Training Foundation Models on a Full-Stack AMD Platform: Compute, Networking, and System Design
作者: Quentin Anthony, Yury Tokpanov, Skyler Szot, Srivatsan Rajagopal, Praneeth Medepalli, Anna Golubeva, Vasu Shyam, Robert Washbourne, Rishi Iyer, Ansh Chaurasia, Tomas Figliolia, Xiao Yang, Abhinav Sarje, Drew Thorstensen, Amartey Pearson, Zack Grossbart, Jason van Patten, Emad Barsoum, Zhenyu Gu, Yao Fu, Beren Millidge
分类: cs.CL, cs.AI, cs.DC
发布日期: 2025-11-21 (更新: 2025-12-03)
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
在全栈AMD平台上训练基础模型,优化计算、网络和系统设计。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模预训练 混合专家模型 AMD MI300X Pollara网络 Transformer优化
📋 核心要点
- 现有大规模模型训练依赖特定硬件,缺乏在AMD平台上进行全面优化的研究,限制了硬件多样性和可选择性。
- 论文提出MI300X感知的Transformer大小调整规则,并优化MoE宽度,以提升训练吞吐量和推理效率,充分利用AMD硬件特性。
- 实验结果表明,基于AMD平台的ZAYA1模型在推理、数学和编码任务上,性能可与领先模型媲美甚至超越,验证了AMD平台的竞争力。
📝 摘要(中文)
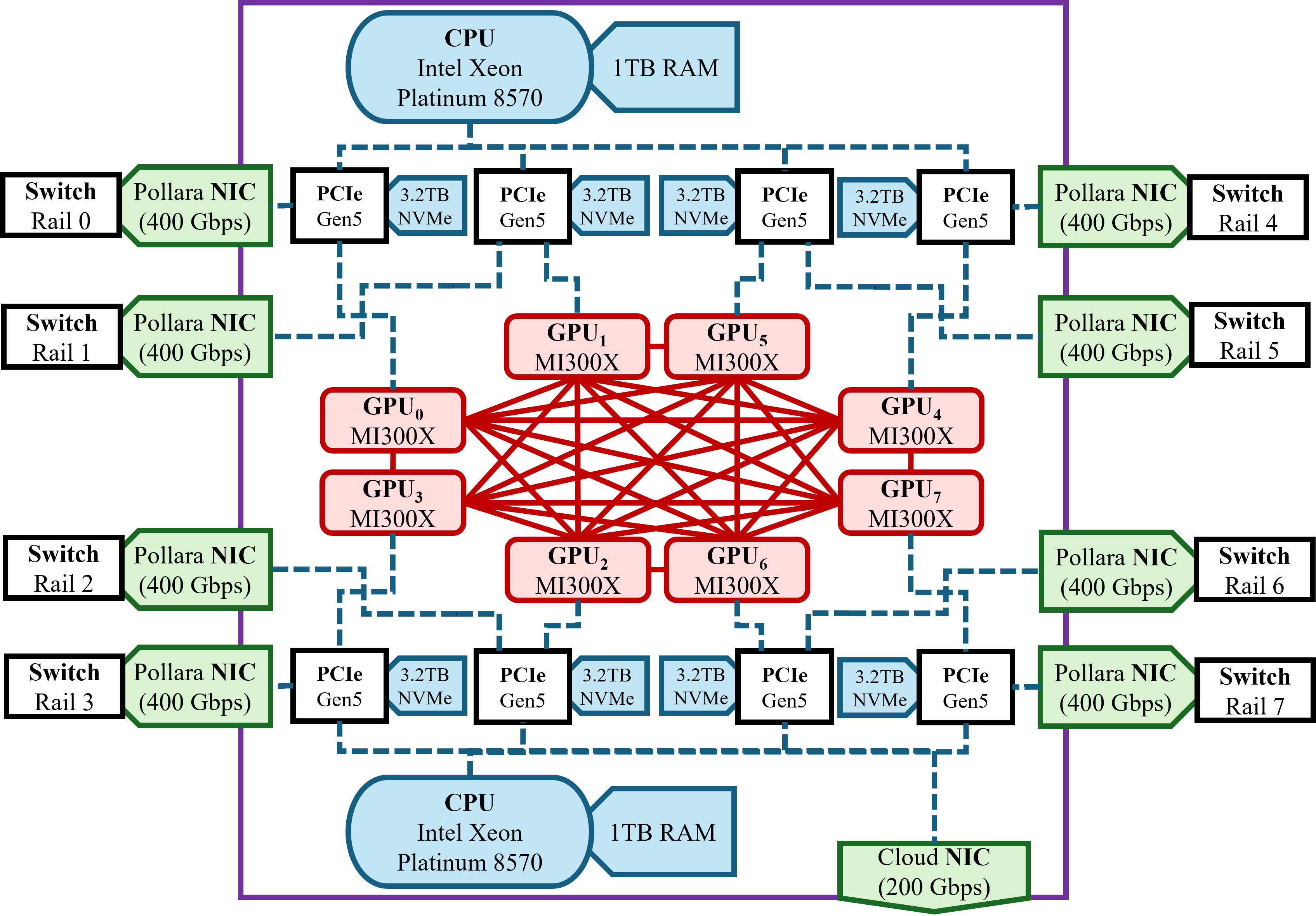
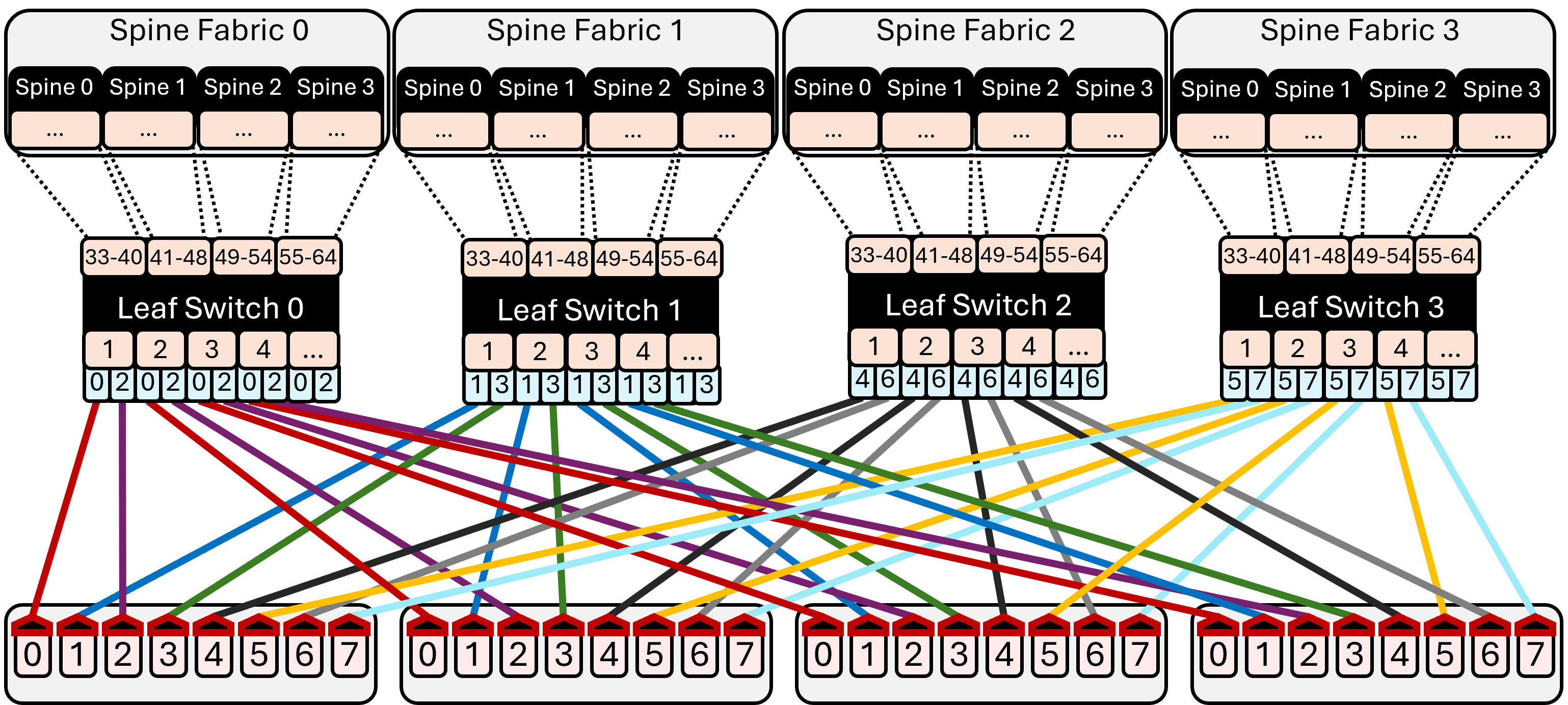
