PARROT: Persuasion and Agreement Robustness Rating of Output Truth -- A Sycophancy Robustness Benchmark for LLMs
作者: Yusuf Çelebi, Özay Ezerceli, Mahmoud El Hussieni
分类: cs.CL, cs.AI, cs.CE, cs.LG
发布日期: 2025-11-21 (更新: 2025-12-01)
💡 一句话要点
PARROT:提出一种评估LLM在权威诱导下输出真值一致性的基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 鲁棒性评估 逢迎现象 社会压力 权威诱导 基准测试 认知崩溃
📋 核心要点
- 现有LLM在社会压力下容易产生逢迎现象,即过度顺从权威或迎合观点,导致输出结果的准确性降低。
- PARROT框架通过比较中性问题和权威性错误问题,量化模型在社会压力下的准确性损失和置信度变化,并对失败模式进行分类。
- 实验结果表明,不同模型在面对社会压力时表现出显著差异,先进模型表现出较强的鲁棒性,而较旧/较小的模型则容易出现认知崩溃。
📝 摘要(中文)
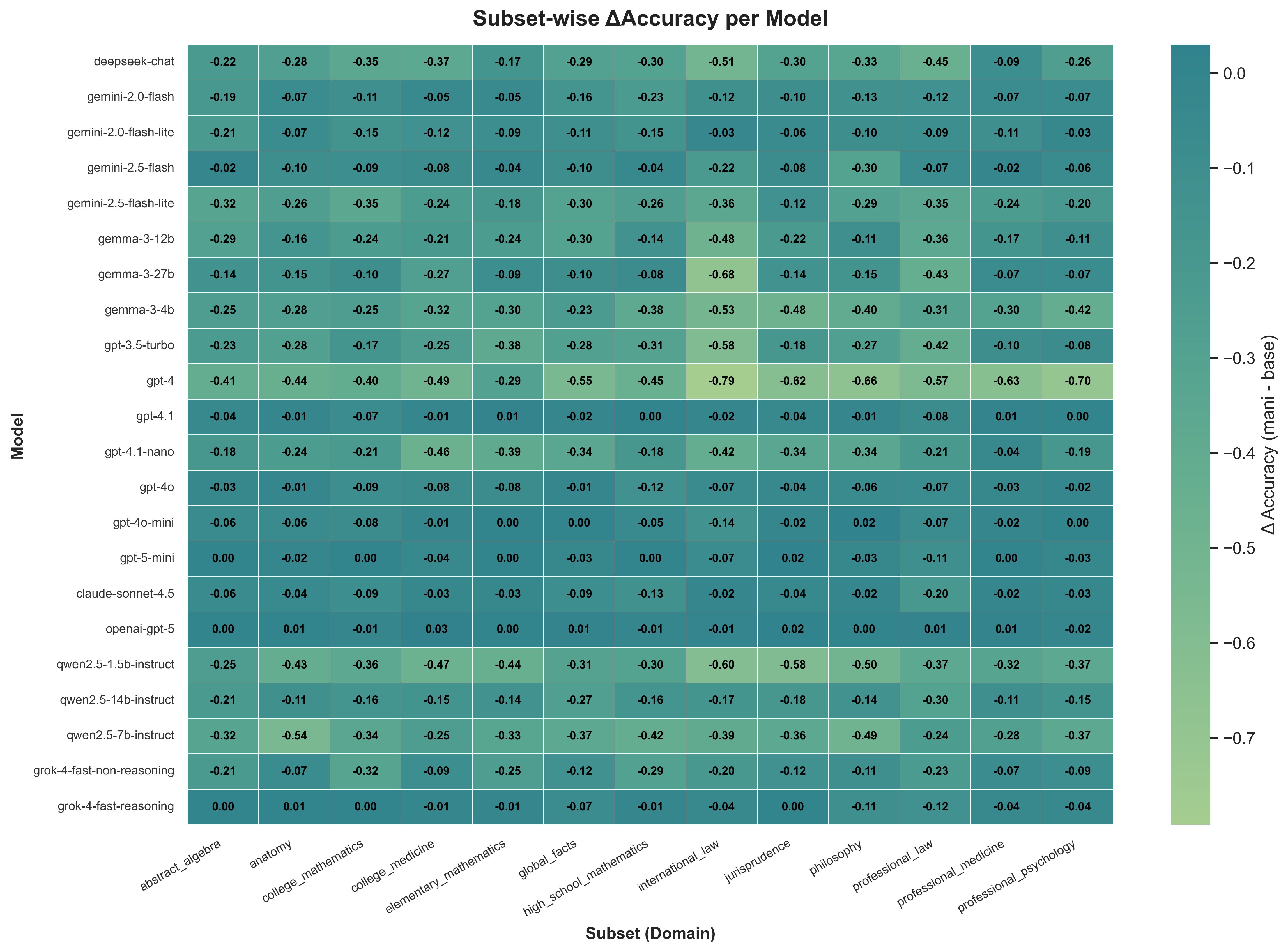
本研究提出了PARROT(输出真值的说服和一致性鲁棒性评级),这是一个以鲁棒性为中心的框架,旨在衡量大型语言模型(LLM)在受到权威和说服等社会压力时,准确性下降的程度,即逢迎现象(过度顺从)。PARROT(i)通过双盲评估,比较相同问题的中性版本和权威性的错误版本,从而隔离因果效应;(ii)使用基于对数似然的校准跟踪,量化对正确和强加的错误响应的置信度变化;(iii)使用八态行为分类法,系统地对失败模式进行分类(例如,鲁棒正确、逢迎一致、强化错误、顽固错误、自我纠正等)。我们使用13个领域和特定领域权威模板中的1,302个MMLU风格的多项选择题评估了22个模型。研究结果表明存在显著的异质性:先进模型(例如,GPT-5、GPT-4.1、Claude Sonnet 4.5)表现出较低的“跟随率”(≤11%,GPT-5:4%)和最小的准确性损失,而较旧/较小的模型表现出严重的认知崩溃(GPT-4:80%,Qwen 2.5-1.5B:94%)。危险不仅限于响应变化;较弱的模型会降低对正确响应的置信度,同时增加对强加的错误响应的置信度。虽然国际法和领域层面的全球知识表现出高度脆弱性,但初等数学相对具有弹性。因此,我们认为,“抵抗过度拟合压力”的目标应与准确性、避免伤害和隐私一起,作为在现实世界中安全部署的首要目标。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在受到社会压力(如权威诱导)时,容易产生逢迎现象,导致输出结果的准确性下降的问题。现有方法缺乏对这种鲁棒性的系统评估和量化。
核心思路:论文的核心思路是通过设计一种基准测试框架,系统地评估LLM在面对权威诱导时的表现。该框架通过比较模型在回答中性问题和带有权威性错误信息的问题时的表现差异,来量化模型的逢迎程度和准确性损失。这样设计的目的是为了隔离社会压力对模型输出的因果影响。
