PoETa v2: Toward More Robust Evaluation of Large Language Models in Portuguese
作者: Thales Sales Almeida, Ramon Pires, Hugo Abonizio, Rodrigo Nogueira, Hélio Pedrini
分类: cs.CL
发布日期: 2025-11-21 (更新: 2025-11-26)
🔗 代码/项目: GITHUB
💡 一句话要点
PoETa v2:构建葡萄牙语LLM评测基准,促进更鲁棒的模型评估
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 葡萄牙语 评估基准 自然语言处理 语言适应
📋 核心要点
- 现有LLM在不同语言文化背景下表现差异大,缺乏针对葡萄牙语的系统性评测。
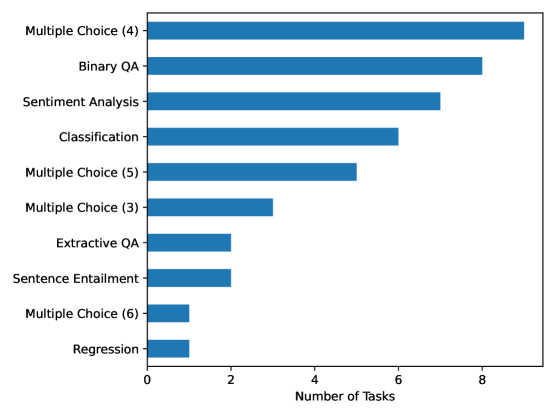
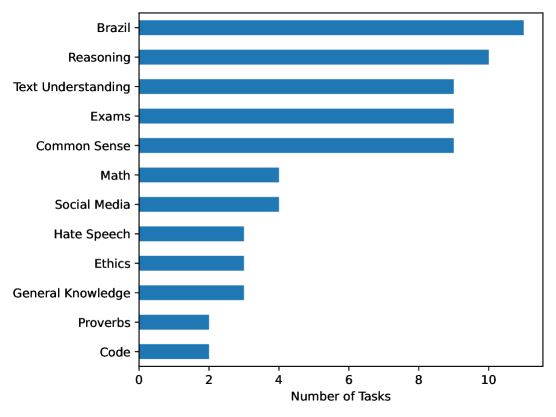
- 论文构建了PoETa v2基准,包含40多个葡萄牙语任务,用于全面评估LLM的性能。
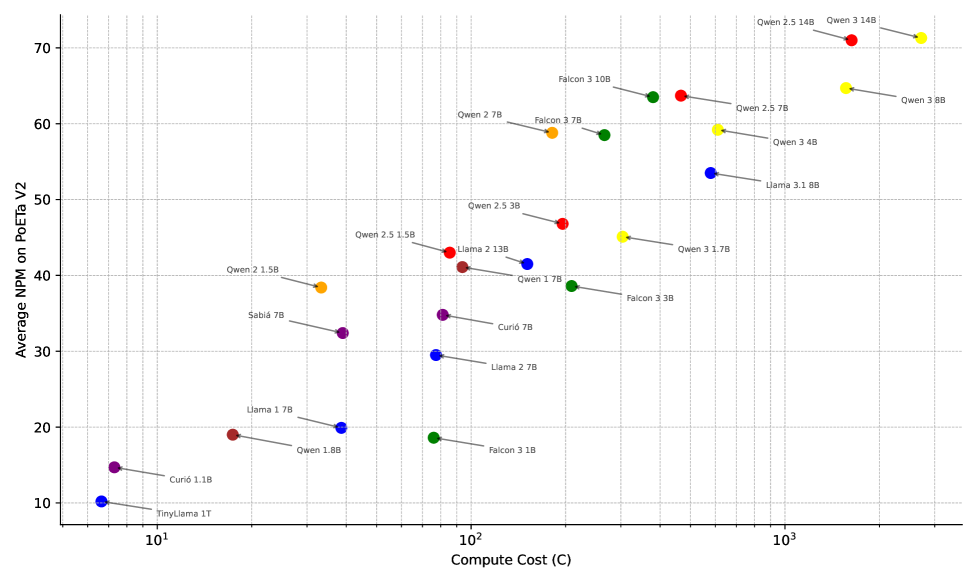
- 实验评估了20多个模型,分析了计算投入和语言适应对葡萄牙语性能的影响,并与英语任务对比。
📝 摘要(中文)
大型语言模型(LLMs)在不同语言和文化背景下的性能表现出显著差异,因此需要对不同语言进行系统评估。本文提出了迄今为止对葡萄牙语LLM最广泛的评估。利用新推出的PoETa v2基准——一个包含40多个葡萄牙语任务的综合套件——我们评估了20多个模型,涵盖了广泛的训练规模和计算资源。我们的研究揭示了计算投入和特定语言的适应如何影响葡萄牙语的性能,同时分析了与英语同等任务相比的性能差距。通过这个基准和分析,PoETa v2为未来葡萄牙语语言建模和评估的研究奠定了基础。该基准可在https://github.com/PoETaV2/PoETaV2获取。
🔬 方法详解
问题定义:现有的大型语言模型在不同语言环境下的表现存在显著差异,尤其是在资源相对匮乏的语言(如葡萄牙语)中,缺乏一个全面、系统的评估基准来衡量模型的性能。现有的方法通常侧重于英语等高资源语言,无法准确反映模型在葡萄牙语环境下的真实能力,这阻碍了针对葡萄牙语的LLM研究和发展。
核心思路:论文的核心思路是构建一个高质量、多样化的葡萄牙语评测基准PoETa v2,该基准包含多个任务,覆盖不同的语言理解和生成能力。通过在PoETa v2上对各种规模和类型的LLM进行评估,可以深入了解模型在葡萄牙语上的性能瓶颈,并为未来的模型优化提供指导。
技术框架:PoETa v2基准包含超过40个葡萄牙语任务,这些任务涵盖了广泛的自然语言处理领域,例如文本分类、问答、文本生成等。研究人员使用这些任务来评估20多个不同的LLM,这些模型在训练规模和计算资源方面各不相同。评估过程包括运行模型在各个任务上,并使用相应的评估指标来衡量模型的性能。
关键创新:PoETa v2的主要创新在于其作为迄今为止最全面的葡萄牙语LLM评估基准。它不仅包含了大量的任务,而且涵盖了广泛的语言现象和应用场景,能够更准确地反映模型在葡萄牙语环境下的真实能力。此外,该研究还对不同模型在葡萄牙语和英语任务上的性能进行了对比分析,揭示了语言特定适应的重要性。
