Visual Puns from Idioms: An Iterative LLM-T2IM-MLLM Framework
作者: Kelaiti Xiao, Liang Yang, Dongyu Zhang, Paerhati Tulajiang, Hongfei Lin
分类: cs.CL, cs.CV
发布日期: 2025-11-28
备注: Submitted to ICASSP 2026 (under review)
💡 一句话要点
提出基于迭代LLM-T2IM-MLLM框架的成语视觉双关语自动生成与评估方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉双关语 成语理解 图像生成 多模态学习 LLM T2IM MLLM
📋 核心要点
- 现有方法难以自动生成同时体现成语字面和比喻含义的视觉双关图像。
- 提出迭代框架,利用LLM生成提示,T2IM合成图像,MLLM识别成语,循环优化。
- 实验表明MLLM选择是关键,GPT最佳,Gemma与部分闭源模型竞争,Claude擅长提示生成。
📝 摘要(中文)
本文研究了基于成语的视觉双关语——即图像同时对齐成语的字面意义和比喻意义。为此,我们提出了一个迭代框架,该框架协调大型语言模型(LLM)、文本到图像模型(T2IM)和多模态LLM(MLLM),以实现自动生成和评估。给定一个成语,系统迭代地执行以下步骤:(i)生成详细的视觉提示,(ii)合成图像,(iii)从图像中推断成语,以及(iv)细化提示,直到识别成功或达到步骤限制。我们使用1000个成语作为输入,合成了相应的视觉双关语图像数据集,并配对提示,从而能够对生成和理解进行基准测试。对10个LLM、10个MLLM和一个T2IM(Qwen-Image)的实验表明,MLLM的选择是主要的性能驱动因素:GPT实现了最高的准确率,Gemini紧随其后,而最好的开源MLLM(Gemma)与一些闭源模型具有竞争力。在LLM方面,Claude在提示生成方面表现出最强的平均性能。
🔬 方法详解
问题定义:论文旨在解决自动生成成语视觉双关语的问题。现有的图像生成方法通常难以捕捉成语中蕴含的字面和比喻双重含义,导致生成的图像无法有效表达成语的精髓。因此,如何让AI理解成语的深层含义并将其转化为具有视觉冲击力的图像是一个挑战。
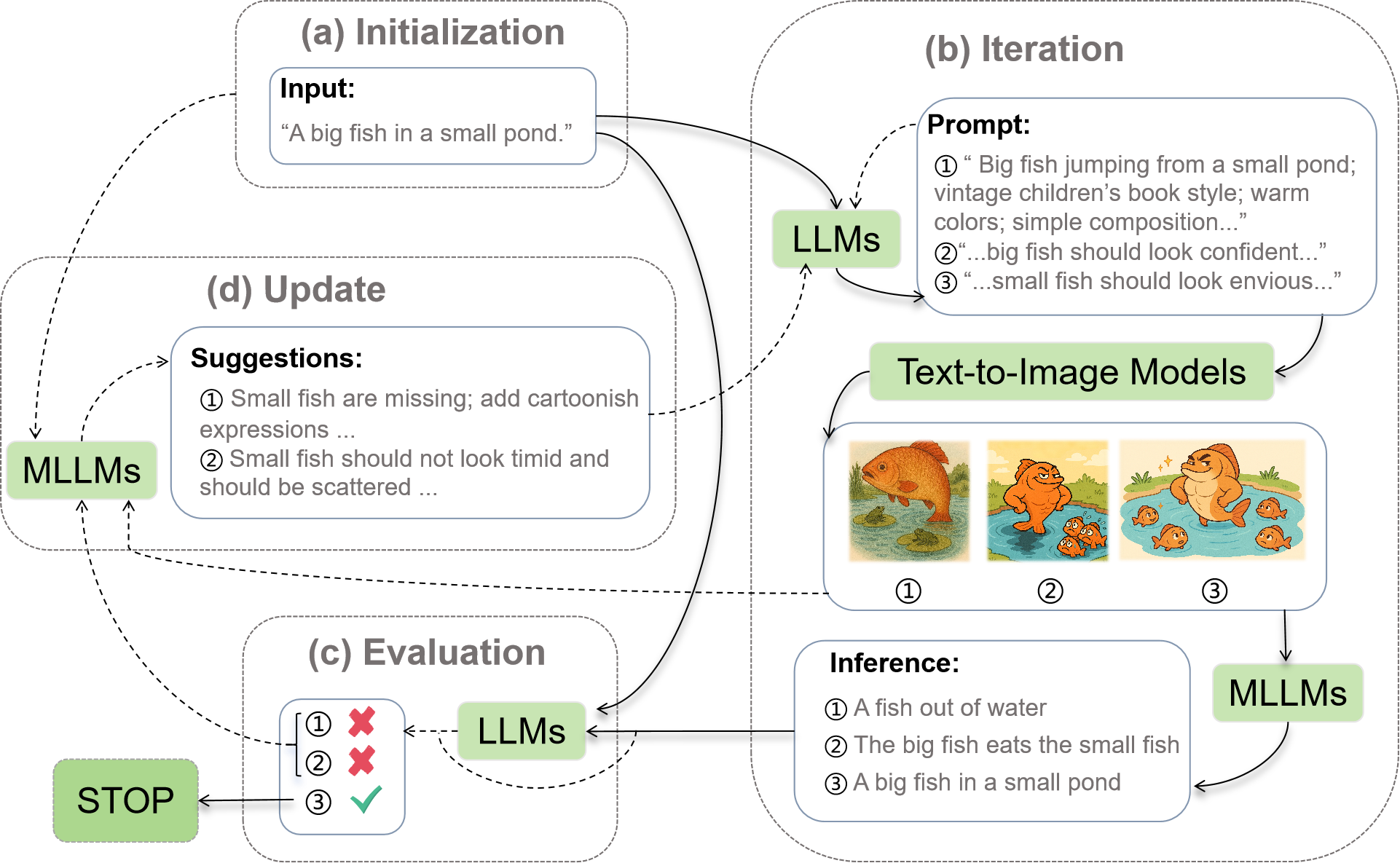
核心思路:论文的核心思路是利用迭代优化的方式,通过LLM生成图像提示,T2IM生成图像,再由MLLM进行识别,根据识别结果反馈并优化提示,从而逐步生成符合要求的视觉双关语图像。这种迭代的方式能够让模型逐步理解成语的含义,并生成更符合要求的图像。
技术框架:整体框架包含三个主要模块:LLM(用于生成视觉提示)、T2IM(用于根据提示生成图像)和MLLM(用于从图像中推断成语)。流程如下:1. 给定一个成语,LLM生成初始视觉提示。2. T2IM根据提示合成图像。3. MLLM分析图像并尝试推断成语。4. 如果MLLM成功识别成语,则生成结束;否则,LLM根据MLLM的反馈改进提示,重复步骤2-4,直到达到迭代次数上限。
关键创新:该方法最重要的创新点在于提出了一个迭代的LLM-T2IM-MLLM框架,通过循环优化提示和图像,使得生成的图像能够更好地表达成语的字面和比喻双重含义。与传统的单次生成方法相比,该方法能够更有效地利用LLM和MLLM的知识,逐步提升图像的质量和准确性。
