Optimizing Multimodal Language Models through Attention-based Interpretability
作者: Alexander Sergeev, Evgeny Kotelnikov
分类: cs.CL, cs.CV
发布日期: 2025-11-28
备注: Accepted for ICAI-2025 conference
💡 一句话要点
提出基于注意力机制可解释性的多模态语言模型优化方法,提升参数高效微调性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态语言模型 参数高效微调 注意力机制 可解释性 图像描述
📋 核心要点
- 现有MLM全量微调计算成本高,参数高效微调难以确定最佳训练组件。
- 提出基于注意力机制的可解释性方法,识别关注图像关键对象的注意力头,指导PEFT。
- 实验表明,微调高HI分数的层能显著提升图像理解能力,仅需微调少量参数。
📝 摘要(中文)
现代大型语言模型正朝着多模态方向发展,能够分析文本和图像等多种数据格式。虽然微调是使这些多模态语言模型(MLM)适应下游任务的有效方法,但全量微调计算成本高昂。参数高效微调(PEFT)方法通过仅训练一小部分模型权重来解决这个问题。然而,MLM难以解释,因此很难确定哪些组件对于平衡效率和性能的训练最有效。我们提出了一种基于注意力机制的可解释性方法,通过分析相对于图像token的注意力分数来优化MLM。核心思想是识别关注图像关键对象的注意力头。我们利用这些信息来选择多模态模型中PEFT的最佳模型组件。我们的贡献包括一种识别与图像关键对象相关的注意力头的方法,将其应用于图像描述的PEFT,以及创建一个包含图像、关键对象掩码及其文本描述的新数据集。我们对具有20-30亿参数的MLM进行了实验,以验证该方法的有效性。通过计算头部影响(HI)分数,我们量化了一个注意力头对关键对象的关注程度,表明其在图像理解中的重要性。我们的微调实验表明,与预训练、随机选择或最低HI分数的层相比,调整具有最高HI分数的层会导致指标发生最显著的变化。这表明,在这些关键层中微调一小部分(约0.01%)的参数可以显著影响图像理解能力。
🔬 方法详解
问题定义:论文旨在解决多模态语言模型(MLM)在参数高效微调(PEFT)过程中,难以确定哪些模型组件对性能提升贡献最大的问题。现有方法要么随机选择微调的参数,要么依赖经验,缺乏对模型内部机制的理解,导致效率低下,性能提升有限。
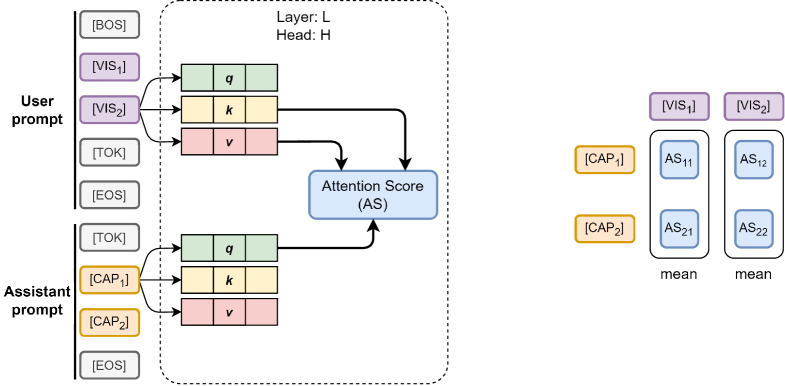
核心思路:论文的核心思路是利用注意力机制的可解释性,通过分析注意力头对图像关键对象的关注程度,来量化不同模型组件的重要性。具体来说,通过计算“头部影响”(Head Impact, HI)分数,评估每个注意力头在图像理解中的作用,从而指导PEFT过程,优先微调对图像理解至关重要的组件。
技术框架:该方法主要包含以下几个阶段:1) 数据准备:构建包含图像、关键对象掩码和文本描述的数据集。2) 注意力分析:计算MLM中每个注意力头对图像token的注意力分数。3) 头部影响评估:根据注意力分数和关键对象掩码,计算每个注意力头的HI分数。4) 参数高效微调:根据HI分数选择需要微调的模型组件,并使用PEFT方法进行微调。5) 性能评估:在下游任务上评估微调后的MLM性能。
关键创新:该方法最重要的创新点在于提出了一种基于注意力机制的可解释性方法,用于指导多模态语言模型的参数高效微调。与现有方法相比,该方法能够更准确地识别对图像理解至关重要的模型组件,从而实现更高效、更有效的微调。
关键设计:关键设计包括:1) HI分数的计算方式,需要合理定义注意力分数与关键对象掩码之间的关系,以准确反映注意力头的重要性。2) PEFT方法的选择,需要根据具体任务和模型结构选择合适的PEFT方法,例如LoRA或Adapter。3) 数据集的构建,需要保证数据集包含足够多的图像和关键对象掩码,以支持注意力分析和HI分数计算。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过微调具有最高HI分数的层,可以显著提升MLM在图像描述任务上的性能。与随机选择层或微调低HI分数层相比,该方法能够以更少的参数量(约0.01%)实现更大的性能提升,验证了基于注意力机制可解释性的参数高效微调方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要多模态理解的场景,例如图像描述生成、视觉问答、图像检索等。通过高效地微调多模态语言模型,可以提升这些应用在资源受限环境下的性能,并降低部署成本。未来,该方法有望推广到其他模态和模型结构,进一步提升多模态人工智能系统的性能和可解释性。
📄 摘要(原文)
Modern large language models become multimodal, analyzing various data formats like text and images. While fine-tuning is effective for adapting these multimodal language models (MLMs) to downstream tasks, full fine-tuning is computationally expensive. Parameter-Efficient Fine-Tuning (PEFT) methods address this by training only a small portion of model weights. However, MLMs are difficult to interpret, making it challenging to identify which components are most effective for training to balance efficiency and performance. We propose an attention-based interpretability method for MLMs by analyzing attention scores relative to image tokens. The core idea is to identify attention heads that focus on image key objects. We utilize this information to select optimal model components for PEFT in multimodal models. Our contributions include a method for identifying attention heads associated with image key objects, its application to PEFT for image captioning, and the creation of a new dataset containing images, key object masks, and their textual descriptions. We conducted experiments on MLMs with 2-3 billion parameters to validate the method's effectiveness. By calculating Head Impact (HI) scores we quantify an attention head's focus on key objects, indicating its significance in image understanding. Our fine-tuning experiments demonstrate that adapting layers with the highest HI scores leads to the most significant shifts in metrics compared to pre-trained, randomly selected, or lowest-HI-score layers. This indicates that fine-tuning a small percentage (around 0.01%) of parameters in these crucial layers can substantially influence image understanding capabilities.