Mind Reading or Misreading? LLMs on the Big Five Personality Test
作者: Francesco Di Cursi, Chiara Boldrini, Marco Conti, Andrea Passarella
分类: cs.CL, cs.AI
发布日期: 2025-11-28
备注: Funding: SoBigDatait (IR0000013), FAIR (PE00000013), ICSC (CN00000013)
💡 一句话要点
评估大语言模型在五因素人格测试中的表现,揭示其在人格预测中的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 人格预测 五因素模型 提示工程 零样本学习
📋 核心要点
- 现有方法在利用LLM进行人格预测时,缺乏对不同提示策略和评估指标的系统性研究,导致结果不稳定且难以解释。
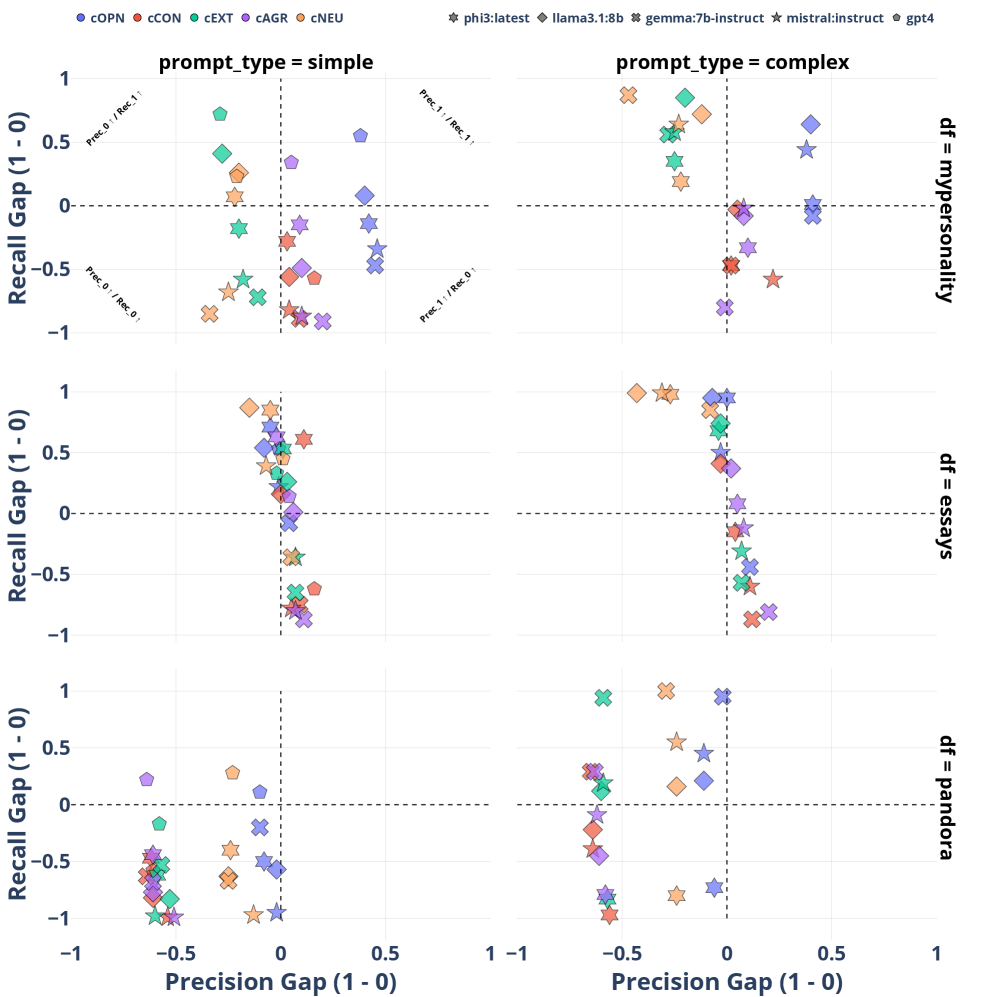
- 该研究探索了不同提示策略(最小化与富含信息)对LLM人格预测的影响,并采用更细粒度的评估指标(如每类召回率)来诊断模型性能。
- 实验表明,富含信息的提示虽能改善类别平衡,但会引入偏差;且现有LLM在零样本二元设置下,人格预测的可靠性仍有待提高。
📝 摘要(中文)
本文评估了大语言模型(LLMs)在二元五因素模型(BIG5)下,从文本自动预测人格的能力。研究测试了五个模型——包括GPT-4和轻量级开源替代方案——在三个异构数据集(Essays, MyPersonality, Pandora)和两种提示策略(最小化提示与富含语言和心理线索的提示)上的表现。富含信息的提示减少了无效输出并改善了类别平衡,但也引入了预测特质存在的系统性偏差。性能差异显著:开放性和宜人性相对容易检测,而外向性和神经质仍然具有挑战性。虽然开源模型有时接近GPT-4和先前的基准,但没有一种配置能在零样本二元设置中产生始终可靠的预测。此外,诸如准确率和宏F1等聚合指标掩盖了显著的不对称性,而每类召回率提供了更清晰的诊断价值。这些发现表明,当前开箱即用的大语言模型还不适合用于自动人格预测,并且提示设计、特质框架和评估指标的仔细协调对于可解释的结果至关重要。
🔬 方法详解
问题定义:论文旨在评估大语言模型(LLMs)在五因素人格模型(BIG5)下的自动人格预测能力。现有方法,即直接使用LLMs进行人格预测,存在以下痛点:1) 缺乏对不同提示策略的系统性研究,导致结果不稳定;2) 常用评估指标(如准确率)掩盖了类别间的不对称性,难以诊断模型性能;3) 缺乏对开源LLM在人格预测任务中能力的充分评估。
核心思路:论文的核心思路是通过系统性地测试不同LLM、不同提示策略和不同评估指标,来深入理解LLM在人格预测任务中的优势和局限性。通过比较最小化提示和富含语言/心理线索的提示,分析提示策略对预测结果的影响。通过采用每类召回率等细粒度指标,更准确地评估模型在不同人格特质上的表现。
技术框架:该研究的技术框架主要包括以下几个部分:1) 数据集选择:使用三个异构数据集(Essays, MyPersonality, Pandora),以保证评估的泛化性。2) 模型选择:选择GPT-4作为代表性的高性能LLM,并选取多个轻量级开源LLM作为对比。3) 提示策略设计:设计两种提示策略,分别是最小化提示和富含语言/心理线索的提示。4) 评估指标选择:采用准确率、宏F1和每类召回率等指标,全面评估模型性能。
关键创新:该研究的关键创新在于:1) 系统性地研究了不同提示策略对LLM人格预测的影响,揭示了富含信息的提示可能引入偏差的问题。2) 强调了使用细粒度评估指标(如每类召回率)的重要性,以便更准确地诊断模型在不同人格特质上的表现。3) 对比了GPT-4和开源LLM在人格预测任务中的性能,为选择合适的模型提供了参考。
