Tourism Question Answer System in Indian Language using Domain-Adapted Foundation Models
作者: Praveen Gatla, Anushka, Nikita Kanwar, Gouri Sahoo, Rajesh Kumar Mundotiya
分类: cs.CL, cs.AI
发布日期: 2025-11-28
💡 一句话要点
提出基于领域自适应预训练模型的印地语旅游问答系统,解决文化背景下的语言资源匮乏问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 印地语问答系统 旅游领域 预训练模型 低秩适应 领域自适应 数据增强 文化背景
📋 核心要点
- 现有印地语旅游领域问答系统缺乏,尤其是在文化背景下,高质量标注数据稀缺,通用模型难以捕捉文化细微差别。
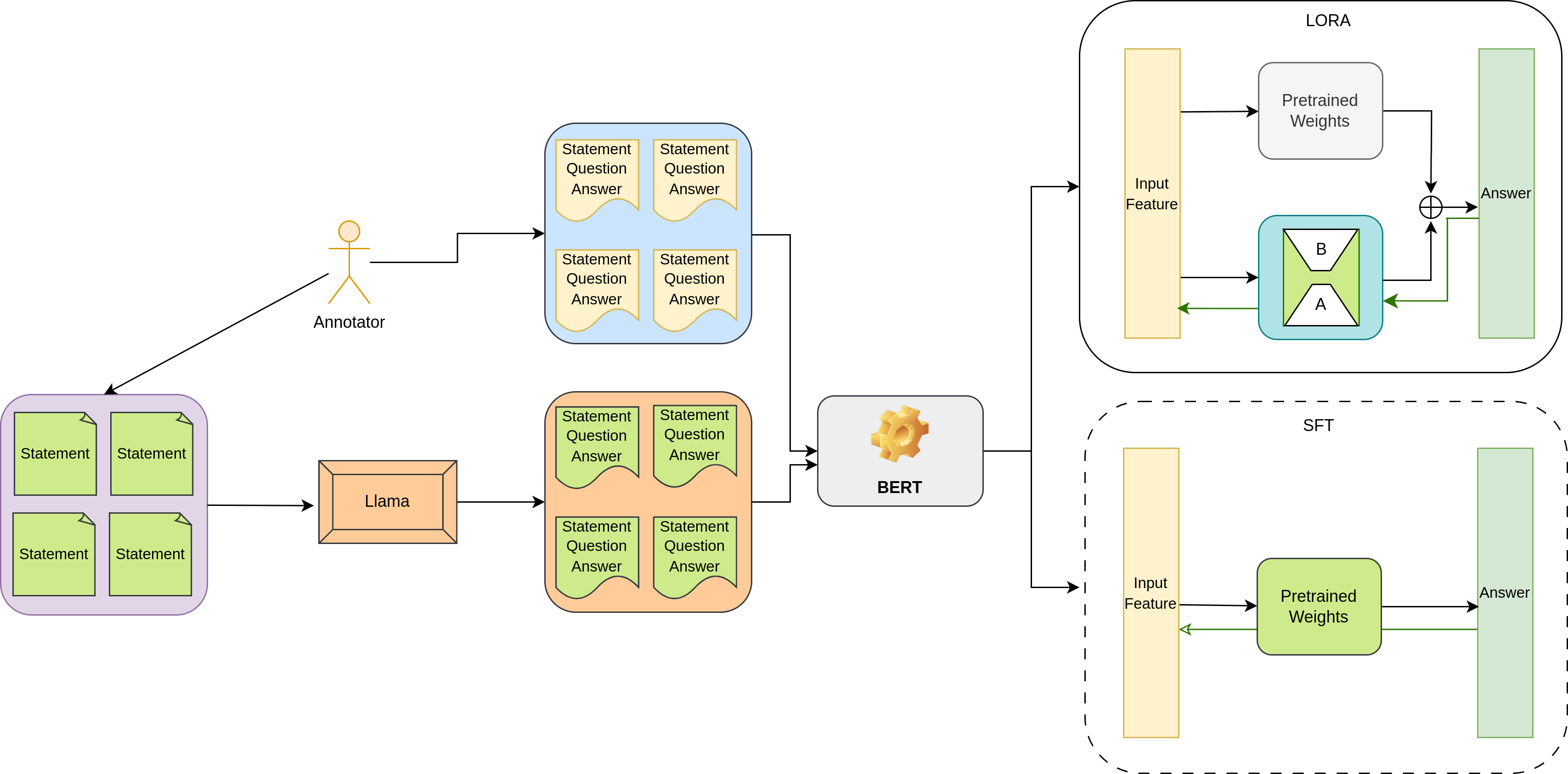
- 利用BERT和RoBERTa等预训练模型,结合监督微调(SFT)和低秩适应(LoRA)技术,构建高效且准确的问答系统。
- 实验表明,LoRA微调在保证性能(85.3% F1)的同时,显著降低了训练参数量(减少98%),RoBERTa在文化术语理解上更胜一筹。
📝 摘要(中文)
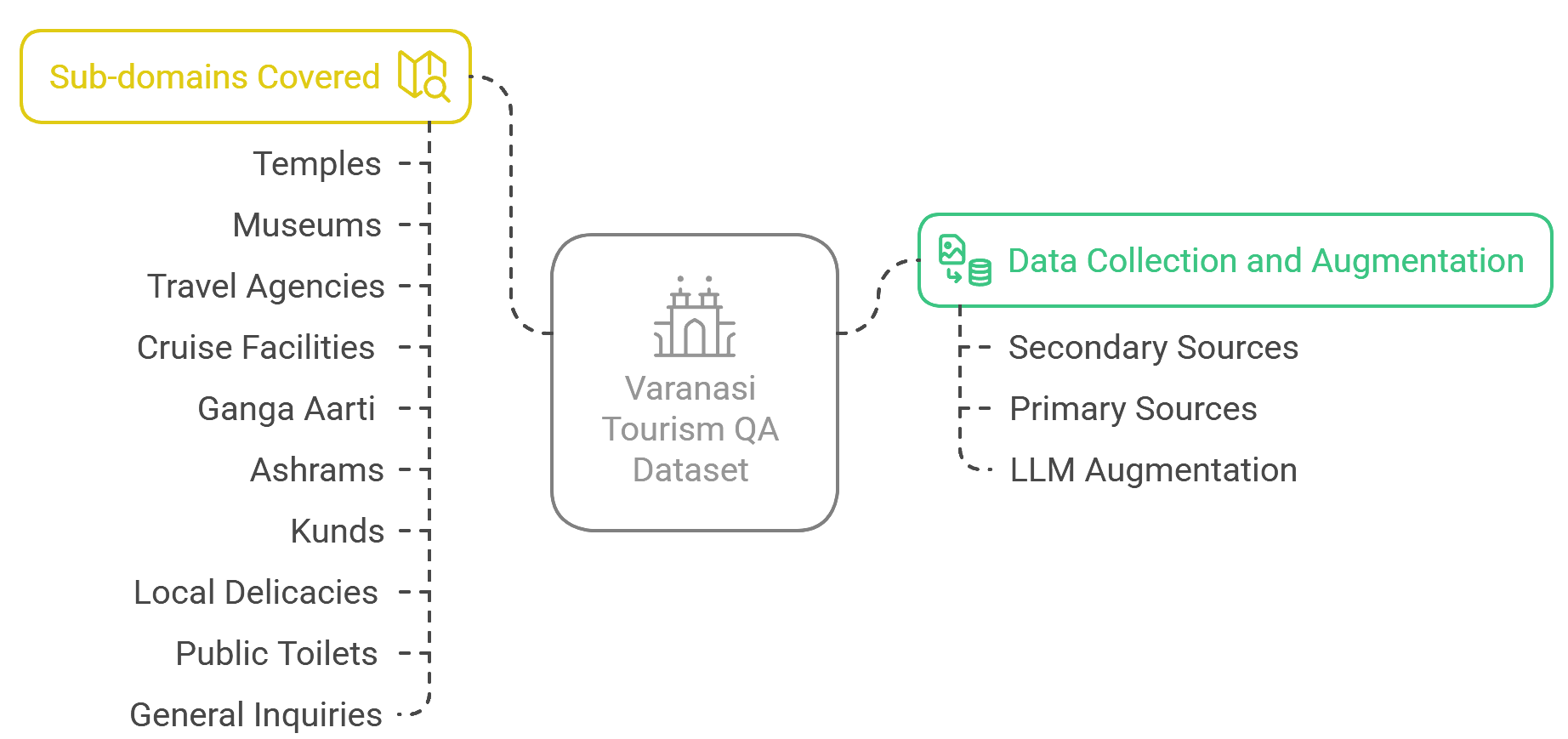
本文首次全面研究了印地语旅游领域(特别是瓦拉纳西)的抽取式问答(QA)系统的设计基线。针对恒河夜祭、游船、美食广场、公共厕所、水池、博物馆、通用信息、修行所、寺庙和旅行等十个旅游子领域,解决了印地语中缺乏针对文化细微差别的QA资源的问题。构建了一个包含7715个与瓦拉纳西旅游相关的印地语QA对的数据集,并通过Llama零样本提示生成了27455个QA对进行扩充。提出了一个利用BERT和RoBERTa等预训练模型,通过监督微调(SFT)和低秩适应(LoRA)进行微调的框架,以优化参数效率和任务性能。评估了BERT的多个变体(包括预训练语言模型,如Hindi-BERT),以评估其在低资源领域特定QA中的适用性。评估指标包括F1、BLEU和ROUGE-L,突出了答案精度和语言流畅性之间的权衡。实验表明,基于LoRA的微调实现了具有竞争力的性能(85.3% F1),同时与SFT相比,可训练参数减少了98%,从而在效率和准确性之间取得了平衡。跨模型的比较分析表明,RoBERTa与SFT在捕获上下文细微差别方面优于BERT变体,尤其是在文化嵌入式术语(例如,Aarti,Kund)方面。这项工作为印地语旅游QA系统建立了基础基线,强调了LORA在低资源环境中的作用,并强调了旅游领域中文化背景化的NLP框架的需求。
🔬 方法详解
问题定义:论文旨在解决印地语旅游领域,特别是瓦拉纳西地区的问答系统构建问题。现有方法主要痛点在于缺乏针对该领域和语言的专用数据集,以及通用预训练模型难以捕捉文化相关的细微语义信息。
