Every Token Counts: Generalizing 16M Ultra-Long Context in Large Language Models
作者: Xiang Hu, Zhanchao Zhou, Ruiqi Liang, Zehuan Li, Wei Wu, Jianguo Li
分类: cs.CL, cs.AI
发布日期: 2025-11-28
💡 一句话要点
提出HSA-UltraLong模型,实现16M超长上下文建模并具备长度泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 超长上下文建模 稀疏注意力 分层注意力 Transformer MoE 长度泛化 大型语言模型
📋 核心要点
- 现有长文本建模方法在处理超长上下文时面临效率、灵活性和泛化性挑战。
- 论文提出分层稀疏注意力(HSA)机制,兼顾稀疏性、随机访问灵活性和长度泛化能力。
- HSA-UltraLong模型在16M上下文长度下,检索任务准确率超过90%,性能与全注意力模型相当。
📝 摘要(中文)
本文旨在解决构建“能够记忆的机器”这一挑战,将长期记忆建模视为高效的超长上下文建模问题。作者认为,这需要三个关键属性:稀疏性、随机访问灵活性和长度泛化能力。为了解决超长上下文建模问题,作者利用分层稀疏注意力(HSA),这是一种满足所有三个属性的新型注意力机制。他们将HSA集成到Transformer中,构建了HSA-UltraLong模型,这是一个拥有80亿参数的MoE模型,在超过8万亿个token上进行训练,并在不同任务上进行了严格评估,包括领域内和领域外上下文长度,以证明其处理超长上下文的能力。结果表明,该模型在领域内长度上与全注意力基线模型表现相当,同时在大多数上下文检索任务中,上下文长度高达16M时,准确率超过90%。本报告概述了实验见解和未解决的问题,为未来超长上下文建模的研究贡献了基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在超长上下文建模中面临的挑战。现有方法,如全注意力机制,在处理极长序列时计算复杂度过高,难以应用。此外,现有方法在长度泛化能力方面存在不足,即在训练时使用的上下文长度与实际应用中的长度不一致时,性能会显著下降。
核心思路:论文的核心思路是利用稀疏注意力机制来降低计算复杂度,并设计一种分层结构来提高模型的随机访问灵活性和长度泛化能力。通过稀疏化注意力矩阵,可以显著减少计算量,从而能够处理更长的上下文。分层结构允许模型在不同粒度上进行信息交互,从而更好地捕捉长距离依赖关系。
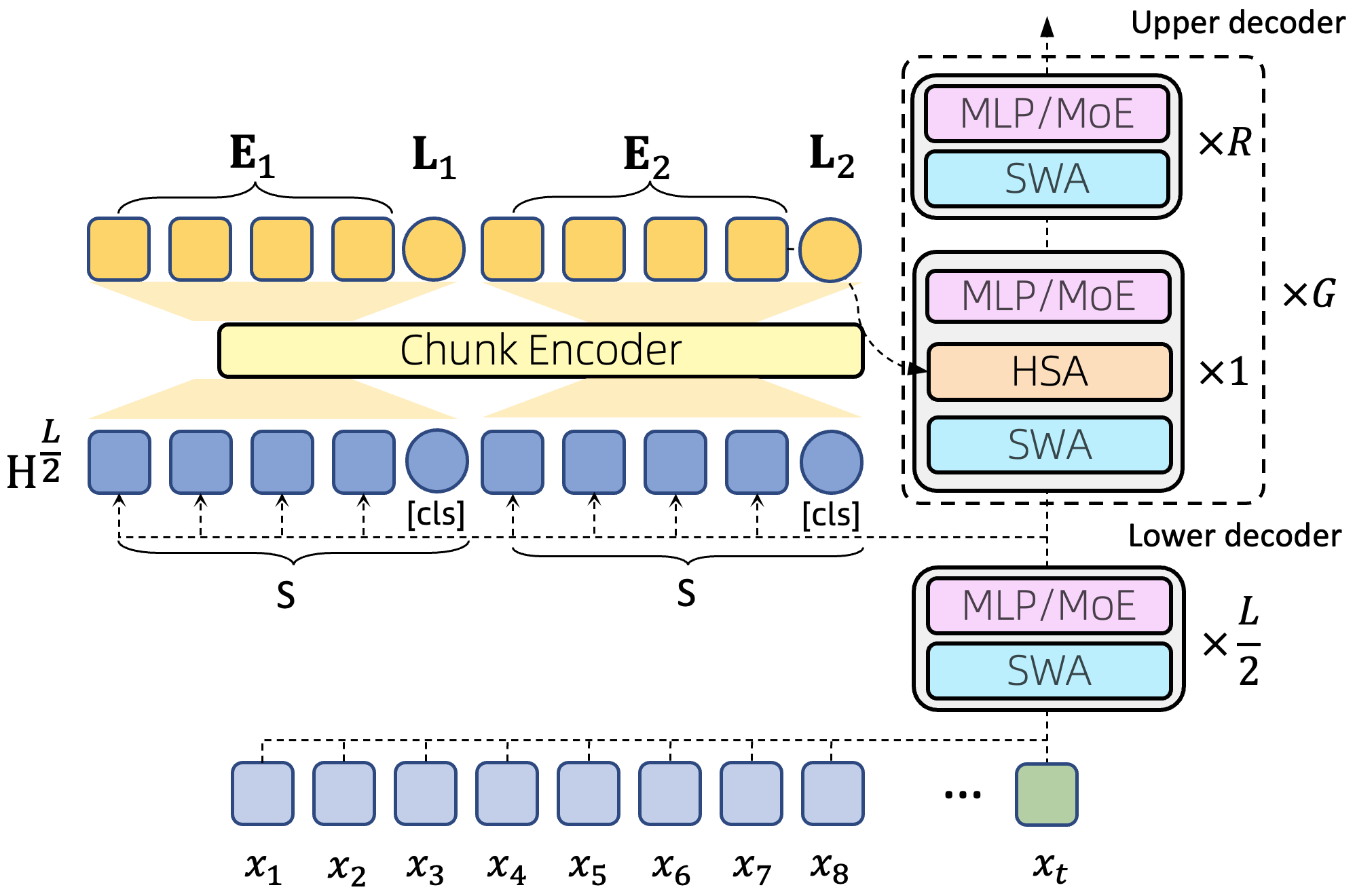
技术框架:HSA-UltraLong模型基于Transformer架构,并用提出的HSA机制替换了传统的全注意力机制。整体流程包括:输入文本嵌入、多层HSA Transformer编码、输出表示。模型采用MoE(Mixture of Experts)结构,进一步提升模型容量和性能。训练过程包括预训练和微调两个阶段。
关键创新:最重要的技术创新点是分层稀疏注意力(HSA)机制。与传统的稀疏注意力机制不同,HSA采用分层结构,允许模型在不同层级上进行稀疏化,从而更好地平衡计算效率和模型表达能力。此外,HSA的设计考虑了随机访问灵活性和长度泛化能力,使其能够更好地处理不同长度的上下文。
