Learning to Compress: Unlocking the Potential of Large Language Models for Text Representation
作者: Yeqin Zhang, Yizheng Zhao, Chen Hu, Binxing Jiao, Daxin Jiang, Ruihang Miao, Cam-Tu Nguyen
分类: cs.CL, cs.AI
发布日期: 2025-11-21 (更新: 2025-12-24)
备注: Accepted by AAAI'26
🔗 代码/项目: GITHUB
💡 一句话要点
提出LLM2Comp,利用上下文压缩预训练提升大语言模型文本表示能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本表示 大型语言模型 上下文压缩 对比学习 预训练 无监督学习
📋 核心要点
- 现有LLM在文本表示方面表现不佳,因为它们主要针对下一个token预测进行优化,缺乏生成整体表示的能力。
- 论文提出利用上下文压缩作为预训练任务,使LLM学习生成紧凑的记忆token,从而更好地捕捉文本的整体语义。
- 实验结果表明,通过上下文压缩预训练的LLM2Comp模型,在文本表示任务上优于其他基于LLM的文本编码器,且更具样本效率。
📝 摘要(中文)
文本表示在聚类、检索等下游任务中至关重要。随着大型语言模型(LLM)的兴起,人们越来越关注如何利用它们进行文本表示。然而,大多数LLM本质上是因果模型,并针对下一个token预测进行了优化,这使得它们在生成整体表示方面表现不佳。为了解决这个问题,最近的研究引入了预训练任务来调整LLM以适应文本表示。然而,这些任务大多依赖于token级别的预测目标,例如LLM2Vec中使用的masked next-token prediction(MNTP)。在这项工作中,我们探索了上下文压缩作为一种预训练任务的潜力,用于无监督地调整LLM。在压缩预训练期间,模型学习生成紧凑的记忆token,这些token替代整个上下文以进行下游序列预测。实验表明,精心设计的压缩目标可以显著增强基于LLM的文本表示,优于使用token级别预训练任务训练的模型。通过对比学习的进一步改进产生了一个强大的表示模型(LLM2Comp),该模型在各种任务上优于当代基于LLM的文本编码器,同时更具样本效率,需要更少的训练数据。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在文本表示任务中表现不佳的问题。现有的LLM通常针对next-token prediction进行优化,导致生成的文本表示缺乏全局语义信息,无法很好地应用于聚类、检索等下游任务。现有方法,如LLM2Vec,依赖于token级别的预测目标,例如masked next-token prediction,这限制了模型捕捉上下文信息的能力。
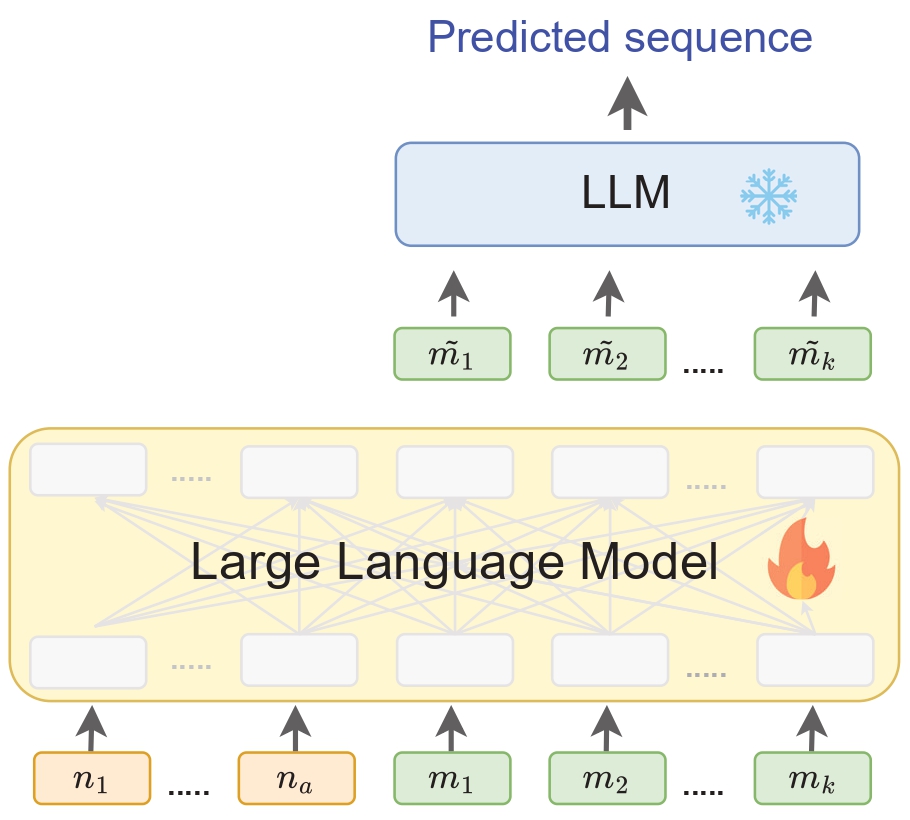
核心思路:论文的核心思路是将上下文压缩作为一种预训练任务,使LLM学习生成能够代表整个上下文的紧凑的记忆token。通过这种方式,模型能够更好地理解和捕捉文本的整体语义,从而生成更有效的文本表示。这种方法避免了token级别的预测,而是关注于学习一种能够概括整个上下文的表示。
技术框架:LLM2Comp的整体框架包括两个主要阶段:压缩预训练和对比学习微调。在压缩预训练阶段,模型学习将输入文本压缩成一个或多个记忆token。在对比学习微调阶段,模型通过对比学习进一步优化文本表示,使其在语义上相似的文本的表示更接近,而语义上不同的文本的表示更远离。
关键创新:论文的关键创新在于将上下文压缩作为一种新的预训练任务,用于提升LLM的文本表示能力。与现有的token级别预测方法不同,上下文压缩能够使模型学习捕捉文本的整体语义信息。此外,论文还结合了对比学习,进一步提升了文本表示的质量。