核心思路:核心思路是利用领域自适应的预训练模型,并通过高效的微调方法(LoRA)来克服数据稀缺和计算资源有限的问题。通过在旅游领域数据上微调预训练模型,使其更好地理解和生成相关文本。
技术框架:整体框架包括数据构建、模型选择与微调、以及评估三个主要阶段。首先,构建包含7715个QA对的初始数据集,并使用Llama模型生成27455个QA对进行数据增强。然后,选择BERT和RoBERTa等预训练模型,并使用SFT和LoRA两种方法进行微调。最后,使用F1、BLEU和ROUGE-L等指标评估模型性能。
关键创新:关键创新在于将LoRA技术应用于印地语旅游问答系统,在保证模型性能的同时,显著降低了训练参数量,使得在低资源环境下也能训练出有效的问答模型。此外,该研究还强调了文化背景对于问答系统的重要性,并针对性地评估了模型在处理文化相关术语时的表现。
关键设计:在数据增强阶段,使用Llama模型进行零样本提示生成QA对。在模型微调阶段,比较了SFT和LoRA两种方法,LoRA通过引入低秩矩阵来更新模型参数,从而减少了需要训练的参数数量。实验中,针对BERT和RoBERTa的不同变体进行了评估,并选择了合适的超参数进行训练。
🖼️ 关键图片

📊 实验亮点
实验结果表明,基于LoRA的微调方法在印地语旅游问答任务上取得了具有竞争力的性能(F1值达到85.3%),同时相比于传统的SFT方法,可训练参数减少了98%。RoBERTa模型在处理文化相关的术语时表现优于BERT模型,表明其具有更强的上下文理解能力。
🎯 应用场景
该研究成果可应用于构建智能旅游助手,为游客提供关于景点、文化习俗、交通、餐饮等方面的印地语问答服务。有助于提升游客的旅游体验,促进当地旅游业发展,并为其他低资源语言的领域特定问答系统提供参考。
📄 摘要(原文)
This article presents the first comprehensive study on designing a baseline extractive question-answering (QA) system for the Hindi tourism domain, with a specialized focus on the Varanasi-a cultural and spiritual hub renowned for its Bhakti-Bhaav (devotional ethos). Targeting ten tourism-centric subdomains-Ganga Aarti, Cruise, Food Court, Public Toilet, Kund, Museum, General, Ashram, Temple and Travel, the work addresses the absence of language-specific QA resources in Hindi for culturally nuanced applications. In this paper, a dataset comprising 7,715 Hindi QA pairs pertaining to Varanasi tourism was constructed and subsequently augmented with 27,455 pairs generated via Llama zero-shot prompting. We propose a framework leveraging foundation models-BERT and RoBERTa, fine-tuned using Supervised Fine-Tuning (SFT) and Low-Rank Adaptation (LoRA), to optimize parameter efficiency and task performance. Multiple variants of BERT, including pre-trained languages (e.g., Hindi-BERT), are evaluated to assess their suitability for low-resource domain-specific QA. Evaluation metrics - F1, BLEU, and ROUGE-L - highlight trade-offs between answer precision and linguistic fluency. Experiments demonstrate that LoRA-based fine-tuning achieves competitive performance (85.3\% F1) while reducing trainable parameters by 98\% compared to SFT, striking a balance between efficiency and accuracy. Comparative analysis across models reveals that RoBERTa with SFT outperforms BERT variants in capturing contextual nuances, particularly for culturally embedded terms (e.g., Aarti, Kund). This work establishes a foundational baseline for Hindi tourism QA systems, emphasizing the role of LORA in low-resource settings and underscoring the need for culturally contextualized NLP frameworks in the tourism domain.