关键设计:HSA机制的关键设计包括:1) 分层结构:将注意力计算分为多个层级,每个层级采用不同的稀疏模式。2) 稀疏模式选择:采用启发式或学习的方法选择合适的稀疏模式,以最大化模型性能。3) MoE结构:采用多个专家网络,并根据输入动态选择合适的专家进行处理,从而提高模型容量和泛化能力。损失函数包括语言模型损失和MoE路由损失。
🖼️ 关键图片


📊 实验亮点
HSA-UltraLong模型在16M上下文长度的检索任务中取得了超过90%的准确率,与全注意力模型在较短上下文长度下的性能相当。该模型在领域外数据集上也表现出良好的泛化能力,证明了其在处理超长上下文方面的有效性。此外,该模型在8万亿token上进行了训练,是目前训练数据量最大的长文本模型之一。
🎯 应用场景
该研究成果可应用于需要处理超长文本的各种场景,例如:长篇小说续写、法律文档分析、科学论文总结、医疗记录处理、客服对话管理等。通过提升模型处理长文本的能力,可以更好地理解和利用海量信息,为各行业提供更智能化的解决方案,并推动人工智能在长文本理解领域的进一步发展。
📄 摘要(原文)
This work explores the challenge of building ``Machines that Can Remember'', framing long-term memory as the problem of efficient ultra-long context modeling. We argue that this requires three key properties: \textbf{sparsity}, \textbf{random-access flexibility}, and \textbf{length generalization}. To address ultra-long-context modeling, we leverage Hierarchical Sparse Attention (HSA), a novel attention mechanism that satisfies all three properties. We integrate HSA into Transformers to build HSA-UltraLong, which is an 8B-parameter MoE model trained on over 8 trillion tokens and is rigorously evaluated on different tasks with in-domain and out-of-domain context lengths to demonstrate its capability in handling ultra-long contexts. Results show that our model performs comparably to full-attention baselines on in-domain lengths while achieving over 90\% accuracy on most in-context retrieval tasks with contexts up to 16M. This report outlines our experimental insights and open problems, contributing a foundation for future research in ultra-long context modeling.