关键设计:在压缩预训练阶段,论文设计了一个特殊的损失函数,鼓励模型生成能够准确预测下游序列的记忆token。具体来说,模型需要根据记忆token重建原始文本,并最小化重建误差。在对比学习微调阶段,论文使用了InfoNCE损失函数,鼓励模型学习区分语义相似和语义不同的文本。此外,论文还探索了不同的网络结构和参数设置,以优化模型的性能。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LLM2Comp在多个文本表示任务上优于现有的基于LLM的文本编码器,例如LLM2Vec。具体来说,LLM2Comp在文本聚类任务上取得了显著的提升,并且在信息检索任务上也表现出色。此外,LLM2Comp还具有更高的样本效率,只需要更少的训练数据就能达到 comparable 的性能。
🎯 应用场景
该研究成果可广泛应用于各种需要文本表示的场景,例如:文本聚类、信息检索、语义相似度计算、文本分类等。通过提升LLM的文本表示能力,可以提高这些应用的效果和效率。此外,该方法还可以应用于其他自然语言处理任务,例如:文本摘要、机器翻译等,具有广泛的应用前景和实际价值。
📄 摘要(原文)
Text representation plays a critical role in tasks like clustering, retrieval, and other downstream applications. With the emergence of large language models (LLMs), there is increasing interest in harnessing their capabilities for this purpose. However, most of the LLMs are inherently causal and optimized for next-token prediction, making them suboptimal for producing holistic representations. To address this, recent studies introduced pretext tasks to adapt LLMs for text representation. Most of these tasks, however, rely on token-level prediction objectives, such as the masked next-token prediction (MNTP) used in LLM2Vec. In this work, we explore the untapped potential of context compression as a pretext task for unsupervised adaptation of LLMs. During compression pre-training, the model learns to generate compact memory tokens, which substitute the whole context for downstream sequence prediction. Experiments demonstrate that a well-designed compression objective can significantly enhance LLM-based text representations, outperforming models trained with token-level pretext tasks. Further improvements through contrastive learning produce a strong representation model (LLM2Comp) that outperforms contemporary LLM-based text encoders on a wide range of tasks while being more sample-efficient, requiring significantly less training data. Code is available at https://github.com/longtaizi13579/LLM2Comp.