景的多模态翻译方法。
🎯 应用场景
OmniFusion具有广泛的应用前景,包括实时语音翻译、多媒体内容理解、辅助沟通等。例如,在国际会议中,OmniFusion可以提供低延迟、高质量的同步语音翻译服务。在教育领域,它可以帮助学生理解多媒体教学材料。在医疗领域,它可以辅助医生进行跨语言的交流和诊断。
📄 摘要(原文)
There has been significant progress in open-source text-only translation large language models (LLMs) with better language coverage and quality. However, these models can be only used in cascaded pipelines for speech translation (ST), performing automatic speech recognition first followed by translation. This introduces additional latency, which is particularly critical in simultaneous ST (SimulST), and prevents the model from exploiting multimodal context, such as images, which can aid disambiguation. Pretrained multimodal foundation models (MMFMs) already possess strong perception and reasoning capabilities across multiple modalities, but generally lack the multilingual coverage and specialized translation performance of dedicated translation LLMs. To build an effective multimodal translation system, we propose an end-to-end approach that fuses MMFMs with translation LLMs. We introduce a novel fusion strategy that connects hidden states from multiple layers of a pretrained MMFM to a translation LLM, enabling joint end-to-end training. The resulting model, OmniFusion, built on Omni 2.5-7B as the MMFM and SeedX PPO-7B as the translation LLM, can perform speech-to-text, speech-and-image-to-text, and text-and-image-to-text translation. Experiments demonstrate that OmniFusion effectively leverages both audio and visual inputs, achieves a 1-second latency reduction in SimulST compared to cascaded pipelines and also improves the overall translation quality\footnote{Code is available at https://github.com/saikoneru/OmniFusion}.