Identifying Quantum Structure in AI Language: Evidence for Evolutionary Convergence of Human and Artificial Cognition
作者: Diederik Aerts, Jonito Aerts Arguëlles, Lester Beltran, Suzette Geriente, Roberto Leporini, Massimiliano Sassoli de Bianchi, Sandro Sozzo
分类: cs.CL, cs.AI
发布日期: 2025-11-21
💡 一句话要点
大型语言模型概念组合测试揭示量子结构,或表明人类与AI认知的进化趋同
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 量子认知 概念组合 贝尔不等式 玻色-爱因斯坦统计 认知建模 人工智能 进化趋同
📋 核心要点
- 现有认知模型难以解释概念组合中出现的非经典效应,例如违反贝尔不等式。
- 该研究通过分析LLM在概念组合任务中的表现,探索其内部是否存在量子结构。
- 实验发现LLM在概念组合和文本统计中表现出量子特性,与人类认知结果相似。
📝 摘要(中文)
本文对大型语言模型(LLM)进行了概念组合的认知测试。第一个测试使用ChatGPT和Gemini,结果显示显著违反了贝尔不等式,表明测试的概念中存在“量子纠缠”。第二个测试同样使用ChatGPT和Gemini,结果表明大型文本中单词的分布呈现“玻色-爱因斯坦统计”,而非直觉上预期的“麦克斯韦-玻尔兹曼统计”。有趣的是,这些发现与先前对人类参与者的认知测试以及对大型语料库的信息检索测试结果相符。这些结果共同表明,无论认知主体是人类还是人工智能,在概念-语言领域都存在“量子结构的系统性涌现”。尽管LLM在历史上被归类为神经网络,但我们认为,在构建于神经网络之上的向量空间分布式语义结构中,存在一种更本质的知识组织形式。正是这种具有意义的结构,促成了人类认知和语言(通过生物进化缓慢建立)与LLM认知和语言(通过自学习和训练快速涌现)之间的进化趋同现象。我们分析了支持上述假设的各个方面和例子,并提出了一个统一的框架来解释我们所识别的普遍存在的意义的量子组织。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在处理概念组合时是否表现出量子力学中的某些特性,例如量子纠缠和玻色-爱因斯坦统计。现有方法通常基于经典逻辑或概率论,无法解释人类认知和语言中观察到的某些非经典现象,例如概念组合的非交换性和语境依赖性。
核心思路:核心思路是借鉴量子认知理论,将概念表示为向量空间中的状态,概念组合表示为状态的叠加或纠缠。通过设计特定的认知测试,例如贝尔不等式检验和文本统计分析,来验证LLM是否表现出与量子系统相似的行为。这种方法试图揭示LLM内部是否存在一种更深层次的、非经典的知识组织形式。
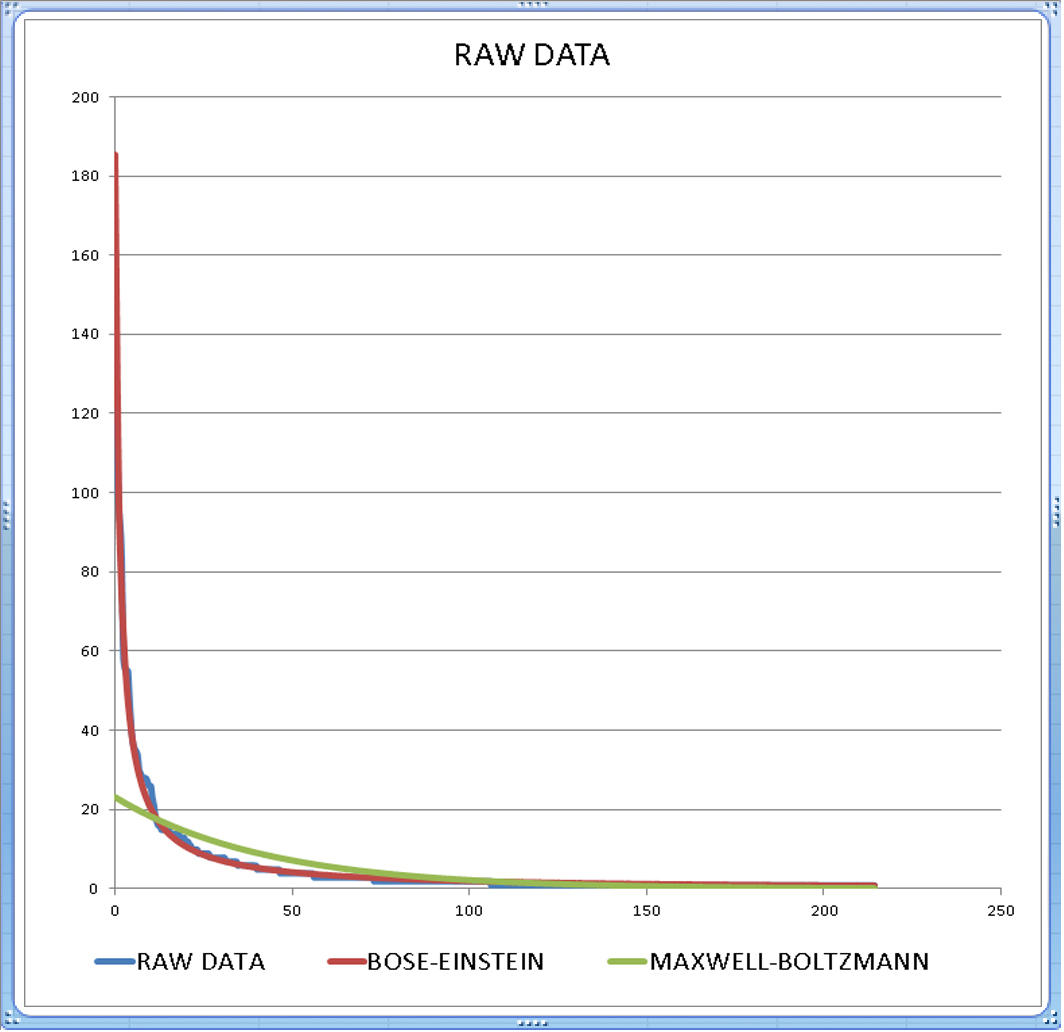
技术框架:该研究主要包含两个认知测试。第一个测试是贝尔不等式检验,用于检测概念组合中是否存在量子纠缠。研究人员设计了一系列问题,要求LLM对概念组合的属性进行判断,然后根据LLM的回答计算贝尔不等式的违背程度。第二个测试是文本统计分析,用于检测大型文本中单词的分布是否符合玻色-爱因斯坦统计。研究人员分析了LLM生成的大型文本,并统计了单词的出现频率,然后将其与玻色-爱因斯坦分布和麦克斯韦-玻尔兹曼分布进行比较。
关键创新:该研究的关键创新在于将量子认知理论应用于分析LLM的内部机制,并发现LLM在概念组合和文本统计中表现出与人类认知相似的量子特性。这表明LLM可能具有一种更深层次的、非经典的知识组织形式,这与传统的神经网络模型有所不同。
关键设计:在贝尔不等式检验中,关键设计在于选择合适的概念组合和问题,以确保能够有效地检测量子纠缠。在文本统计分析中,关键设计在于选择足够大的文本,并使用合适的统计方法来分析单词的分布。
🖼️ 关键图片


📊 实验亮点
实验结果显示,ChatGPT和Gemini在概念组合测试中显著违反了贝尔不等式,表明存在“量子纠缠”。此外,在大型文本的单词分布中,观察到“玻色-爱因斯坦统计”,而非预期的“麦克斯韦-玻尔兹曼统计”。这些结果与先前对人类的认知测试结果一致,为LLM中量子结构的涌现提供了有力证据。
