MCP vs RAG vs NLWeb vs HTML: A Comparison of the Effectiveness and Efficiency of Different Agent Interfaces to the Web (Technical Report)
作者: Aaron Steiner, Ralph Peeters, Christian Bizer
分类: cs.CL
发布日期: 2025-11-28
💡 一句话要点
对比LLM Agent与Web交互的多种界面,揭示RAG、MCP和NLWeb优于HTML
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent Web交互界面 HTML RAG MCP NLWeb 自动化Web任务
📋 核心要点
- 现有方法在利用大型语言模型Agent进行Web任务自动化时,缺乏对不同交互界面的系统性比较。
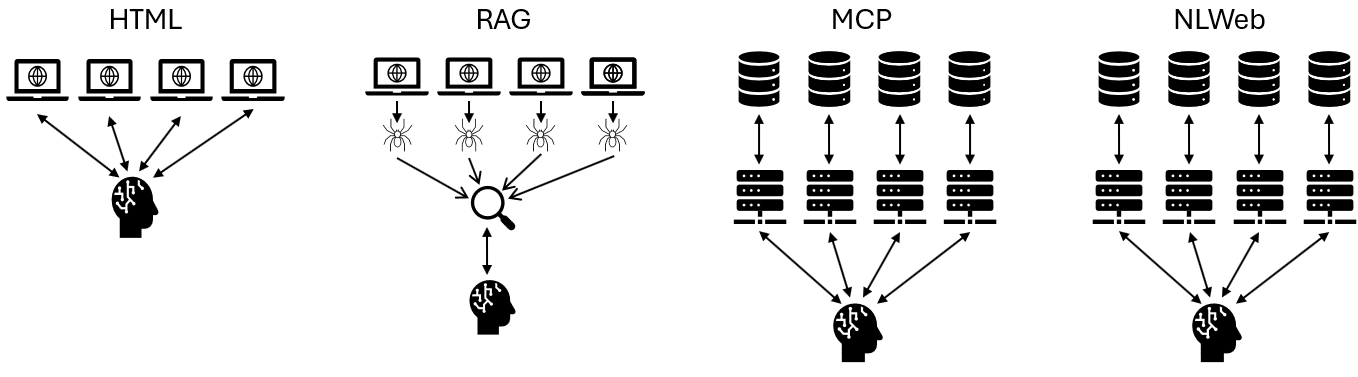
- 本文提出一个测试平台,模拟电商环境,并针对HTML、RAG、MCP和NLWeb四种界面开发专门的Agent。
- 实验结果表明,RAG、MCP和NLWeb Agent在有效性和效率上均优于HTML,RAG与GPT 5组合表现最佳。
📝 摘要(中文)
大型语言模型Agent越来越多地被用于自动化Web任务,如产品搜索、报价比较和结账。目前的研究探索了Agent与网站交互的不同界面,包括传统的HTML浏览、基于预爬取内容的检索增强生成(RAG)、使用模型上下文协议(MCP)通过Web API进行通信,以及通过NLWeb界面进行自然语言查询。为了填补空白,本文构建了一个测试平台,包含四个模拟电商,每个电商都通过HTML、MCP和NLWeb接口提供产品。针对每种接口,开发专门的Agent来执行相同的任务集。使用GPT 4.1、GPT 5、GPT 5 mini和Claude Sonnet 4作为底层LLM进行评估。结果表明,RAG、MCP和NLWeb Agent在有效性和效率上均优于HTML。平均而言,F1分数从HTML的0.67提高到其他Agent的0.75到0.77之间。Token使用量从HTML的约241k降至每个任务的47k到140k之间。每个任务的运行时间从291秒降至50到62秒之间。RAG与GPT 5的组合表现最佳,F1分数为0.87,完成率为0.79。综合考虑成本,RAG与GPT 5 mini在API使用费和性能之间取得了良好的平衡。实验表明,交互界面的选择对基于LLM的Web Agent的有效性和效率有显著影响。
🔬 方法详解
问题定义:论文旨在解决大型语言模型Agent与Web交互时,不同交互界面(HTML、RAG、MCP、NLWeb)的性能差异问题。现有方法缺乏在一个统一的受控环境中对这些界面进行比较,难以确定哪种界面更适合特定Web任务。
核心思路:核心思路是通过构建一个模拟电商环境,并针对每种交互界面开发专门的Agent,执行相同的任务集,从而在相同的条件下比较它们的性能。这样可以消除由于任务或环境差异带来的偏差,更客观地评估不同界面的优劣。
技术框架:整体框架包括以下几个主要部分:1) 构建包含HTML、MCP和NLWeb三种接口的模拟电商环境;2) 针对每种接口开发专门的Agent;3) 定义一系列Web任务,包括产品搜索、价格比较、互补/替代产品查询和结账流程;4) 使用不同的LLM(GPT 4.1、GPT 5、GPT 5 mini、Claude Sonnet 4)作为Agent的底层模型;5) 评估Agent在不同界面和LLM下的性能,指标包括F1分数、Token使用量和运行时间。
关键创新:最重要的创新点在于构建了一个统一的测试平台,能够在一个受控的环境中比较不同Web交互界面的性能。此外,针对每种界面开发专门的Agent,并使用相同的任务集进行评估,保证了比较的公平性和客观性。
关键设计:关键设计包括:1) 模拟电商环境的设计,需要保证各种接口的可用性和功能完整性;2) Agent的设计,需要针对不同的接口选择合适的交互方式和策略;3) 任务的设计,需要覆盖常见的Web任务,并具有一定的复杂性;4) 评估指标的选择,需要能够全面反映Agent的性能,包括有效性、效率和成本。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RAG、MCP和NLWeb Agent在有效性和效率上均优于HTML。平均而言,F1分数从HTML的0.67提高到其他Agent的0.75到0.77之间。Token使用量从HTML的约241k降至每个任务的47k到140k之间。每个任务的运行时间从291秒降至50到62秒之间。RAG与GPT 5的组合表现最佳,F1分数为0.87,完成率为0.79。
