R2Q: Towards Robust 2-Bit Large Language Models via Residual Refinement Quantization
作者: Jiayi Chen, Jieqi Shi, Jing Huo, Chen Wu
分类: cs.CL, cs.AI
发布日期: 2025-11-21
💡 一句话要点
提出R2Q:通过残差细化量化实现鲁棒的2比特大语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 低比特量化 模型压缩 残差量化 量化感知训练
📋 核心要点
- 现有低比特量化方法在将大语言模型量化到2比特时,面临严重的精度下降问题,难以满足实际应用需求。
- R2Q通过将2比特量化分解为两个连续的1比特子量化,形成自适应量化格,从而更精细地逼近原始权重。
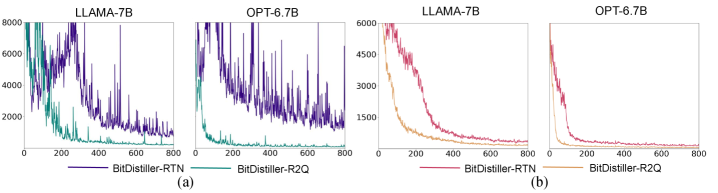
- 实验表明,R2Q在Llama、OPT和Qwen等模型上,相比现有2比特量化方法,在多种任务上均取得了显著的性能提升。
📝 摘要(中文)
大语言模型(LLMs)的快速发展带来了巨大的计算和内存需求,推动了低比特量化的应用。虽然8比特和4比特格式已经很普遍,但由于严重的精度下降,将量化扩展到2比特仍然具有挑战性。为了解决这个问题,我们提出了残差细化量化(R2Q)——一种新颖的2比特量化框架,它将过程分解为两个连续的1比特子量化,形成一个自适应量化格。在涵盖问答、常识推理和语言建模等不同基准测试中,对Llama、OPT和Qwen进行的广泛评估表明,R2Q在细粒度和粗粒度设置中始终优于现有的2比特量化方法。通过残差学习机制细化量化,R2Q增强了性能,提高了训练稳定性,并加速了极端压缩下的收敛。此外,其模块化设计使其能够与现有的量化感知训练(QAT)框架无缝集成。
🔬 方法详解
问题定义:论文旨在解决将大语言模型量化到2比特时,由于信息损失严重导致的精度大幅下降问题。现有的2比特量化方法难以在保持模型性能的同时,实现极低的比特压缩率,限制了其在资源受限设备上的部署。
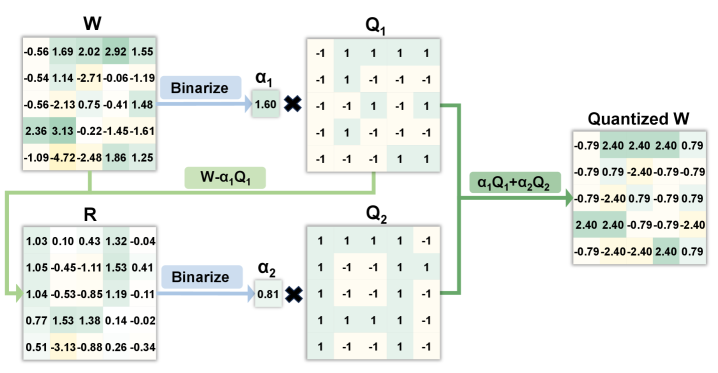
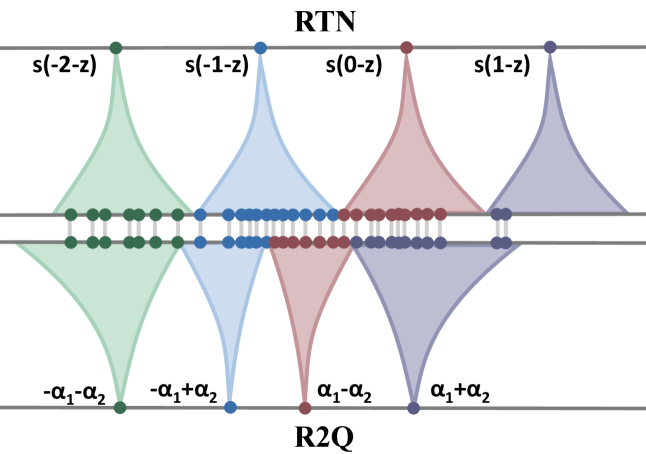
核心思路:R2Q的核心思路是将原本的2比特量化过程分解为两个连续的1比特子量化过程,通过残差学习的方式逐步逼近原始权重。这种分解形成了一种自适应的量化格,能够更灵活地适应不同权重的分布,从而减少量化误差。
技术框架:R2Q框架主要包含两个连续的1比特子量化模块。首先,对原始权重进行第一次1比特量化,得到量化后的权重和残差。然后,对残差进行第二次1比特量化。最终的2比特量化结果由两次1比特量化的结果组合而成。整个过程可以看作是在一个自适应的量化格上进行量化。
关键创新:R2Q的关键创新在于其残差细化量化的思想,通过两次1比特量化逐步逼近原始权重,有效缓解了2比特量化带来的信息损失。与传统的直接2比特量化方法相比,R2Q能够更精细地捕捉权重的分布特征,从而提高量化精度。
关键设计:R2Q的关键设计包括:1) 使用两个连续的1比特量化器;2) 利用残差学习机制,对第一次量化后的残差进行再次量化;3) 通过调整两次量化的比例因子,控制量化格的形状,使其更好地适应权重分布。具体的损失函数和网络结构细节未在摘要中提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
R2Q在Llama、OPT和Qwen等多个大型语言模型上进行了广泛的实验验证。实验结果表明,R2Q在问答、常识推理和语言建模等多个任务上,均显著优于现有的2比特量化方法。具体的性能提升数据未在摘要中给出,属于未知信息。
🎯 应用场景
R2Q具有广泛的应用前景,尤其是在资源受限的边缘设备上部署大型语言模型。通过将模型量化到2比特,可以显著降低模型的存储空间和计算复杂度,使其能够在移动设备、嵌入式系统等平台上运行。此外,R2Q还可以应用于模型压缩、模型加速等领域,提高模型的效率和性能。
📄 摘要(原文)
The rapid progress of Large Language Models (LLMs) has brought substantial computational and memory demands, spurring the adoption of low-bit quantization. While 8-bit and 4-bit formats have become prevalent, extending quantization to 2 bits remains challenging due to severe accuracy degradation. To address this, we propose Residual Refinement Quantization (R2Q)-a novel 2-bit quantization framework that decomposes the process into two sequential 1-bit sub-quantizations, forming an adaptive quantization lattice. Extensive evaluations on Llama, OPT, and Qwen across diverse benchmarks-covering question answering, commonsense reasoning, and language modeling-demonstrate that R2Q consistently outperforms existing 2-bit quantization methods in both fine-grained and coarse-grained settings. By refining quantization through a residual learning mechanism, R2Q enhances performance, improves training stability, and accelerates convergence under extreme compression. Furthermore, its modular design enables seamless integration with existing quantization-aware training (QAT) frameworks.