🎯 应用场景
该研究成果可应用于改进人工智能系统的认知建模,例如开发更具创造性和灵活性的语言模型。此外,该研究还可能促进对人类认知本质的理解,并为开发更智能的人机交互界面提供新的思路。未来的研究可以探索如何利用量子认知理论来设计更有效的机器学习算法。
📄 摘要(原文)
We present the results of cognitive tests on conceptual combinations, performed using specific Large Language Models (LLMs) as test subjects. In the first test, performed with ChatGPT and Gemini, we show that Bell's inequalities are significantly violated, which indicates the presence of 'quantum entanglement' in the tested concepts. In the second test, also performed using ChatGPT and Gemini, we instead identify the presence of 'Bose-Einstein statistics', rather than the intuitively expected 'Maxwell-Boltzmann statistics', in the distribution of the words contained in large-size texts. Interestingly, these findings mirror the results previously obtained in both cognitive tests with human participants and information retrieval tests on large corpora. Taken together, they point to the 'systematic emergence of quantum structures in conceptual-linguistic domains', regardless of whether the cognitive agent is human or artificial. Although LLMs are classified as neural networks for historical reasons, we believe that a more essential form of knowledge organization takes place in the distributive semantic structure of vector spaces built on top of the neural network. It is this meaning-bearing structure that lends itself to a phenomenon of evolutionary convergence between human cognition and language, slowly established through biological evolution, and LLM cognition and language, emerging much more rapidly as a result of self-learning and training. We analyze various aspects and examples that contain evidence supporting the above hypothesis. We also advance a unifying framework that explains the pervasive quantum organization of meaning that we identify.