MUCH: A Multilingual Claim Hallucination Benchmark
作者: Jérémie Dentan, Alexi Canesse, Davide Buscaldi, Aymen Shabou, Sonia Vanier
分类: cs.CL
发布日期: 2025-11-21
💡 一句话要点
提出多语言声明幻觉基准MUCH,用于评估和提升LLM的声明级不确定性量化。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 声明级不确定性量化 大型语言模型 多语言基准 幻觉检测 自然语言处理
📋 核心要点
- 大型语言模型缺乏可靠性,声明级不确定性量化是缓解该问题的有效途径,但缺乏合适的评估基准。
- MUCH基准通过提供多语言数据、token logits和高效的声明分割算法,为声明级不确定性量化方法提供了公平的评估平台。
- 实验结果表明,现有方法在MUCH基准上仍有很大的改进空间,为未来的研究指明了方向。
📝 摘要(中文)
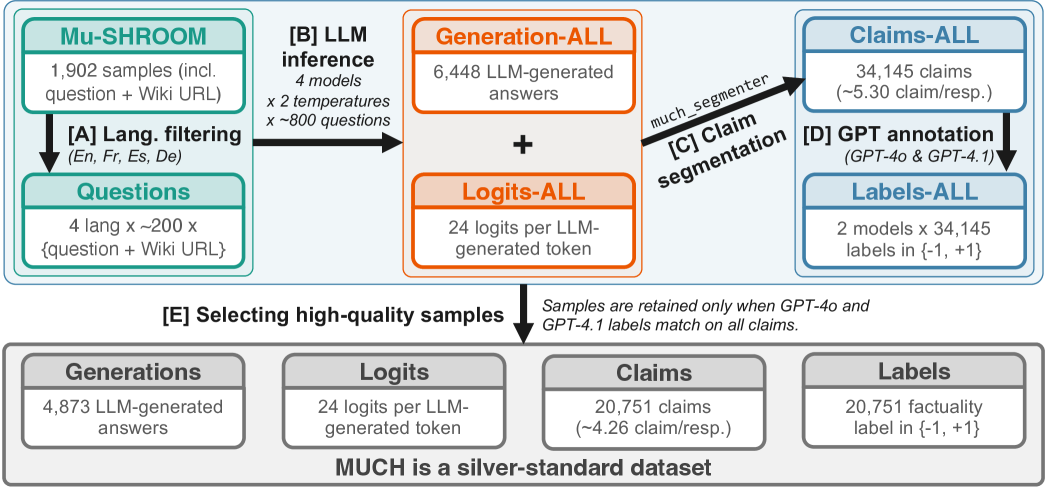
本文提出了MUCH,这是一个首个声明级别的Uncertainty Quantification (UQ) 基准,旨在公平且可复现地评估未来方法在真实条件下的性能,从而缓解大型语言模型(LLMs)可靠性不足的问题。MUCH包含四种欧洲语言(英语、法语、西班牙语和德语)的4873个样本,以及四个指令微调的开源LLM。与之前的声明级基准不同,MUCH发布了每个token的24个生成logits,方便未来白盒方法的研究,无需重新生成数据。此外,本文提出了一种新的确定性算法,仅需LLM生成时间的0.2%即可分割声明,适用于LLM输出的实时监控。评估结果表明,当前方法在性能和效率方面仍有很大的提升空间。
🔬 方法详解
问题定义:大型语言模型(LLMs)在生成文本时可能产生不准确或虚假的声明,即“幻觉”。声明级不确定性量化(UQ)旨在评估LLM生成声明的可信度,但缺乏在真实场景下公平评估UQ方法的基准。现有基准通常依赖人工或基于LLM的分割方法,效率较低,难以应用于实时监控。
核心思路:MUCH基准的核心思路是提供一个多语言、包含token logits、并具有高效声明分割算法的平台,以便研究人员能够开发和评估声明级UQ方法。通过提供token logits,MUCH支持白盒方法的开发,避免了重复生成数据的需求。高效的声明分割算法使得MUCH能够模拟真实部署场景。
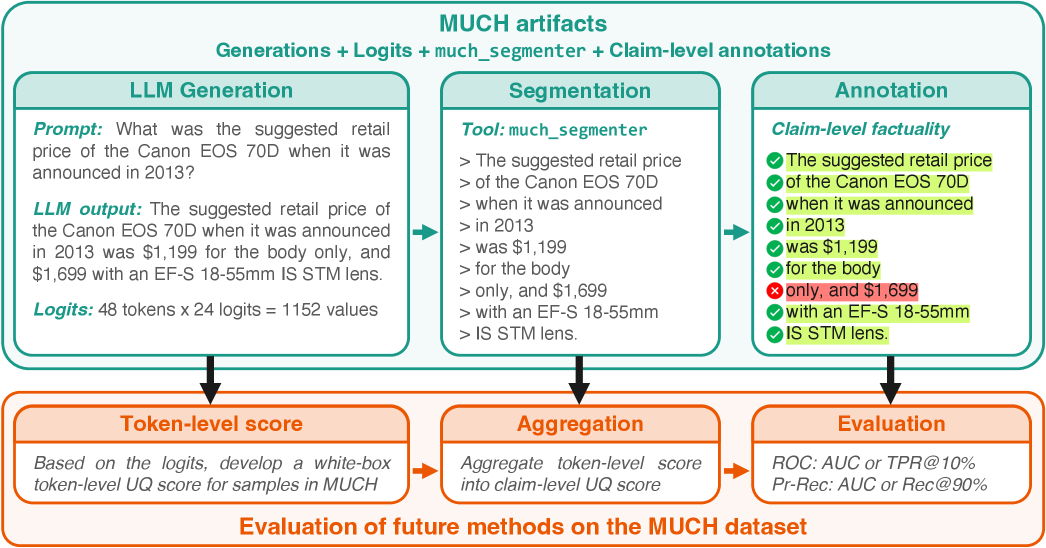
技术框架:MUCH基准的构建流程主要包含以下几个阶段:数据收集,包括从多个来源收集多语言文本数据;声明标注,对文本数据进行声明级别的标注;LLM生成,使用多个开源LLM生成文本;Logits提取,提取每个token的生成logits;声明分割,使用提出的确定性算法分割声明;基准评估,使用MUCH基准评估现有UQ方法的性能。
关键创新:MUCH基准的关键创新在于:1) 它是首个多语言声明级UQ基准;2) 它提供了每个token的24个生成logits,方便白盒方法的研究;3) 它提出了一种新的确定性声明分割算法,效率远高于现有方法,适用于实时监控。