本文报告了首次在纯AMD硬件上进行的大规模混合专家(MoE)预训练研究,利用了MI300X GPU和Pollara网络。我们提炼了系统和模型设计的实践指导。在系统方面,我们提供了全面的集群和网络特性分析:Pollara上各种消息大小和GPU数量的核心集合通信(all-reduce、reduce-scatter、all-gather、broadcast)的微基准测试。据我们所知,这是首次达到这种规模。我们进一步提供了MI300X上关于内核大小和内存带宽的微基准测试,以指导模型设计。在建模方面,我们引入并应用了MI300X感知的Transformer大小调整规则,用于注意力机制和MLP块,并证明了MoE宽度的合理性,从而共同优化训练吞吐量和推理延迟。我们深入描述了我们的训练堆栈,包括容错和检查点重塑等经常被忽略的实用程序,以及关于训练配方的详细信息。我们还提供了模型架构和基础模型ZAYA1(7.6亿激活参数,83亿总参数MoE,可在https://huggingface.co/Zyphra/ZAYA1-base获取)的预览,该模型将在后续论文中得到进一步改进。ZAYA1-base在其规模和更大规模上实现了与Qwen3-4B和Gemma3-12B等领先基础模型相当的性能,并在推理、数学和编码基准测试中优于包括Llama-3-8B和OLMoE在内的模型。总之,这些结果表明AMD硬件、网络和软件堆栈已经足够成熟和优化,可以进行有竞争力的大规模预训练。
🔬 方法详解
问题定义:论文旨在解决在大规模预训练中,如何充分利用AMD MI300X GPU和Pollara网络,实现高效的模型训练和推理的问题。现有方法通常针对NVIDIA硬件进行优化,无法直接迁移到AMD平台,导致性能瓶颈和资源浪费。
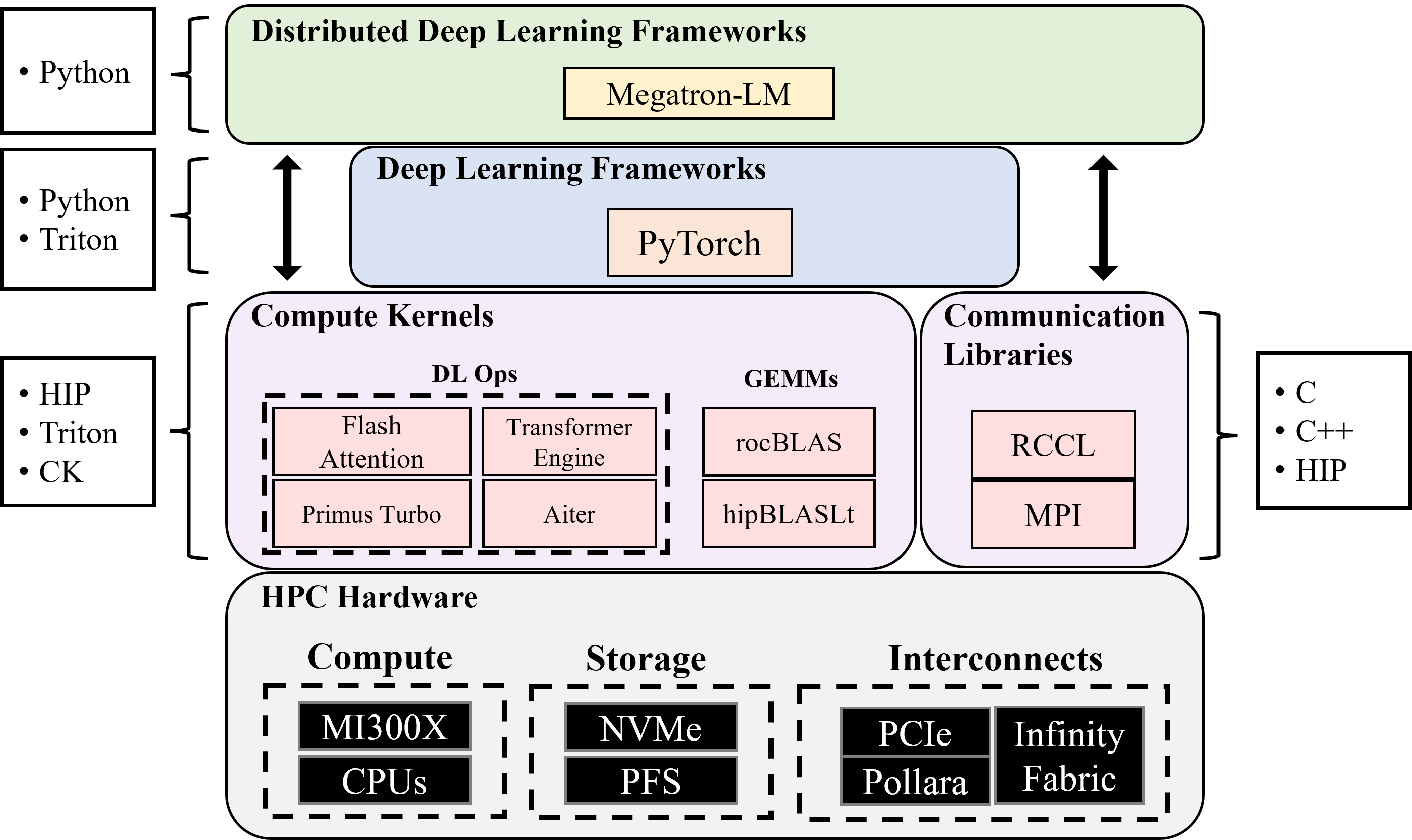
核心思路:论文的核心思路是进行全栈优化,从硬件特性出发,设计MI300X感知的模型架构和训练策略。通过微基准测试深入了解硬件性能,并根据测试结果调整模型参数,实现软硬件协同优化。
技术框架:论文的技术框架包括以下几个主要部分:1) 硬件特性分析:对MI300X GPU和Pollara网络进行微基准测试,评估计算能力、内存带宽和网络通信性能。2) 模型架构设计:基于Transformer架构,引入混合专家(MoE)机制,并根据MI300X的硬件特性调整注意力机制和MLP块的大小。3) 训练策略优化:设计高效的训练配方,包括数据并行、模型并行和流水线并行等技术,并优化容错和检查点机制。4) 模型评估:在推理、数学和编码等基准测试中评估模型的性能,并与现有模型进行比较。
关键创新:论文的关键创新在于提出了MI300X感知的Transformer大小调整规则,并优化了MoE宽度。这些规则充分考虑了MI300X的计算能力和内存带宽,从而实现了更高的训练吞吐量和推理效率。与现有方法相比,该方法能够更好地利用AMD硬件的特性,从而获得更好的性能。