🎯 应用场景
该研究成果可应用于电商、信息检索、智能助手等领域,帮助开发者选择更合适的Web交互界面,提升LLM Agent的性能和用户体验。例如,电商平台可以根据该研究选择更高效的界面,优化用户购物流程;智能助手可以利用该研究提升Web任务的自动化能力。
📄 摘要(原文)
Large language model agents are increasingly used to automate web tasks such as product search, offer comparison, and checkout. Current research explores different interfaces through which these agents interact with websites, including traditional HTML browsing, retrieval-augmented generation (RAG) over pre-crawled content, communication via Web APIs using the Model Context Protocol (MCP), and natural-language querying through the NLWeb interface. However, no prior work has compared these four architectures within a single controlled environment using identical tasks. To address this gap, we introduce a testbed consisting of four simulated e-shops, each offering its products via HTML, MCP, and NLWeb interfaces. For each interface (HTML, RAG, MCP, and NLWeb) we develop specialized agents that perform the same sets of tasks, ranging from simple product searches and price comparisons to complex queries for complementary or substitute products and checkout processes. We evaluate the agents using GPT 4.1, GPT 5, GPT 5 mini, and Claude Sonnet 4 as underlying LLM. Our evaluation shows that the RAG, MCP and NLWeb agents outperform HTML on both effectiveness and efficiency. Averaged over all tasks, F1 rises from 0.67 for HTML to between 0.75 and 0.77 for the other agents. Token usage falls from about 241k for HTML to between 47k and 140k per task. The runtime per task drops from 291 seconds to between 50 and 62 seconds. The best overall configuration is RAG with GPT 5 achieving an F1 score of 0.87 and a completion rate of 0.79. Also taking cost into consideration, RAG with GPT 5 mini offers a good compromise between API usage fees and performance. Our experiments show the choice of the interaction interface has a substantial impact on both the effectiveness and efficiency of LLM-based web agents.