HUMORCHAIN: Theory-Guided Multi-Stage Reasoning for Interpretable Multimodal Humor Generation
作者: Jiajun Zhang, Shijia Luo, Ruikang Zhang, Qi Su
分类: cs.CL, cs.AI
发布日期: 2025-11-21
💡 一句话要点
提出HUMORCHAIN,通过理论引导的多阶段推理生成可解释的多模态幽默内容
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态幽默生成 认知推理 幽默理论 视觉语义解析 语言模型 可解释性 结构化推理
📋 核心要点
- 现有方法在多模态幽默生成中缺乏对幽默的显式建模和理论基础,导致生成的内容缺乏真正的幽默感和认知深度。
- HUMORCHAIN通过整合视觉语义解析、幽默和心理学推理以及幽默评估判别器,构建了一个可解释和可控的认知推理链。
- 实验结果表明,HUMORCHAIN在人类幽默偏好、Elo/BT分数和语义多样性方面优于现有方法,验证了理论驱动的结构化推理的有效性。
📝 摘要(中文)
幽默既是一种创造性的人类活动,也是一种社会粘合机制,长期以来对人工智能生成提出了重大挑战。虽然产生幽默需要复杂的认知推理和社会理解,但幽默理论表明它遵循可学习的模式和结构,这使得生成模型在理论上可以隐式地学习它们。近年来,多模态幽默已成为一种流行的在线交流形式,尤其是在Z世代中,这突出了人工智能系统需要能够将视觉理解与幽默语言生成相结合。然而,现有的数据驱动方法缺乏对幽默的显式建模或理论基础,通常产生字面描述,无法捕捉其潜在的认知机制,导致生成的图像描述流畅但缺乏真正的幽默或认知深度。为了解决这个局限性,我们提出了HUMORCHAIN,一个理论引导的多阶段推理框架。它集成了视觉语义解析、基于幽默和心理学的推理,以及一个用于幽默评估的微调判别器,形成了一个可解释和可控的认知推理链。据我们所知,这是第一个将幽默理论中的认知结构显式嵌入到多模态幽默生成中的工作,从而实现了从视觉理解到幽默创造的结构化推理过程。在Meme-Image-No-Text、Oogiri-GO和OxfordTVG-HIC数据集上的实验表明,HUMORCHAIN在人类幽默偏好、Elo/BT分数和语义多样性方面优于最先进的基线,表明理论驱动的结构化推理使大型语言模型能够生成与人类感知对齐的幽默。
🔬 方法详解
问题定义:论文旨在解决多模态幽默生成问题,即如何让AI系统理解图像内容并生成具有幽默感的文本描述。现有方法主要依赖数据驱动,缺乏对幽默内在认知机制的建模,导致生成的内容往往是字面描述,缺乏真正的幽默感。
核心思路:论文的核心思路是将幽默理论中的认知结构显式地嵌入到多模态幽默生成过程中,通过结构化的推理过程,使模型能够更好地理解图像内容,并生成符合人类幽默感知的文本描述。这种方法强调从视觉理解到幽默创造的理论指导。
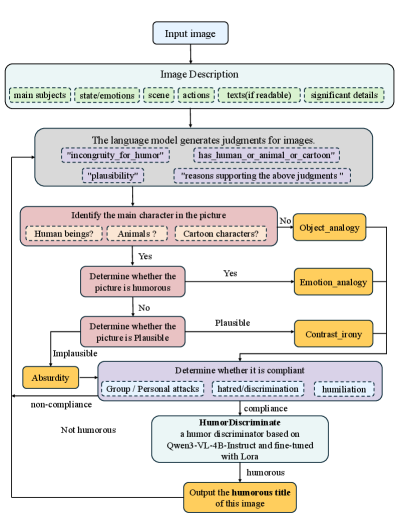