关键设计:迭代次数上限是一个关键参数,控制着生成过程的计算成本和图像质量。此外,LLM生成的提示的详细程度和准确性,以及MLLM的识别能力,都会直接影响最终的生成效果。论文中使用了Qwen-Image作为T2IM,并对比了多个LLM(如Claude)和MLLM(如GPT, Gemini, Gemma)的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MLLM的选择对性能影响最大,GPT模型表现最佳,Gemini紧随其后,开源模型Gemma也展现出竞争力。在LLM方面,Claude在提示生成方面表现出最强的平均性能。该研究为视觉双关语的自动生成提供了一个有效的解决方案,并为多模态学习和生成提供了新的思路。
🎯 应用场景
该研究成果可应用于教育领域,辅助成语学习和理解,提高学习趣味性。同时,也可应用于创意设计、广告营销等领域,生成具有独特视觉效果的图像内容,提升内容吸引力。此外,该框架为多模态内容生成提供了一种新的思路,具有潜在的商业价值。
📄 摘要(原文)
We study idiom-based visual puns--images that align an idiom's literal and figurative meanings--and present an iterative framework that coordinates a large language model (LLM), a text-to-image model (T2IM), and a multimodal LLM (MLLM) for automatic generation and evaluation. Given an idiom, the system iteratively (i) generates detailed visual prompts, (ii) synthesizes an image, (iii) infers the idiom from the image, and (iv) refines the prompt until recognition succeeds or a step limit is reached. Using 1,000 idioms as inputs, we synthesize a corresponding dataset of visual pun images with paired prompts, enabling benchmarking of both generation and understanding. Experiments across 10 LLMs, 10 MLLMs, and one T2IM (Qwen-Image) show that MLLM choice is the primary performance driver: GPT achieves the highest accuracies, Gemini follows, and the best open-source MLLM (Gemma) is competitive with some closed models. On the LLM side, Claude attains the strongest average performance for prompt generation.