关键设计:MUCH基准的关键设计包括:1) 选择了四种欧洲语言(英语、法语、西班牙语和德语),以增加基准的多样性;2) 选择了四个指令微调的开源LLM,以保证基准的可访问性;3) 提出的确定性声明分割算法基于文本相似度计算,通过设置合适的阈值来实现高效分割。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
MUCH基准的实验结果表明,现有声明级不确定性量化方法在多语言环境下的性能仍有很大的提升空间。具体性能数据未知,但论文强调了现有方法在性能和效率方面均存在不足,为未来的研究提供了明确的方向。
🎯 应用场景
MUCH基准的潜在应用领域包括:LLM输出的实时监控、虚假信息检测、自动新闻验证等。通过提高LLM的可靠性,MUCH有助于构建更值得信赖的人工智能系统,并减少LLM在信息传播中可能造成的负面影响。未来,MUCH可以扩展到更多语言和领域,以适应不断发展的LLM技术。
📄 摘要(原文)
Claim-level Uncertainty Quantification (UQ) is a promising approach to mitigate the lack of reliability in Large Language Models (LLMs). We introduce MUCH, the first claim-level UQ benchmark designed for fair and reproducible evaluation of future methods under realistic conditions. It includes 4,873 samples across four European languages (English, French, Spanish, and German) and four instruction-tuned open-weight LLMs. Unlike prior claim-level benchmarks, we release 24 generation logits per token, facilitating the development of future white-box methods without re-generating data. Moreover, in contrast to previous benchmarks that rely on manual or LLM-based segmentation, we propose a new deterministic algorithm capable of segmenting claims using as little as 0.2% of the LLM generation time. This makes our segmentation approach suitable for real-time monitoring of LLM outputs, ensuring that MUCH evaluates UQ methods under realistic deployment constraints. Finally, our evaluations show that current methods still have substantial room for improvement in both performance and efficiency.