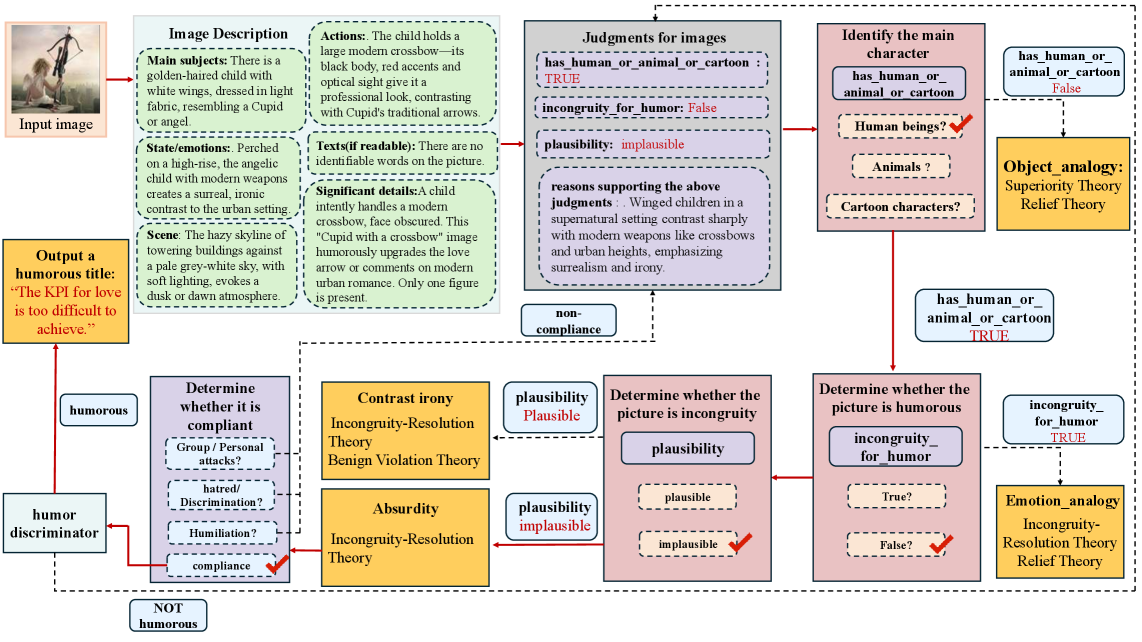
技术框架:HUMORCHAIN框架包含以下几个主要模块:1) 视觉语义解析:用于理解图像内容,提取关键语义信息。2) 幽默和心理学推理:基于幽默理论和心理学知识,对图像语义信息进行推理,挖掘潜在的幽默元素。3) 文本生成:将推理结果转化为具有幽默感的文本描述。4) 幽默评估判别器:用于评估生成文本的幽默程度,并对生成过程进行优化。
关键创新:该论文最重要的创新点在于首次将幽默理论中的认知结构显式地嵌入到多模态幽默生成过程中。与现有方法相比,HUMORCHAIN不再是简单地依赖数据驱动,而是通过理论指导的结构化推理,使模型能够更好地理解幽默的本质。
关键设计:论文中,视觉语义解析模块的具体实现方式未知。幽默和心理学推理模块的设计细节未知,但强调了基于幽默理论和心理学知识。幽默评估判别器通过微调实现,具体微调策略未知。损失函数的设计也未详细描述,但推测会包含幽默程度的评估指标。
🖼️ 关键图片
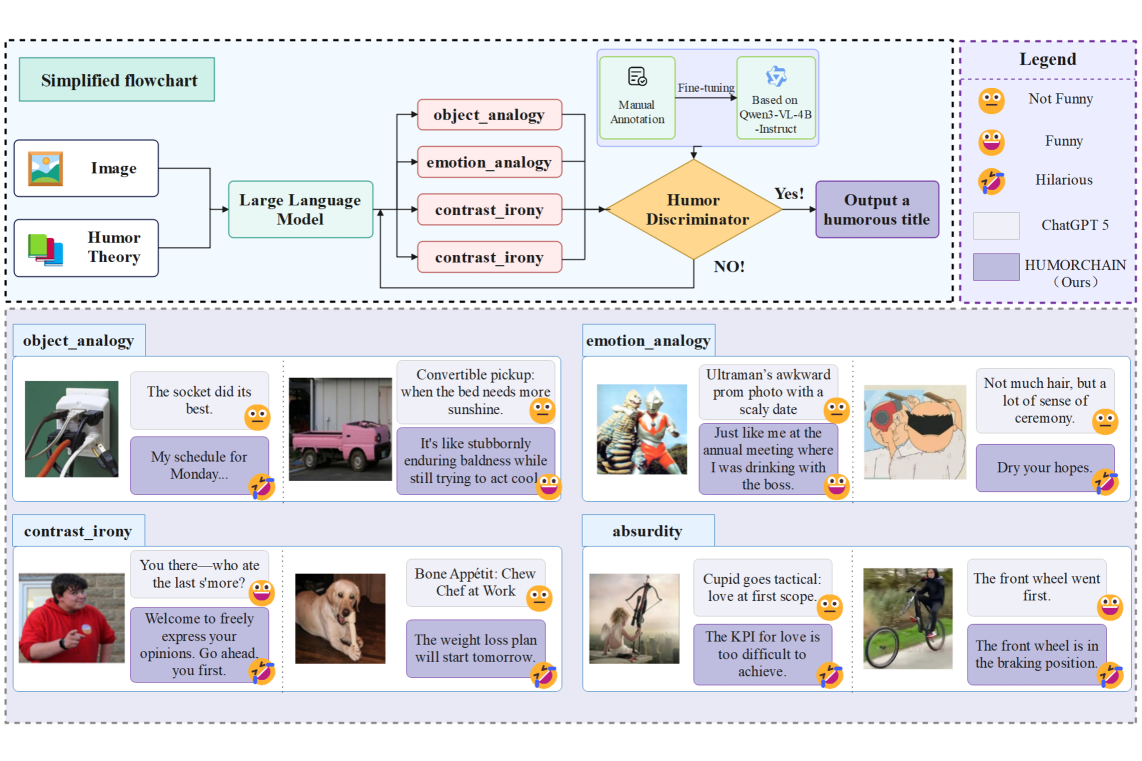
📊 实验亮点
实验结果表明,HUMORCHAIN在Meme-Image-No-Text、Oogiri-GO和OxfordTVG-HIC数据集上,在人类幽默偏好、Elo/BT分数和语义多样性方面均优于现有最先进的基线方法。这表明,通过理论驱动的结构化推理,大型语言模型能够生成更符合人类感知的幽默内容。
🎯 应用场景
该研究成果可应用于智能聊天机器人、社交媒体内容生成、广告创意设计等领域。通过生成更具幽默感和吸引力的内容,可以提升用户体验,增强人机交互的趣味性,并为内容创作者提供灵感。
📄 摘要(原文)
Humor, as both a creative human activity and a social binding mechanism, has long posed a major challenge for AI generation. Although producing humor requires complex cognitive reasoning and social understanding, theories of humor suggest that it follows learnable patterns and structures, making it theoretically possible for generative models to acquire them implicitly. In recent years, multimodal humor has become a prevalent form of online communication, especially among Gen Z, highlighting the need for AI systems capable of integrating visual understanding with humorous language generation. However, existing data-driven approaches lack explicit modeling or theoretical grounding of humor, often producing literal descriptions that fail to capture its underlying cognitive mechanisms, resulting in the generated image descriptions that are fluent but lack genuine humor or cognitive depth. To address this limitation, we propose HUMORCHAIN (HUmor-guided Multi-step Orchestrated Reasoning Chain for Image Captioning), a theory-guided multi-stage reasoning framework. It integrates visual semantic parsing, humor- and psychology-based reasoning, and a fine-tuned discriminator for humor evaluation, forming an interpretable and controllable cognitive reasoning chain. To the best of our knowledge, this is the first work to explicitly embed cognitive structures from humor theories into multimodal humor generation, enabling a structured reasoning process from visual understanding to humor creation. Experiments on Meme-Image-No-Text, Oogiri-GO, and OxfordTVG-HIC datasets show that HUMORCHAIN outperforms state-of-the-art baselines in human humor preference, Elo/BT scores, and semantic diversity, demonstrating that theory-driven structured reasoning enables large language models to generate humor aligned with human perception.