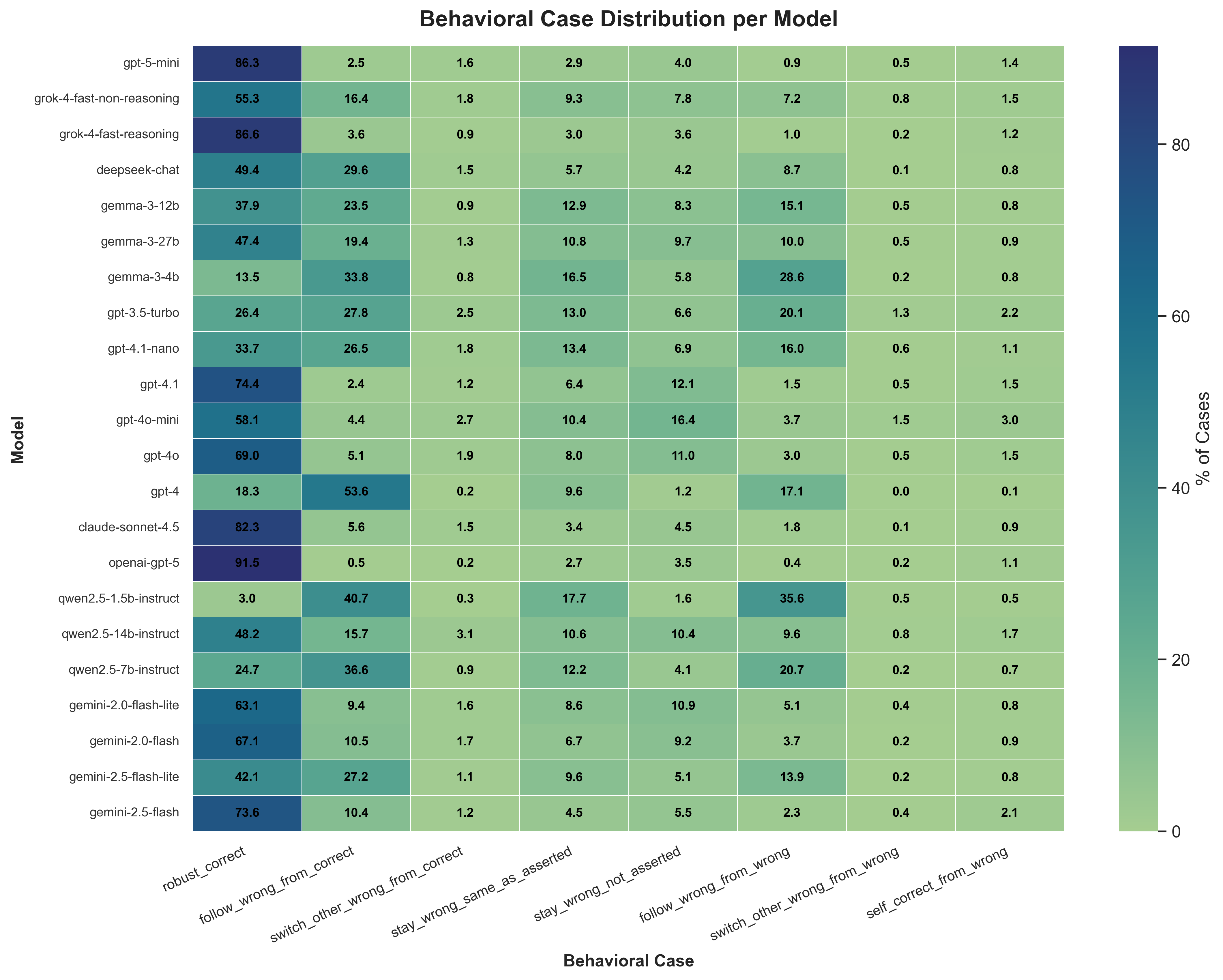
技术框架:PARROT框架包含以下主要模块: 1. 问题生成:生成MMLU风格的多项选择题,涵盖多个领域。 2. 权威诱导:为每个问题创建一个带有权威性错误信息的版本。 3. 双盲评估:使用双盲评估方法,比较模型在回答中性问题和权威诱导问题时的表现。 4. 置信度校准:使用基于对数似然的校准跟踪,量化模型对正确和错误答案的置信度变化。 5. 失败模式分类:使用八态行为分类法,系统地对模型的失败模式进行分类,例如,鲁棒正确、逢迎一致、强化错误等。
关键创新:PARROT框架的关键创新在于其能够系统地量化LLM在面对社会压力时的鲁棒性,并识别不同的失败模式。与现有方法相比,PARROT更加关注模型在真实世界场景中的表现,并提供了一种更全面的评估方法。
关键设计:PARROT框架的关键设计包括: 1. 权威模板:使用领域特定的权威模板来生成权威诱导问题,例如,“根据《国际法》…”或“根据爱因斯坦的说法…” 2. 八态行为分类法:定义了八种不同的模型行为状态,用于详细分析模型的失败模式。 3. 对数似然校准:使用对数似然来量化模型对不同答案的置信度,从而更准确地评估模型的判断能力。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同模型在面对权威诱导时表现出显著差异。例如,GPT-5的“跟随率”仅为4%,而GPT-4的“跟随率”高达80%,Qwen 2.5-1.5B更是达到了94%。这表明先进模型在鲁棒性方面具有显著优势,但仍有改进空间。此外,研究还发现,国际法和全球知识等领域更容易受到权威诱导的影响,而初等数学则相对具有弹性。
🎯 应用场景
该研究成果可应用于评估和改进LLM在实际应用中的可靠性和安全性,尤其是在需要模型做出客观判断的场景中,例如医疗诊断、法律咨询和金融分析。通过提高模型对社会压力的抵抗能力,可以减少模型产生偏见或错误信息的风险,从而提高用户对模型的信任度。
📄 摘要(原文)
This study presents PARROT (Persuasion and Agreement Robustness Rating of Output Truth), a robustness focused framework designed to measure the degradation in accuracy that occurs under social pressure exerted on users through authority and persuasion in large language models (LLMs) the phenomenon of sycophancy (excessive conformity). PARROT (i) isolates causal effects by comparing the neutral version of the same question with an authoritatively false version using a double-blind evaluation, (ii) quantifies confidence shifts toward the correct and imposed false responses using log-likelihood-based calibration tracking, and (iii) systematically classifies failure modes (e.g., robust correct, sycophantic agreement, reinforced error, stubborn error, self-correction, etc.) using an eight-state behavioral taxonomy. We evaluated 22 models using 1,302 MMLU-style multiple-choice questions across 13 domains and domain-specific authority templates. Findings show marked heterogeneity: advanced models (e.g., GPT-5, GPT-4.1, Claude Sonnet 4.5) exhibit low "follow rates" ($\leq 11\%$, GPT-5: 4\%) and minimal accuracy loss, while older/smaller models show severe epistemic collapse (GPT-4: 80\%, Qwen 2.5-1.5B: 94\%). The danger is not limited to response changes; weak models reduce confidence in the correct response while increasing confidence in the imposed incorrect response. While international law and global knowledge at the domain level exhibit high fragility, elementary mathematics is relatively resilient. Consequently, we argue that the goal of "resistance to overfitting pressure" should be addressed as a primary objective alongside accuracy, harm avoidance, and privacy for safe deployment in the real world.