RoSA: Enhancing Parameter-Efficient Fine-Tuning via RoPE-aware Selective Adaptation in Large Language Models
作者: Dayan Pan, Jingyuan Wang, Yilong Zhou, Jiawei Cheng, Pengyue Jia, Xiangyu Zhao
分类: cs.CL, cs.AI
发布日期: 2025-11-21
备注: Accepted by AAAI' 26
🔗 代码/项目: GITHUB
💡 一句话要点
RoSA:通过RoPE感知的选择性适配增强大语言模型的参数高效微调
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 大语言模型 旋转位置嵌入 选择性适配 注意力机制
📋 核心要点
- 现有参数高效微调方法忽略了模型组件的不同角色和层间重要性的差异,导致适配效率受限。
- RoSA通过RoPE感知的注意力增强模块选择性地增强注意力状态的低频分量,并使用动态层选择策略自适应地更新关键层。
- 实验结果表明,RoSA在常识和算术基准测试中,以相当的训练参数优于现有主流PEFT方法。
📝 摘要(中文)
针对大语言模型进行任务特定适配的微调至关重要,但计算成本仍然高昂。参数高效微调(PEFT)方法应运而生,但现有方法通常忽略了模型组件的不同角色以及各层之间重要性的异质性,从而限制了适配效率。受旋转位置嵌入(RoPE)在注意力状态的低频维度中诱导关键激活的观察启发,我们提出了RoPE感知的选择性适配(RoSA),这是一种新颖的PEFT框架,以更有针对性和有效的方式分配可训练参数。RoSA包含一个RoPE感知的注意力增强(RoAE)模块,该模块选择性地增强受RoPE影响的注意力状态的低频分量,以及一种动态层选择(DLS)策略,该策略基于LayerNorm梯度范数自适应地识别和更新最关键的层。通过结合维度方面的增强和层方面的适配,RoSA实现了更有针对性和高效的微调。在十五个常识和算术基准上的大量实验表明,在可比的训练参数下,RoSA优于现有的主流PEFT方法。代码已在https://github.com/Applied-Machine-Learning-Lab/RoSA上提供,以方便重现。
🔬 方法详解
问题定义:论文旨在解决大语言模型微调过程中计算资源消耗过大的问题,并提升参数高效微调(PEFT)方法的效率。现有PEFT方法的痛点在于,它们通常平等对待模型中的各个组件和层,忽略了它们在任务适应中的不同重要性,导致参数利用率不高。
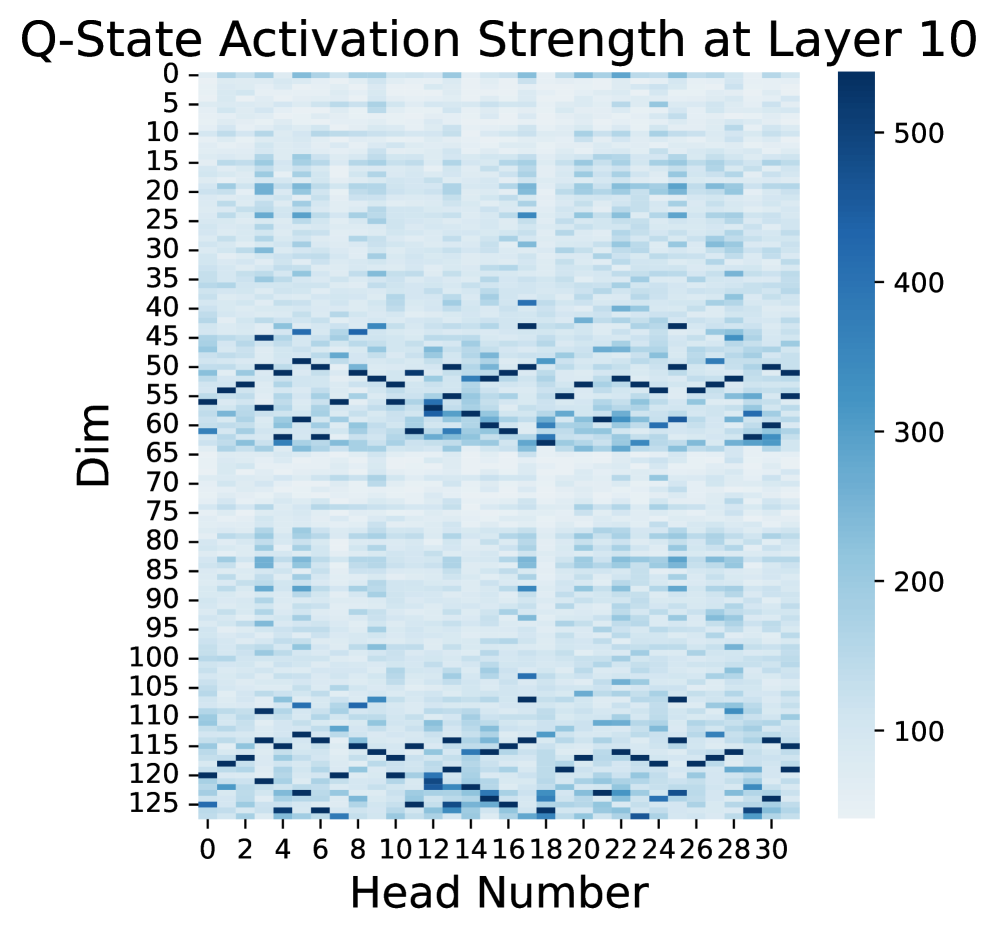
