Asking LLMs to Verify First is Almost Free Lunch
作者: Shiguang Wu, Quanming Yao
分类: cs.CL, cs.AI
发布日期: 2025-11-21
💡 一句话要点
提出Verification-First策略,以低成本提升LLM的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 思维链 验证优先 反向推理
📋 核心要点
- 现有思维链(CoT)推理方法计算成本高昂,且依赖大量采样,限制了其在资源受限场景下的应用。
- Verification-First策略通过先验证候选答案再生成解决方案,触发反向推理,降低了逻辑错误的发生。
- 实验表明,Verification-First策略在多种任务和模型上均优于标准CoT,且Iter-VF策略超越了现有TTS方法。
📝 摘要(中文)
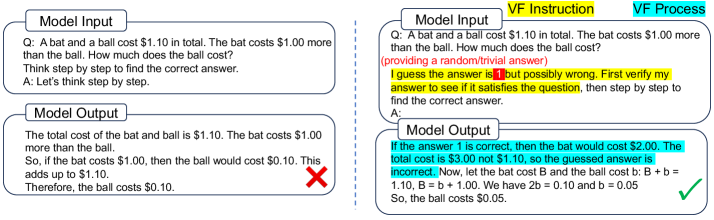
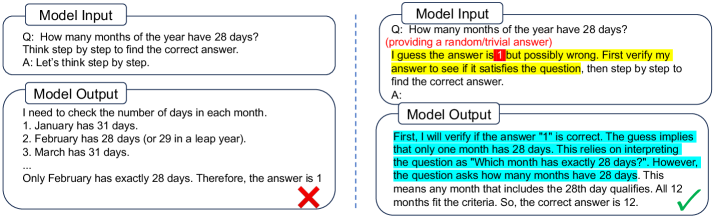
为了在不进行高成本训练或大量测试时采样的情况下增强大型语言模型(LLM)的推理能力,我们引入了Verification-First(VF)策略。该策略提示模型在生成解决方案之前,先验证一个提供的候选答案,即使这个答案是微不足道的或随机的。这种方法触发了一个“反向推理”过程,该过程在认知上更容易,并且与标准的正向思维链(CoT)互补,有效地调用了模型的批判性思维以减少逻辑错误。我们进一步将VF策略推广到Iter-VF,这是一种顺序测试时缩放(TTS)方法,它使用模型先前的答案迭代地循环验证-生成过程。在各种基准(从数学推理到编码和代理任务)和各种LLM(从开源1B到尖端商业LLM)上的大量实验证实,具有随机答案的VF始终优于标准CoT,且计算开销极小,而Iter-VF优于现有的TTS策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理能力不足的问题,尤其是在计算资源有限的情况下,如何以低成本的方式提升LLM的推理性能。现有方法,如思维链(CoT),通常需要大量的计算资源和采样,限制了其应用范围,并且容易产生逻辑错误。
核心思路:论文的核心思路是引入“验证优先”(Verification-First, VF)策略,即在生成答案之前,先让LLM验证一个候选答案(即使是随机的)。这种反向推理过程可以激发LLM的批判性思维,从而减少逻辑错误,提高推理的准确性。
技术框架:VF策略的核心流程是:首先,向LLM提供一个问题和一个候选答案;然后,提示LLM验证该候选答案的正确性;最后,基于验证结果,LLM生成最终的解决方案。Iter-VF策略则是在VF的基础上进行迭代,每次迭代都使用LLM前一次生成的答案作为新的候选答案,循环进行验证和生成,从而逐步优化答案。
关键创新:VF策略的关键创新在于改变了传统的推理方向,从正向的“问题->推理->答案”转变为反向的“问题+候选答案->验证->推理->答案”。这种反向推理能够更好地利用LLM的知识和推理能力,减少逻辑错误。Iter-VF则通过迭代的方式,进一步提升了推理的准确性和稳定性。
关键设计:VF策略的关键设计在于验证提示的设计,需要清晰地引导LLM进行验证推理。Iter-VF的关键设计在于迭代次数的选择,需要在计算成本和性能提升之间进行权衡。论文中并没有提及具体的参数设置、损失函数或网络结构等技术细节,因为该方法主要是一种prompting策略,而非模型结构的改变。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Verification-First策略在各种基准测试中均优于标准CoT方法,且计算开销极小。即使使用随机答案进行验证,VF策略也能显著提升LLM的推理性能。Iter-VF策略进一步超越了现有的TTS策略,在多个任务上取得了最佳性能。这些结果表明,Verification-First策略是一种有效的、低成本的LLM推理能力提升方法。
🎯 应用场景
该研究成果可广泛应用于需要LLM进行推理的各种场景,如数学问题求解、代码生成、智能代理等。尤其适用于资源受限的场景,例如移动设备或边缘计算环境。通过Verification-First策略,可以在不增加过多计算成本的情况下,显著提升LLM的推理能力,从而提高相关应用的性能和用户体验。
📄 摘要(原文)
To enhance the reasoning capabilities of Large Language Models (LLMs) without high costs of training, nor extensive test-time sampling, we introduce Verification-First (VF), a strategy that prompts models to verify a provided candidate answer, even a trivial or random one, before generating a solution. This approach triggers a "reverse reasoning" process that is cognitively easier and complementary to standard forward Chain-of-Thought (CoT), effectively invoking the model's critical thinking to reduce logical errors. We further generalize the VF strategy to Iter-VF, a sequential test-time scaling (TTS) method that iteratively cycles the verification-generation process using the model's previous answer. Extensive experiments across various benchmarks (from mathematical reasoning to coding and agentic tasks) and various LLMs (from open-source 1B to cutting-edge commercial ones) confirm that VF with random answer consistently outperforms standard CoT with minimal computational overhead, and Iter-VF outperforms existing TTS strategies.