关键设计:在提示策略设计方面,富含信息的提示包含语言和心理线索,旨在引导LLM更好地理解人格特质。例如,提示中可能包含对特定人格特质的定义、相关行为的描述等。在评估指标方面,每类召回率用于衡量模型在预测特定人格特质时的能力,可以有效揭示模型在不同类别上的性能差异。
🖼️ 关键图片


📊 实验亮点
实验结果表明,开放性和宜人性相对容易被LLM检测,而外向性和神经质则更具挑战性。富含信息的提示虽然可以改善类别平衡,但也引入了系统性偏差,倾向于预测特质的存在。虽然开源模型有时能接近GPT-4的性能,但没有一种配置能在零样本二元设置中产生始终可靠的预测。此外,准确率和宏F1等聚合指标掩盖了显著的不对称性,每类召回率提供了更清晰的诊断价值。
🎯 应用场景
该研究结果可应用于心理学研究、人机交互、个性化推荐等领域。例如,可以帮助心理学家更好地理解LLM在人格评估方面的能力,为开发更智能的人机交互系统提供参考,或用于构建更精准的个性化推荐模型。然而,需要注意的是,当前LLM在人格预测方面的可靠性仍有待提高,因此在实际应用中应谨慎使用。
📄 摘要(原文)
We evaluate large language models (LLMs) for automatic personality prediction from text under the binary Five Factor Model (BIG5). Five models -- including GPT-4 and lightweight open-source alternatives -- are tested across three heterogeneous datasets (Essays, MyPersonality, Pandora) and two prompting strategies (minimal vs. enriched with linguistic and psychological cues). Enriched prompts reduce invalid outputs and improve class balance, but also introduce a systematic bias toward predicting trait presence. Performance varies substantially: Openness and Agreeableness are relatively easier to detect, while Extraversion and Neuroticism remain challenging. Although open-source models sometimes approach GPT-4 and prior benchmarks, no configuration yields consistently reliable predictions in zero-shot binary settings. Moreover, aggregate metrics such as accuracy and macro-F1 mask significant asymmetries, with per-class recall offering clearer diagnostic value. These findings show that current out-of-the-box LLMs are not yet suitable for APPT, and that careful coordination of prompt design, trait framing, and evaluation metrics is essential for interpretable results.