关键设计:论文的关键设计包括:1) 注意力机制和MLP块的大小调整:根据MI300X的内存带宽和计算能力,调整注意力机制和MLP块的大小,以避免内存瓶颈和计算瓶颈。2) MoE宽度优化:根据MI300X的通信能力,优化MoE宽度,以平衡训练吞吐量和推理延迟。3) 训练配方优化:采用数据并行、模型并行和流水线并行等技术,并优化容错和检查点机制,以提高训练效率和稳定性。
🖼️ 关键图片
📊 实验亮点
ZAYA1-base模型在AMD MI300X平台上训练,参数量为7.6亿激活参数和83亿总参数。实验结果表明,ZAYA1-base在推理、数学和编码基准测试中,性能与Qwen3-4B和Gemma3-12B等领先模型相当,甚至优于Llama-3-8B和OLMoE等模型,验证了AMD平台的竞争力。
🎯 应用场景
该研究成果可应用于各种需要大规模预训练的领域,如自然语言处理、计算机视觉和语音识别。通过在AMD平台上进行高效的模型训练,可以降低训练成本,加速模型迭代,并促进人工智能技术的普及。此外,该研究还为其他硬件平台上的模型训练提供了借鉴意义。
📄 摘要(原文)
We report on the first large-scale mixture-of-experts (MoE) pretraining study on pure AMD hardware, utilizing both MI300X GPUs and Pollara networking. We distill practical guidance for both systems and model design. On the systems side, we deliver a comprehensive cluster and networking characterization: microbenchmarks for all core collectives (all-reduce, reduce-scatter, all-gather, broadcast) across message sizes and GPU counts over Pollara. To our knowledge, this is the first at this scale. We further provide MI300X microbenchmarks on kernel sizing and memory bandwidth to inform model design. On the modeling side, we introduce and apply MI300X-aware transformer sizing rules for attention and MLP blocks and justify MoE widths that jointly optimize training throughput and inference latency. We describe our training stack in depth, including often-ignored utilities such as fault-tolerance and checkpoint-reshaping, as well as detailed information on our training recipe. We also provide a preview of our model architecture and base model - ZAYA1 (760M active, 8.3B total parameters MoE, available at https://huggingface.co/Zyphra/ZAYA1-base) - which will be further improved upon in forthcoming papers. ZAYA1-base achieves performance comparable to leading base models such as Qwen3-4B and Gemma3-12B at its scale and larger, and outperforms models including Llama-3-8B and OLMoE across reasoning, mathematics, and coding benchmarks. Together, these results demonstrate that the AMD hardware, network, and software stack are mature and optimized enough for competitive large-scale pretraining.