核心思路:论文的核心思路是根据模型组件和层的重要性进行选择性适配。具体来说,论文观察到旋转位置嵌入(RoPE)在注意力状态的低频维度中起着关键作用,因此提出增强这些低频分量。同时,论文还提出动态选择需要更新的层,从而实现更有效的参数分配。这样设计的目的是为了让模型将有限的参数集中在最关键的部分,从而提高微调效率。
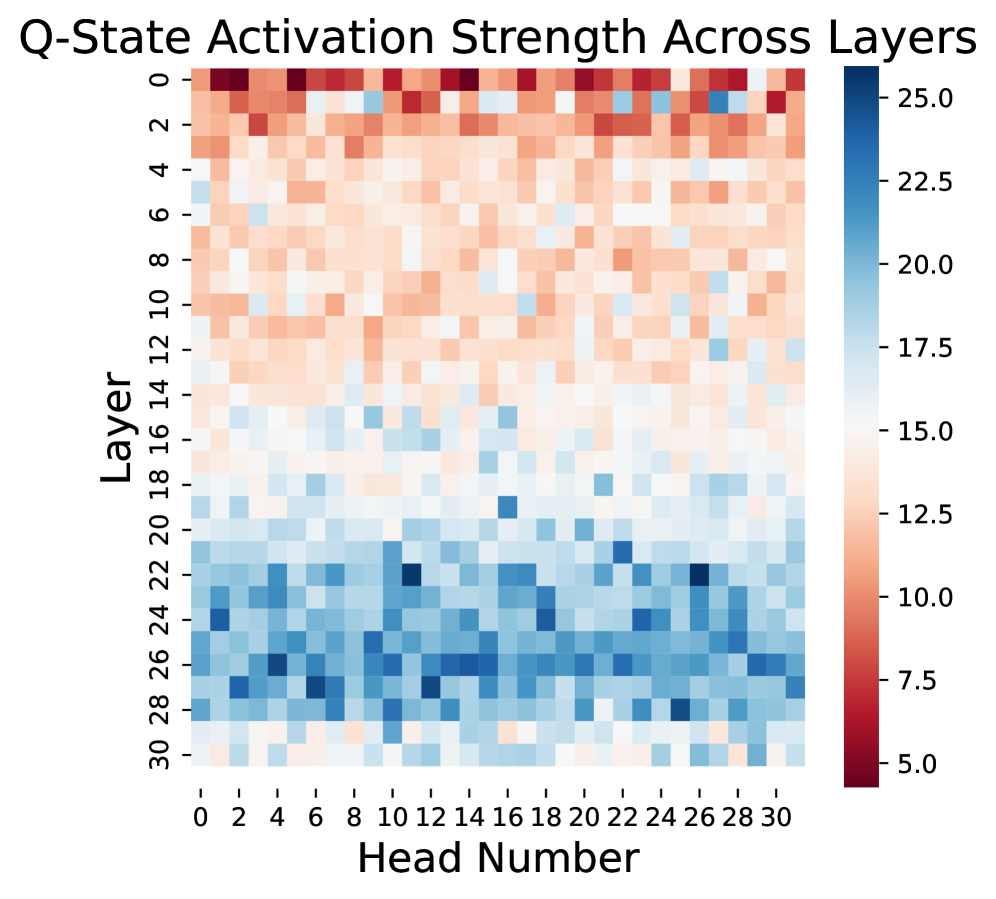
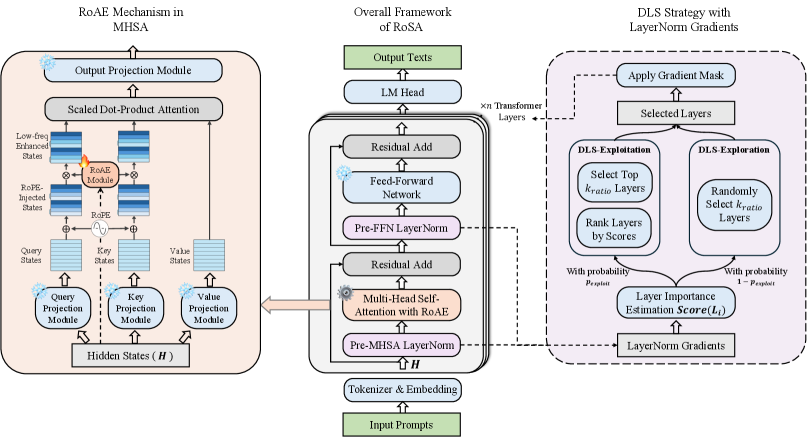
技术框架:RoSA框架主要包含两个模块:RoPE感知的注意力增强(RoAE)模块和动态层选择(DLS)策略。RoAE模块负责选择性地增强受RoPE影响的注意力状态的低频分量。DLS策略则基于LayerNorm梯度范数自适应地识别和更新最关键的层。这两个模块协同工作,实现维度和层两个层面的选择性适配。
关键创新:RoSA的关键创新在于其RoPE感知的选择性适配机制。与现有PEFT方法不同,RoSA不是平等地更新所有参数,而是有针对性地增强RoPE影响下的注意力状态的低频分量,并动态选择需要更新的层。这种选择性适配机制能够更有效地利用有限的参数,从而提高微调效率。
关键设计:RoAE模块的具体实现方式未知,但可以推测其可能使用某种滤波器或加权机制来增强低频分量。DLS策略的关键在于如何定义和计算层的“重要性”。论文中使用LayerNorm梯度范数作为衡量标准,这可能基于梯度范数越大,该层对损失函数的影响越大的假设。具体的层选择策略也未知,可能采用Top-K选择或者基于阈值的选择。
🖼️ 关键图片
📊 实验亮点
RoSA在十五个常识和算术基准测试中表现出色,证明了其有效性。实验结果表明,在可比的训练参数下,RoSA优于现有的主流PEFT方法,表明RoSA能够更有效地利用参数,实现更高效的微调。具体的性能提升幅度未知,但摘要中明确指出RoSA优于现有方法。
🎯 应用场景
RoSA方法可以广泛应用于各种需要对大语言模型进行微调的场景,例如自然语言处理、文本生成、机器翻译、对话系统等。该方法能够以更低的计算成本和更高的效率,将大语言模型适配到特定的任务和领域,从而降低了使用大语言模型的门槛,并加速了其在各个领域的应用。
📄 摘要(原文)
Fine-tuning large language models is essential for task-specific adaptation, yet it remains computationally prohibitive. Parameter-Efficient Fine-Tuning (PEFT) methods have emerged as a solution, but current approaches typically ignore the distinct roles of model components and the heterogeneous importance across layers, thereby limiting adaptation efficiency. Motivated by the observation that Rotary Position Embeddings (RoPE) induce critical activations in the low-frequency dimensions of attention states, we propose RoPE-aware Selective Adaptation (RoSA), a novel PEFT framework that allocates trainable parameters in a more targeted and effective manner. RoSA comprises a RoPE-aware Attention Enhancement (RoAE) module, which selectively enhances the low-frequency components of RoPE-influenced attention states, and a Dynamic Layer Selection (DLS) strategy that adaptively identifies and updates the most critical layers based on LayerNorm gradient norms. By combining dimension-wise enhancement with layer-wise adaptation, RoSA achieves more targeted and efficient fine-tuning. Extensive experiments on fifteen commonsense and arithmetic benchmarks demonstrate that RoSA outperforms existing mainstream PEFT methods under comparable trainable parameters. The code is available to ease reproducibility at https://github.com/Applied-Machine-Learning-Lab/RoSA.