关键设计:PoETa v2基准的任务选择和数据构建是关键设计。任务的选择需要覆盖葡萄牙语的各种语言现象和应用场景,例如语法、语义、推理等。数据的构建需要保证质量和多样性,避免出现偏差和噪声。此外,评估指标的选择也至关重要,需要选择能够准确反映模型性能的指标,例如准确率、F1值、BLEU等。
🖼️ 关键图片
📊 实验亮点
PoETa v2基准评估了20多个LLM在40多个葡萄牙语任务上的性能,揭示了计算投入和语言特定适应对模型性能的影响。研究发现,在葡萄牙语任务上,模型的性能与计算资源投入呈正相关,但语言特定适应能够显著提升模型性能。此外,研究还对比了模型在葡萄牙语和英语任务上的性能差异,为未来的模型优化提供了指导。
🎯 应用场景
该研究成果可应用于提升葡萄牙语自然语言处理模型的性能,例如机器翻译、文本摘要、情感分析等。PoETa v2基准可以帮助研究人员更好地了解LLM在葡萄牙语上的优势和不足,从而开发出更适合葡萄牙语环境的模型。此外,该基准还可以促进葡萄牙语自然语言处理领域的研究和发展,推动相关技术的应用。
📄 摘要(原文)
Large Language Models (LLMs) exhibit significant variations in performance across linguistic and cultural contexts, underscoring the need for systematic evaluation in diverse languages. In this work, we present the most extensive evaluation of LLMs for the Portuguese language to date. Leveraging our newly introduced PoETa v2 benchmark -- a comprehensive suite of over 40 tasks in Portuguese -- we assess more than 20 models covering a broad spectrum of training scales and computational resources. Our study reveals how computational investment and language-specific adaptation impact performance in Portuguese, while also analyzing performance gaps in comparison to equivalent tasks in English. Through this benchmark and analysis, PoETa v2 lays the groundwork for future research on Portuguese language modeling and evaluation. The benchmark is available at https://github.com/PoETaV2/PoETaV2.