Decoding inner speech with an end-to-end brain-to-text neural interface
作者: Yizi Zhang, Linyang He, Chaofei Fan, Tingkai Liu, Han Yu, Trung Le, Jingyuan Li, Scott Linderman, Lea Duncker, Francis R Willett, Nima Mesgarani, Liam Paninski
分类: cs.CL, cs.AI
发布日期: 2025-11-21 (更新: 2025-12-05)
💡 一句话要点
提出端到端脑-文本神经接口BIT,显著提升解码内心语音的准确率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脑机接口 内心语音解码 端到端学习 神经编码器 大语言模型 对比学习 跨模态对齐
📋 核心要点
- 传统语音BCI系统采用级联框架,分阶段解码音素和组装句子,无法联合优化所有阶段。
- 论文提出端到端Brain-to-Text (BIT)框架,利用预训练编码器和音频LLM直接将神经活动转化为文本。
- 实验结果表明,BIT显著降低了词错误率,并在尝试语音和想象语音之间实现了跨任务泛化。
📝 摘要(中文)
本文提出了一种端到端的脑-文本(Brain-to-Text, BIT)神经接口,旨在通过将神经活动直接翻译成文本,为瘫痪患者恢复交流能力。该方法使用单一可微神经网络,避免了传统级联框架中各阶段的独立优化。核心在于一个跨任务、跨物种的预训练神经编码器,其表征能够迁移到尝试语音和想象语音。在与n-gram语言模型结合的级联设置中,预训练编码器在Brain-to-Text '24和'25基准测试上取得了新的SOTA。通过与音频大语言模型(LLM)进行端到端集成,并采用对比学习进行跨模态对齐,BIT将先前端到端方法的词错误率(WER)从24.69%降低到10.22%。研究表明,小规模音频LLM能够显著改善端到端解码。此外,BIT能够对齐尝试语音和想象语音的嵌入,实现跨任务泛化。该方法促进了大型、多样化神经数据集的集成,为支持无缝、可微优化的端到端解码框架铺平了道路。
🔬 方法详解
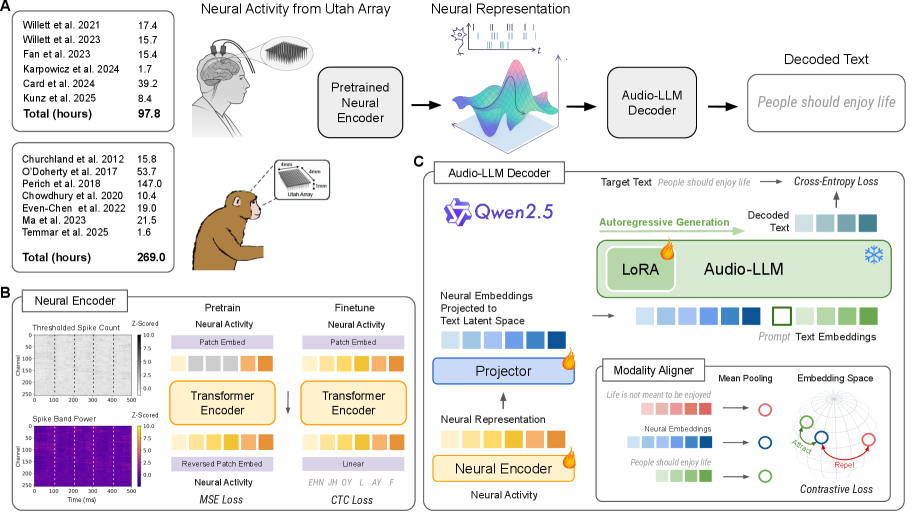
问题定义:现有语音脑机接口(BCI)系统通常采用级联框架,即先解码神经活动为音素,再使用n-gram语言模型将音素组合成句子。这种方法的痛点在于各个阶段是独立优化的,无法实现全局最优,且容易产生误差累积。此外,现有方法在处理想象语音时,性能往往不如处理尝试语音。
核心思路:本文的核心思路是构建一个端到端的神经接口,直接将神经活动映射到文本,避免中间环节的误差传递。通过预训练一个跨任务、跨物种的神经编码器,并结合音频大语言模型(LLM),实现神经活动到文本的直接翻译。对比学习用于跨模态对齐,进一步提升性能。
技术框架:BIT框架主要包含以下几个模块:1) 神经编码器:负责将神经活动转化为高维表征。该编码器通过跨任务、跨物种的预训练获得。2) 音频LLM:负责将神经编码器的输出转化为文本。3) 对比学习模块:用于对齐神经活动和音频表征,提升跨模态的泛化能力。整个框架采用端到端的方式进行训练,可以直接优化神经活动到文本的映射。
关键创新:最重要的技术创新点在于端到端的训练方式和跨任务、跨物种的预训练编码器。端到端训练避免了传统级联框架的误差累积,实现了全局优化。预训练编码器能够有效利用大规模的神经数据,提升模型的泛化能力。此外,利用音频LLM作为解码器也是一个创新点,能够有效利用LLM的语言建模能力。
关键设计:论文采用了对比学习损失函数来对齐神经活动和音频表征。具体来说,对于每一段神经活动,模型会生成一个文本序列,然后将该文本序列转化为音频表征。对比学习的目标是使得真实的神经活动表征和生成的音频表征尽可能接近。此外,论文还探索了不同规模的音频LLM对解码性能的影响。网络结构细节和具体的参数设置在论文中有详细描述。
🖼️ 关键图片

📊 实验亮点
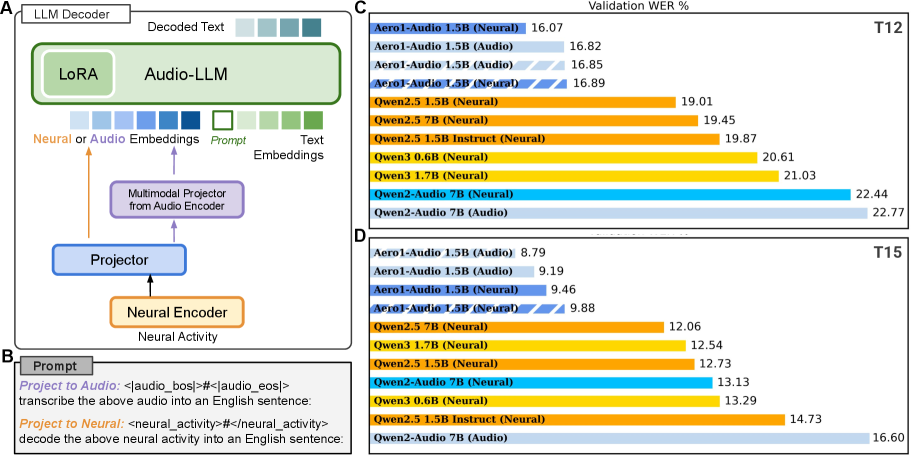
实验结果表明,BIT框架在Brain-to-Text '24和'25基准测试上取得了新的SOTA。与之前的端到端方法相比,BIT将词错误率(WER)从24.69%降低到10.22%,取得了显著的性能提升。此外,研究还发现,小规模音频LLM能够显著改善端到端解码的性能。
🎯 应用场景
该研究成果可应用于开发更高效、更自然的语音脑机接口系统,帮助瘫痪患者恢复交流能力。通过对尝试语音和想象语音的统一建模,该技术有望应用于辅助运动想象训练、精神疾病诊断等领域。未来,结合更强大的LLM和更精细的神经数据,有望实现更高质量的脑-文本转换。
📄 摘要(原文)
Speech brain-computer interfaces (BCIs) aim to restore communication for people with paralysis by translating neural activity into text. Most systems use cascaded frameworks that decode phonemes before assembling sentences with an n-gram language model (LM), preventing joint optimization of all stages simultaneously. Here, we introduce an end-to-end Brain-to-Text (BIT) framework that translates neural activity into coherent sentences using a single differentiable neural network. Central to our approach is a cross-task, cross-species pretrained neural encoder, whose representations transfer to both attempted and imagined speech. In a cascaded setting with an n-gram LM, the pretrained encoder establishes a new state-of-the-art (SOTA) on the Brain-to-Text '24 and '25 benchmarks. Integrated end-to-end with audio large language models (LLMs) and trained with contrastive learning for cross-modal alignment, BIT reduces the word error rate (WER) of the prior end-to-end method from 24.69% to 10.22%. Notably, we find that small-scale audio LLMs markedly improve end-to-end decoding. Beyond record-setting performance, BIT aligns attempted and imagined speech embeddings to enable cross-task generalization. Altogether, our approach advances the integration of large, diverse neural datasets, paving the way for an end-to-end decoding framework that supports seamless, differentiable optimization.